We are all susceptible to using bad mathematics to get us where we want to go. Here is an example.
I recently came across the 2014 paper in the title of this post. I mentioned it briefly in the post on the periodogram. But I’m going to talk about it a bit more here because this is the kind of thing that makes things harder for people trying to learn about cyclostationarity, which eventually leads to the need for something like the CSP Blog as a corrective.
The idea behind the paper is that it would be nice to avoid the need for prior knowledge of cycle frequencies when using cycle detectors or the like. If you could just compute the entire spectral correlation function, then collapse it by integrating (summing) over frequency  , then you’d have a one-dimensional function of cycle frequency
, then you’d have a one-dimensional function of cycle frequency  and you could then process that function inexpensively to perform detection and classification tasks.
and you could then process that function inexpensively to perform detection and classification tasks.
The author sets up an expression for one of the terms of the incoherent suboptimal multicycle detector, which has an idealized counterpart that is equal to the sum (integral) of the magnitude-squared spectral correlation function. Something like this:

The author then tries to simplify this kind of expression, and that is where things start to go very wrong. The root of it all is the author’s equation (3),
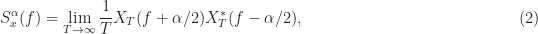
where 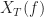 is the Fourier transform of the given data
is the Fourier transform of the given data 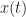 restricted to a time interval centered at
restricted to a time interval centered at  and having width
and having width  . In other words, the author starts off by stating that the spectral correlation function is the limit of the cyclic periodogram as the amount of data increases without bound. This is exactly what we show is not true in the periodogram post. The limit does not exist. And the result is well-known for the degenerate case of conventional spectral analysis when we look at the non-conjugate spectral correlation function with cycle frequency equal to zero.
. In other words, the author starts off by stating that the spectral correlation function is the limit of the cyclic periodogram as the amount of data increases without bound. This is exactly what we show is not true in the periodogram post. The limit does not exist. And the result is well-known for the degenerate case of conventional spectral analysis when we look at the non-conjugate spectral correlation function with cycle frequency equal to zero.
The (idealized) multi-cycle detection statistic of interest to the author is

This can be re-expressed as

The author then tries to convert the sum over cycle frequency into an integral, but does not use impulse functions to do so, ending up with



But we know that the spectral correlation function 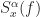 is continuous in spectral frequency and discrete in cycle frequency . In many cases of practical interest, there are only a finite number of cycle frequencies for which the spectral correlation function is not identically zero (think of square-root raised-cosine PSK, QAM, PAM), so that in (6) the integral over cycle frequency is zero. In other cases, the number of cycle frequencies is infinite, but countable (think rectangular-pulse BPSK), which still leads to a zero-valued integral over cycle frequency. In general, the spectral correlation function is non-zero only on a set of measure zero in the bi-frequency
is continuous in spectral frequency and discrete in cycle frequency . In many cases of practical interest, there are only a finite number of cycle frequencies for which the spectral correlation function is not identically zero (think of square-root raised-cosine PSK, QAM, PAM), so that in (6) the integral over cycle frequency is zero. In other cases, the number of cycle frequencies is infinite, but countable (think rectangular-pulse BPSK), which still leads to a zero-valued integral over cycle frequency. In general, the spectral correlation function is non-zero only on a set of measure zero in the bi-frequency 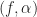 plane, and so such integrals as the author writes in (6) above are always zero. So (6) is a mistaken representation of the desired quantity.
plane, and so such integrals as the author writes in (6) above are always zero. So (6) is a mistaken representation of the desired quantity.
A double-integral representation of 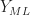 is possible by using impulse functions (Dirac delta functions).
is possible by using impulse functions (Dirac delta functions).
Then the author tries to substitute (2) above into (4), which is a mistake because (2) is not true, but she also does it incorrectly. In particular, she writes
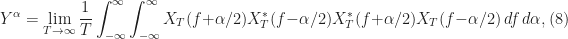
which she then simplifies to

by using a change of variables for . But this is an incorrect substitution. The author’s (3) (my (2) above) must be substituted for each appearing in the expression, leading to two limits (over two time variables  and
and 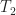 ). In other words, she should have ended up with a double limit.
). In other words, she should have ended up with a double limit.
In reality, each spectral correlation function is itself correctly represented by a double limit involving the data observation interval length and a smoothing or averaging parameter. In the case of the frequency-smoothing method, it is the width of the smoothing function  . So, we would end up with four limits in (9) if we did things properly.
. So, we would end up with four limits in (9) if we did things properly.
But the problems continue. The author then defines 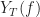 as the (scaled) periodogram,
as the (scaled) periodogram,

She ends up with

(the conjugation is superfluous since is non-negative).
So the quantity 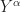 , which was defined as the integral of the squares of all non-zero spectral correlation functions, is now reduced (incorrectly!) to the convolution of the periodogram with itself. All the cyclostationarity of the signal–no matter how rich or how poor–can be extracted by computing only the periodogram!
, which was defined as the integral of the squares of all non-zero spectral correlation functions, is now reduced (incorrectly!) to the convolution of the periodogram with itself. All the cyclostationarity of the signal–no matter how rich or how poor–can be extracted by computing only the periodogram!
There are lots of other problems with the paper, including in the simulations section, but they don’t really matter because the theoretical development is seriously mathematically flawed. And most of the problem arises from trying to take the limit of the cyclic periodogram.
Comments and corrections are welcome!
Author: Chad Spooner
I'm a signal processing researcher specializing in cyclostationary signal processing (CSP) for communication signals. I hope to use this blog to help others with their cyclo-projects and to learn more about how CSP is being used and extended worldwide.
View all posts by Chad Spooner

I remember being super excited when I found this paper a year or so ago. I couldn’t follow most of the assumptions/maths behind it, but I attributed that to my poor understanding of cyclostationarity. Glad to see it it wasn’t entirely my fault.
Your comment validates my effort to review the paper and write the post! Thanks so much for taking the time to post it. I’ll have more to say about Professor Jang’s efforts on cyclostationary signal processing soon.
Let me know if there are other technical papers for which you had a similar experience. I’ll take a look and post if warranted.