
Update March 2021
See my analyses of three other DeepSig datasets here, here, and here.
Update June 2020
I’ll be adding new papers to this post as I find them. At the end of the original post there is a sequence of date-labeled updates that briefly describe the relevant aspects of the newly found papers. Some machine-learning modulation-recognition papers deserve their own post, so check back at the CSP Blog from time-to-time for “Comments On …” posts.
This is another post about machine learning (ML) and modulation recognition (MR). Previously we looked at the basic idea of MR and why it is a difficult signal-processing problem to solve. We also looked at several papers in the engineering literature that apply neural-network-based ML processing to the MR problem. Finally, I posted a large simulated communication-signal dataset to the CSP Blog as a challenge to the Machine Learners, together with a corresponding set of processing results I obtained by applying non-machine-learning CSP-based MR and parameter-estimation algorithms to the posted dataset.
In this post, I want to point out the kinds of datasets that are used in various modulation-recognition ML papers and ask questions about their fidelity, appropriateness, and utility. I’ve been especially puzzled to read the common refrain about how ML algorithms produce performance better than “conventional methods.” Rarely are these conventional methods described in any detail, and when details are provided they are garbled or insufficient. What is most curious, though, is that the training and testing datasets used in the ML MR papers are narrow in scope, yet conventional methods of MR are often not narrow in scope. If the ML MR algorithm is trained and tested on a set of modulated signals all having symbol rate 
So I think there is a sort of gap between what the Machine Learners think of as modulation recognition and what the “conventional” researchers and practitioners mean. When I say I can recognize a BPSK signal, I mean I can recognize all BPSK signals.
‘All BPSK signals’ is a bit of an exaggeration. There are many pathological cases, such as a BPSK signal with symbol rate so low that it would take days to collect even a couple symbols. In general, I mean all BPSK signals that can fit within my receiver bandwidth and for which I can capture many symbols worth of data in a reasonable time–all practical BPSK signals.
What I am getting at is the idea that the particular values of the symbol rate, carrier offset, power, and pulse shaping aren’t terribly important. Yes, if the power is made small enough, we won’t be able to detect or recognize the signal, nor estimate any of its parameters. Yes, if the carrier offset is too large, the signal will be distorted by the receiver filter. Yes, if the symbol rate is too large, the signal will not be fully captured by the receiver. What’s important is the inherent structure of the BPSK signal that supplies its “BPSK-ness” which is what allows us to distinguish it from all other signals.
But even with those caveats, ‘all BPSK signals’ is an awful lot of signals. Just consider all BPSK signals with a fixed carrier frequency offset, fixed pulse function, symbol rate that is any real number in the interval ![[5000, 5000000]](https://s0.wp.com/latex.php?latex=%5B5000%2C+5000000%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
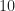
The power of a probabilistic approach to recognizing BPSK signals (My Papers [25, 26, 28, 38, 43, 44]) is that their probabilistic parameters (moments, cumulants, probability density functions [PDFs], etc.) all exhibit the same pattern. So if you can recognize the probability pattern, you can recognize the signal type, and thereby recognize all BPSK signals. The probability structure of the BPSK random process is what provides the distinguishing characteristic of BPSK-ness. It would be cool if a neural network could learn the probability structure from sampled data using training. Can a machine learn the BPSK PDF?
For clarity, and fun, here is a video that shows blind estimation of the cycle frequencies for 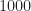

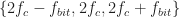
Signals Used in Machine-Learning Modulation-Recognition Papers
Let’s look at the scope of signals that the Machine Learners have been using in their papers.
[R138] Convolutional Radio Modulation Recognition Networks (O’Shea et al)
Let’s start with [R138] because all the other papers I consider here cite it. (See also my original criticism of this paper.)
The dataset at issue is associated with O’Shea and his company, DeepSig, and you can get the dataset by following a link found on DeepSig’s website:

The question at hand is what are the signals and signal-parameters involved with RML2016.10a.tar.bz2? I believe this is the dataset most often used by the papers cited later in this post. How many BPSK signals are in there?
In the authors’ various papers (The Literature [R100, R137, R138, R139, R140]), they mention that the digital signals have “roughly” eight samples per symbol, which means a symbol rate of “roughly” 
The signals samples are stored compactly in a pickle file, which can be read most conveniently using python. Here is the python program I wrote to extract the signals from the archive so that I could take a look at them:
import numpy as np
import pickle
import cPickle
import sys
import cmath
Xd = cPickle.load(open(“RML2016.10a_dict.pkl”,’rb’))
snrs,mods = map(lambda j: sorted(list(set(map(lambda x: x[j], Xd.keys())))), [1,0])
for mod in mods:
print “Modulation Type “, mod
for snr in snrs:
print ” SNR “, snr
X = Xd[(mod,snr)]
print ” Number of files “, X.shape[0]
# for ind in range(X.shape[0]):
for ind in range(100):
# print ” File “, ind
Y = X[ind]
Z = np.zeros((1, Y.shape[1]),dtype=complex)
for c in range(Y.shape[1]):
Z[0, c] = complex(Y[0, c], Y[1, c])
# print np.abs(Z[0,c]), Y[0, c], Y[1, c]
# Create a filename string from the mod type and the SNR.
fn = ‘rml_’ + mod + ‘_’ + str(snr) + ‘_’ + str(ind) + ‘.tim’
# print(fn)
# Open a file for writing using the created string
fn_fid = open (fn, “w”)
# Write the data in ASCII CMS format.dummy = str(2) + ‘\n’
fn_fid.write(dummy)
dummy = str(Y.shape[1]) + ‘\n’
fn_fid.write(dummy)
for c in range(Y.shape[1]):
dummy = str(Z[0, c].real) + ‘ ‘
fn_fid.write(dummy)
dummy = str(Z[0, c].imag) + ‘\n’
fn_fid.write(dummy)
# Close the file.
fn_fid.close()
I just extracted the first 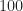

with eleven signal types and a constant signal power of unity (

so that SNR is modified by varying the noise power. The authors offer up some time- and frequency-domain views of one example for each of the eleven types using these tiny unit-less graphs:

I’ve remarked on the strangeness of these plots elsewhere, so here we’ll just take our own look at the data. To aid us mathematically, the authors provide the following signal model:

Equation (4) in R138 is inscrutable, but at least we learn that only one value of excess bandwidth is chosen (

Here is a plot of the 

The occupied bandwith (say, the 
There are two strange things, though, about these BPSK PSD traces. The first is the noise floor. For many of the PSD traces, the out-of-band energy has a very smooth appearance, implying there is no added noise. These are the traces with values above about 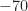
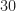
The second thing is the existence of traces that don’t appear to conform to the stated signal model. You can see a couple signals result in PSDs that are both wider and taller than nominal. Moreover, they have a smooth bimodal appearance. I can see how the application of randomized channels might cause a boost in power, but not an increase in bandwidth. The SRRC signal has very little out-of-band energy to boost (mathematically zero).
For several of the SNR parameters, some of the PSD traces do not appear to be related to a BPSK signal. For example, here are the BPSK PSDs for the SNR parameter of 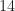

I can’t grasp how the SNR parameter is causing the SNR to change. Here are four of the BPSK sequence, corresponding to SNR parameters 
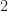




Going from SNR parameter 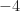
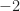
Here are videos for each of the eleven signals, showing
The QAM and PSK signal types all have the same basic PSD, and that PSD is consistent with a single stated symbol rate (‘roughly’
A couple other things are worth mentioning about this data set.
64-QAM. For 64-QAM, one of the SNR parameters results in what looks like two different noise-floor values:

You’ll see from the 64-QAM movie above that this dual-noise-floor behavior doesn’t happen for the other values of the SNR parameter in the pickle file, at least for the samples I extracted and used to create the videos. But also see my analysis of the other DeepSig datasets (2016b and 2018), where this phenomenon is observed more frequently.
AM-DSB. For AM-DSB, the signal is essentially a sine wave. Double-sideband AM can be “suppressed carrier” or “transmitted carrier”, the former possessing no finite-strength sine-wave components, the latter possessing one with frequency equal to the carrier frequency and power level set by the AM modulation index (so in the world there is a family of AM-DSB-TC signals indexed by the modulation-index parameter). Here is an example AM-DSB PSD from the RML dataset that shows the presence of a tone and little else:

The tone appears rectangular in the PSD estimate because I’m using the FSM with a rectangular smoothing window.
AM-SSB. There does not appear to be any signal component for any SNR parameter. Here is the graph for the largest SNR parameter of

WBFM. The wideband FM signal type appears to be very narrowband, little more than a sine-wave in noise:

CPFSK. There are many variants of CPFSK (My Papers [8]), involving different choices for the modulation index, the alphabet size for the pulse-amplitude-modulated (PAM) signal that drives the sinusoid’s phase, and the pulse function for that PAM signal-whether it is partial-response or full-response. A common choice is for a modulation index of 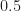

although not all the traces show evidence of the sidelobes. The CPFSK signal here illustrates the strange behavior of the SNR parameter (see CPFSK movie above): For SNR parameters of 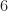
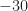
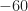
R138 Conclusion
I can’t be completely sure at this time that I’ve extracted the various 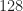
If you train your machine using this dataset, you’ll have attempted to teach it to recognize one BPSK signal.
[R133] Automatic Modulation Classification of Cochannel Signals Using Deep Learning (Sun et al)
This paper tackles the problem of jointly recognizing each of two signals that share the same frequency band and overlap in time as well: the cochannel-signal case (see also My Papers [25,26,28]). Here is the stated signal model:

which is a great start. Note that the two PSK/QAM signals can have different power levels (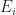
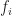




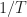
Later, after all the neural-network description stuff, the signals used in the simulation are elaborated upon:

Note that there is no mention of the values of the two parameters 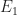
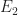

So we have to assume that the ratio 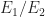
Most importantly for our topic of all BPSK signals, ‘the baud rate of the signal is set to 40,000.’ Presumably this means that each of the two interfering signals has the same symbol rate of 
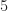
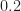
I don’t understand (failure of my impoverished imagination?) the physical setup that would lead to these parameter choices–especially the identical power levels. The range of possible inputs to the MR system is highly circumscribed–there is a lot of prior information to use in the creation of a non-ML algorithm, but there is no comparison to a non-ML algorithm in the paper.
So here, in R133, we have one BPSK signal.
[R134] Modulated Autocorrelation Convolution Networks for Automatic Modulation Classification Based on Small Sample Set (Zhang et al)
This next ML-MR paper also features a single BPSK signal, but also makes clear that the authors’ don’t know much about communication signals or signal theory, but aren’t afraid to let us know that.

“cycle-stationary moments” are used for signals with periodic components–you won’t find that assertion on the CSP Blog. Most MR work is focused on signals that don’t have periodic components, which includes most communication signals.

Where is this superior performance documented? I wonder about the “periodic representation of communication signals.”

Gibberish.

Equation R134 (11) is not going to enlighten anyone: the left side is a function of some index 


So, once again, a single symbol rate is used (


I can’t imagine how the FSK signals work with (11).


I couldn’t find a definition of 



I’m declaring that there is one BPSK signal here.
[R135] End-to-End Learning from Spectrum Data: A Deep Learning Approach for Wireless Signal Identification in Spectrum Monitoring Applications (Kulin et al)
We first encountered Kulin et al in the ML post relating to trying to teach a machine the Fourier transform. The authors use the RML dataset of R138.

One BPSK signal.
[R136] Deep Learning Models for Wireless Signal Classification with Distributed Low-Cost Spectrum Sensors (Rajendran et al)
The next paper uses the simple but error-free model formulation shown in Equation (1) below:

The machine will be trained using the RML dataset of R138 (see above), as well as a modified version that adds another symbol rate. I think Table I should list ‘8’ as the Samples per symbol parameter, so the modified version of the RML dataset includes a second rate of 

The authors describe the dataset that we analyzed for R138, although I am confident that the symbol rate is not

They describe their motivation for including a second rate as that of “evaluating the sample-rate dependencies of the” ML model. I wonder why they think two rates (one half the other) are enough?

So here we’ve moved up to two BPSK signals.
[R137] Over the Air Deep Learning Based Radio Signal Classification (O’Shea et al)
This O’Shea paper started out promising, in the context of all BPSK signals, because the authors’ state in the Abstract that they want to consider the effects of symbol rate.

I searched through the paper, but could not find any description of how (or if) the symbol rate was varied. I came to the conclusion that it was not. (Leave a Comment below if I’m wrong!)

Equation (1) in R137 is OK. It doesn’t consider random processes (functions of time

OK! So we will have lots of BPSK signals because the roll-off is varied.

I haven’t analyzed this dataset yet. This dataset is analyzed in a separate post. The symbol rate is not varied, as far as I can tell, but the carrier offset is allowed to be a random variable with normal distribution having variance 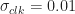

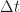
![[0, 16]](https://s0.wp.com/latex.php?latex=%5B0%2C+16%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)


So here in R137 we definitely have more than one BPSK signal. We have many: the excess bandwidth in the SRRC pulse is varied and there is a small random carrier-frequency offset.
Update February 2021. I estimated the PSDs for 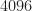



I conclude that the symbol rate, excess bandwidth, and carrier offset are not varied.
So, one BPSK signal after all. Longer data records would allow me (and you!) to examine these signals in more detail, so as to verify the distributions in Table I.
[R139] Semi-Supervised Radio Signal Identification (O’Shea et al)
Another of O’Shea’s papers uses the RML dataset.

So, one BPSK signal.
[R141] Interference Classification Using Deep Neural Networks (Yu et al)
Maybe I shouldn’t include this paper in the present post, because I’m not quite clear on whether or not there is a BPSK signal involved. Nevertheless, there are some lessons about applying CSP that are likely valuable to many of the readers of the CSP Blog. So let’s check it out.
In the Abstract, we see that the authors want to perform modulation recognition, but the signals of interest are interferers, not the signals involved in their communication link:

And they preview their result: CSP fails. Uh-oh. The data model is signal plus interferer plus noise:

I’m not sure why these assumptions are needed, but here they are:

There is apparently cochannel interference, but somehow also perfect synchronization has been achieved. Here is the universe of interferers:

Interferers 1, 3, and 4 are not cyclostationary signals. Interferer 2 is trivially cyclostationary, but can also be easily detected, characterized, and removed by linear (Fourier) methods. Interferer 5 could be any of the signals, I suppose, that we have studied at the CSP Blog, including BPSK. So that’s where a BPSK signal might be lurking.
The mathematics is a bit sloppy. Equation (3) is almost the periodogram, but you need the factor of 


The PSD is not the squared-magnitude of the Fourier transform!

OK, so the “cyclic spectrum” here is (6), and is what people (and the CSP Blog) usually call the cyclic-domain profile. Here are the authors’ plots for the CDPs for the various interferers:

This is confusing for a couple reasons. The y-axis is labeled “maximum cyclic spectral coherence,” but the authors haven’t defined or mentioned spectral coherence.
The plot for the signal of interest does not have any prominent peaks, yet the signal of interest is said to be an MPSK signal, which always has a non-conjugate CF equal to the symbol rate. Unless the signal is filtered and sampled at a rate less than or equal to the symbol rate! Or the raw symbol sequence is processed…
The non-conjugate CDP for the sine-wave signal should not have any peaks aside from the one corresponding to 
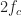

 .
.and the conjugate CDP:

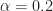 .
.The CDP for the Unknown Modulated Signal is difficult to assess since the signal set is not described.
I also wonder why there are only 
Moving on to the signal parameters, we notice that the signals are generated and then simply decimated by a factor of 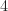

After the machine is trained using all these downsampled signals, the conclusion is that the PSD works best:

which seems reasonable to me. There are hardly any cyclostationary signals here.
R141 is perhaps an extreme example, but it illustrates the trend: Quickly get through signal definition, analysis, and generation, then throw whatever you have into the machine. If the labels come out to your liking, publish. If they don’t, iterate. The relationship between the output-label performance and the truth of the input labels doesn’t really matter, because no one can look at the trained neural network and say what it has used to make its decisions.
Due to the Unknown Modulated Signal mystery, I’m going with an imaginary number of BPSK signals for R141.
[R143] Fast Deep Learning for Automatic Modulation Classification (Ramjee et al)
Finally, R143 uses the RML dataset, which contains PSK, QAM, AM, FM, and CPFSK signals, but posits a signal model that is valid only for the PSK and QAM signals. So, one BPSK signal here.


What’s Going on Here?
The researchers are mostly focused on very narrow problems (“one BPSK signal”) for two reasons. The first is that the machines have enormous appetites and if you consider varying several parameters (modulation type, symbol rate, carrier offset, SNR, pulse shaping, etc.) you end up with an impractical training set. The topic is still modulation recognition, so you can’t reduce the number of modulation types too much, but you can select one value of all the other parameters. You still have a data-set size problem, because you have to generate many examples of the signal by using different random transmitted symbol sequences.
The second reason is that these researchers don’t know much signal theory and they don’t know much about the details of communication signals and systems. This is evidenced by the various strange and mangled mathematical expressions for signals and for features. I think they want to get the training set creation over with as soon as possible so they can hand-craft their machine hyperparameters.
A second serious issue is that posted datasets do not appear to be carefully vetted by their producers. I know this is a tedious task. I had a small problem with the set I posted for the Machine Learner Challenge-a kind CSP Blog reader pointed it out. I was able to describe the issue in the Challenge data post, and it is minor enough that I didn’t need to pull the dataset from the Downloads page. But I will pull it if serious problems are found.
A final muse. I’ve uncovered several major problems with the RML dataset (The Literature [R138]) in this post. I’ve also documented here that multiple ML researchers are relying on that dataset to train and test their algorithms. If one uses a flawed dataset for ML and the recognition performance is good, what does that mean about the ML algorithm? It must mean that, at least some of the time, the machine is using idiosyncrasies or flaws in the dataset as valid classification features. This makes it vital that the datasets are carefully vetted. A major obstacle to vetting the RML dataset is the extreme shortness of the data vectors (
“Garbage-In => Garbage-Out” might not apply to ML MR. It doesn’t matter to ML recognition performance that the input vectors adhere to the established high-fidelity mathematical models of real-world communication signal types. All that matters is that there are sufficiently many differences between the vectors for each class. The machine will find them, because it doesn’t care if the BPSK vectors are consistent with BPSK-ness, unlike MR methods that are based on sound probability models. The machines just care if the BPSK vectors are different in any consistently measurable way from the vectors in the other signal classes. But when that machine is applied to a different dataset (and isn’t that the ultimate goal?), with different idiosyncrasies or none, poor performance will result.
Update June 8, 2020
The new paper The Literature [R146] also uses the RML 2016a dataset:

The description of the RML 2016.10a dataset is consistent with DeepSig’s description and my understanding of it. I hope that the researchers applied an antialiasing filter prior to downsampling, else they will alias a lot of noise into the center of their band prior to ML processing.
For the highest RML SNR parameter of

It is a bit hard to see, but the true (input) labels are the rows and the ML assigned signal-type labels are the columns; the third row and column corresponds to AM-SSB. So, most of the time the machine assigns the ‘SSB’ label to inputs that are labeled ‘SSB.’ But remember that there is no signal component in the SSB-labeled signals in the RML dataset. To verify, I looked at the first
So this particular machine learns to recognize noise as AM-SSB. It doesn’t matter that the signal isn’t there because ‘AM-SSB’ness doesn’t matter to the machine. But this idea can extend to all other elements of the confusion matrix. How much of any of them is due to the character of the signal and how much is due to idiosyncrasies of the training/testing data sets that are unintentionally introduced by the data-set creator?
This unfortunate behavior for AM-SSB could have been detected by the researchers if they also included a twelfth labeled input: AWGN.
Comments, corrections, recommendations, criticisms are welcome. Enter them below.
I agree that the issue of modulation recognition is harder for ML than classical methods due to the continuous nature and wide span of different symbol rates/bandwidths.
ML is mostly best when you don’t have a clear characterization of the signals.
When you think about computer vision, the size of the images and objects being looked for in them are all of similar scale.
I’m a noob when it comes to cyclostationary signal processing (working on that, largely by going through this blog), but I definitely tripped over the comment “If you are uncomfortable with BPSK signals having irrational symbol rates…”
Perhaps I’m missing something, but can’t you just specify a rate of 1 symbol every (1/pi) seconds, yielding a symbol rate of pi? (Or similar for any other irrational number.)
On the other hand, I wonder if there are quantum effects or similar that limit the physically possible (let alone practical) symbol rates, but that would apply to many symbol rates with too many digits of precision, not just irrationals.
Okay, enough impractical pedantry, now to see how much of the rest of the post I can understand.
By the way, thanks for the blog, Chad! I _think_ I’m learning a lot, though I’ll have to get further into some coding to be sure. I can definitely appreciate your perspective on machine learning; it’s very reminiscent of my own experience with applying (novel/stochastic/evolutionary/nature-inspired/pick-your-buzzword) optimization algorithms to electromagnetics problems, such as the design of antennas, where people spend tons of time “optimizing the optimizer” and replacing expertise in antennas with expertise in optimization algorithms.
Thanks for the thought-provoking comment Clint, and thanks for visiting the CSP Blog.
Certainly on paper we can specify any rate we wish to. I was thinking of specifying some irrational rate in a system or computer model of a system, and you can’t quite get to an irrational rate in the latter. For the former, you wouldn’t be able to confirm that you had an irrational rate, just that it was as close to the target number as your measurement precision allows. But, as you say, that kind of thing is also true for rational rates. Even for a system rate that is integral, such as 10 MHz, we can’t really know that the system is producing exactly that rate, but at least it is possible to represent it exactly in a computer because the number happens to be exactly representable with our finite precision numbers.
So, yeah, I’m no number theorist, but I still think the idea irrational symbol rates will probably make some people uncomfortable, perhaps even including me. They might then have been distracted from my main points that follow.
Thanks again!
Can you help me to open this dataset with matlab
No, but I did include some python code in the post. That’s what I used to get at the signals in DeepSig’s 2016.10A data set (and their other data sets as well).
I think we should be a little more patient about the ML approach. Research in this area is still young and people take one step after the other (which of course does not justify the publication of erroneous data sets, assuming your analysis is correct). Currently it looks like there are a lot of young PhD students out there with little experience and time but the need to publish quickly in order to get their degree…
Once these new ML approches go into practical use cases, they will reveal their real performance. Unfortunately this task is often moved from universities to companies, which rarely publish their results. At least DeepSig (and I also know other companies) are still there and working on the topics.
Thanks for stopping by, S, and leaving a thoughtful comment.
I wonder if you could provide me with some concrete suggestions about how I might be more patient. The RML data set I analyzed in the post dates from 2016, and is still available. Should I have waited another year or two? I worked with two prominent ML/MR researchers (in succession) before I even considered posting the Challenge. They talked a good game, but faded away without producing anything. Should I have worked with a third? I analyzed multiple papers in the present post, many of which are using the flawed RML data set. Should I have waited until more young researchers used the un-analyzed data set?
From my point of view, I’m producing analysis and criticism at glacial speeds, but it appears that I’m coming across as impatient. Can you elaborate on that?
I’ve enjoyed reading the blog. This post, and some of the related ones on signals datasets, are a topic that strikes home. I’ve worked in a related field, and it’s good to see some of the issues laid out here.
There’s plenty of momentum in favor of machine learning, so it’s good to see a discussion of some of the shortcomings. And the general attitude is one of blindly applying techniques rather than understanding the problem to be solved. And a conviction that the machine learning results must be the best state of the art because otherwise, well, no one knows but that’s what everyone says about machine learning. And a careful willingness not to look too closely because even if the dataset is corrupted the machine learning must have learned something after all and so it’s not really a failure. And besides, who has time to validate data when they could be publishing papers? I’ll stop there.
That said, I think there really is a place for machine learning, but it still requires a solid understanding of the fundamentals of the problem to be solved and doesn’t rule out using expert created methods as well.
Thanks for stopping by the CSP Blog and the great comment Seth! If I had a “Comment of the Month” running post, this would be the one for September (so far!).
I agree that there is a place for machine learning, and I’m actively involved through working with a doctoral student on machine learning for modulation recognition. I just abhor the gold-rush mentality that polishes a whole lot of pyrite and insists on telling you it is gold.
I also suspect that the best ML or AI approach to RFSA will eventually outperform statistics-based methods such as CSP methods. Eventually. But to get there, we have to be more honest about what we are actually doing today with ML.
Hey Chad,
Thank you for this amazing post and i really learn a lot from this blog.
By any chance, are you able to post the matlab or python code you use for plotting the PSD?
Hey Emily! Thanks for stopping by.
Do you mean code for creating the movies and figures, or code for estimating the PSDs from the data? The former isn’t so sophisticated, and I can post how to use the basic avi-file creation (movie creation) tool in MATLAB. The latter is not something I’m going to post; see here.
For matlab user, pwelch(x) is the most fundamental and easy to use tool for computing PSD using Welch’s method. You may try it as a starting point.