
I’ve developed another dataset for use in assessing modulation-recognition algorithms (machine-learning-based or otherwise) that is more complex than the original sets I posted for the ML Challenge (CSPB.ML.2018 and CSPB.ML.2022). Half of the new dataset consists of one signal in noise and the other half consists of two signals in noise. In most cases the two signals overlap spectrally, which is a signal condition called cochannel interference.
We’ll call it CSPB.ML.2023.
Dataset Description
Let’s start by describing the dataset in detail. Then I’ll present my current processing results as a performance target.
I created 60,000 IQ data files that contain a single signal in white Gaussian noise and 60,000 IQ data files that contain two signals in white Gaussian noise. For the single-signal files, the spectral density of the noise is always one (0 dB), and for the two-signal files, it is always two (3 dB). This latter fact arises because the way the two-signal files are created is by adding two of the single-signal files together. Since the noises are always independent file-to-file, the noises add on a power basis, and we get twice the noise spectral density. All data files have length 262,144 samples.
I’m not trying to make these datasets realistic in terms of some specific receiver noise floor. In fact, lots of realistic things are ignored. In my various machine-learner challenge datasets, the idea isn’t to solve the general modulation-recognition problem, it is to explore the strengths and weaknesses of the machine-learning optimization techniques because those strengths and weaknesses are not studied carefully by actual machine learners in favor of just pushing hype and false claims of superiority. (Sorry, but it’s true dudes.)
The dataset employs eight signals, like the original Challenge datasets, but here the excess bandwidth is fixed at 0.35 for the PSK and QAM signals, and is whatever it is for the MSK and GMSK signals. The eight signals are BPSK, QPSK, 8PSK, 16QAM, 64QAM, SQPSK, MSK, and GMSK. The randomized parameters are the symbol rate, carrier frequency offset, and SNR.
The symbol rates range from about 0.1 Hz to 0.6 Hz, the carrier frequency offsets range from -0.2 Hz to 0.2 Hz, and the signal powers range from 2 dB to 20 dB. The distributions of these parameters are not uniform.
The sampling rate is set equal to unity; we (I) don’t care about the physical setup. We are trying to see how well-trained neural networks perform on the dataset and how well they generalize–I’ll be posting a generalized (slightly) dataset eventually.
Internally at the CSP Blog, this dataset is called “PSK Mixtures,” and so the involved data files have names like ‘psk_mixture_1200.tim.’ And if you see the acronym ‘PM’ related to CSPB.ML.2023, it stands for PSK Mixtures. You can read these binary data files into MATLAB using read_binary.m. Even easier, perhaps, is to realize that the data-file format of these .tim files is nearly identical to the Ettus SDR binary float data-file format, with the exception that the first two records of a .tim file are two integers: a 1 or 2 to indicate real or complex data, and the number of samples in the data file.
The original motivation for this dataset comes from a project I was working on a couple years back. In that project, there was an RF situation where multiple cochannel signals could be received and we desired to successfully demodulate one of them in the presence of the other(s). That is, we had to perform signal separation. But to do that, we needed to assess the situation: How many signals are present, what are their parameters, and what are their types? So this is a bit closer to RF Scene Analysis than a typical machine-learning modulation-recognition paper usually gets (they just output labels). But it isn’t a made-up problem or situation, it really happens sometimes.
Single-Signal Truth File (Metadata)
The truth parameters for the single-signal files are contained in a simple text file called PM_single_truth_10000.txt. The first few entries are shown in Figure 1.

There is some redundancy in the file. The first three fields indicate the index of the data file. For Index_1, the corresponding data file in the dataset is psk_mixtures_1.tim. The number after Index_ in the truth files is always the index embedded in the data-file name. The fourth field is the symbol rate, the fifth is the carrier frequency offset, the sixth indicates the modulation variant, the seventh is the modulation type, and the last parameter is the signal power in dB.
Modulation-Type Parameter
The seventh field is the modulation-type parameter, which can be 1 for PSK, 2 for QAM, or 3 for staggered modulation (MSK, GMSK, SQPSK).
Modulation-Variant Parameter
This indicates the variant within the modulation type. For modulation-type 1 (PSK), the value of the modulation-variant parameter is the number of bits per symbol. The same is true for modulation-type 2 (QAM). For modulation-type 3 (staggered), if the variant is 1, the signal is SRRC SQPSK, if the variant is 2, the signal is MSK, and if it is 3, the signal is GMSK.
| Mod- Type | Mod- Variant | Signal |
| 1 | 1 | BPSK |
| 1 | 2 | QPSK (4QAM) |
| 1 | 3 | 8PSK |
| 2 | 2 | 4QAM (QPSK) |
| 2 | 4 | 16QAM |
| 2 | 6 | 64QAM |
| 3 | 1 | SQPSK |
| 3 | 2 | MSK |
| 3 | 3 | GMSK |
Two-Signal Truth File (Metadata)
The two-signal files are created by simply adding together each successive pair of single-signal files. The first two-signal file is for index 60001 (so it would be psk_mixtures_60001.tim) and is just the sum of the single-signal data files corresponding to Index_1 and Index_2 in Figure 1. The metadata for each of the involved signals is copied over to the corresponding line in the two-signal truth file PM_two_truth_10000.txt. See Figure 2 for a snippet of the full file.

To make concrete what kinds of signal scenarios we’re talking about in the PSK Mixtures dataset, I plotted the PSD for the first 100 single-signal files and also the first 100 two-signal files in Video 1. Of particular note is that sometimes the two signals completely overlap spectrally and sometimes they do not overlap at all.
CSP-Based Performance Example
I’ve applied my CSP-based modulation-recognition system (My Papers [25,26,28,43]) to a tenth of the dataset–I processed every tenth file of the 120,000 files. (Actually there are only 119,999 files because there are only 59,999 of the two-signal files.)
There are several ways to assess whether the signal-processing algorithm has detected and successfully processed the signal in the data file. The first is to determine whether the produced symbol rate matches the true one. The produced estimate must be within 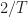

The single-signal results are shown in Figure 3. “Correct Const” means that the modulation-variant parameter estimate matches the truth, and “Correct Mod” means the modulation-type parameter estimate matches the truth. For the SNR to be correct requires it is within 2 dB of the truth.

The two-signal results are shown in Figure 4. Here the problem is much harder, but the performance monotonically improves with increasing processing block length. The achievable performance is not well understood. I made no attempt to limit the range of signal-to-interference (SIR) values experienced by either signal–I just add successive pairs of the single-signal data files together. So that means sometimes there will be a low SIR indeed, when one of the signals has power at the high end of the range (20 dB) and the other at the low end (2 dB).

It would be great to compare machine-learning and CSP processing on this (and all) datasets in a uniform way. In particular, compare the modulation-class label performance AND compare the parameter-estimation performance. That was, in fact, the driving motivation behind the original Challenge dataset, but nobody has yet provided me anything from a neural network except the modulation-class labels. In many real-world applications, though, the parameters that define the signal are also of high interest–not just the label.
The Currently Available Portion of the Dataset
I’ve put the first 10,000 of the 60,000 single-signal files on the CSP Blog in 10 batches of about 2 GB each. I’ve also put the first 10,000 two-signal files on the Blog. This chunking and partial-posting is necessary because WordPress.com limits an individual file to 2 GB, and also if I tried to upload all 120,000 files I’d run out of storage space. I’m at the maximum you can get from WordPress, and I asked specifically for more and said I’d pay, but no luck. Maybe 10,000 of each type of PSK mixture will be enough to get people started?
Comments, errors, compliments, and humor are welcome in the Comments section below. Especially errors!
Great post, Chad! I am currently in the process of figuring out what my class project(s) for school will be this semester; maybe I’ll propose an algorithm or model to challenge your results in this post 🙂 Do you plan to release a data file withholding the labels for people to submit their results to you? I can only imagine that is a heavy lift on your part.
It’s funny, I have a MATLAB function that reads in your other datasets but it also will create co-channel examples in the exact way that you mention; it will simply average two other examples in the dataset and knock the SNR labels down by 3 dB. I average rather than sum to keep the noise floor at 0 dB.
I suppose while I’m on that topic, I did notice that in your 2022 dataset, the examples where the base symbol period is 1 have no visible second-order cycle feature. It looks like you resampled with a very sharp filter, so I am thinking they are effectively duobinary signaling. If so, they still should have higher-order cycle features but I haven’t looked yet.
As for your comments on storage space, have you considered Google Drive or Microsoft OneDrive? They are something like $2/month for 1 TB of cloud storage. I use OneDrive for personal use and love it.
My plan is to generate a different, but related, dataset for the purpose of testing the accuracy and generalization capabilities of networks trained on CSPB.ML.2023. That dataset will be similar in structure, but the random variables involved in the signal models will be different, just as I did in CSPB.ML.2022. The performance of my CSP algorithm will be similar because it features high generalization, but who knows about the neural-network solutions.
I also posted only a small fraction of the total number of files associated with CSPB.ML.2023, so I could post some of the remaining and withhold labels. That might be a reasonable generalization test, because there is a lot more variability in the two-signal situation so that the range of scene instances already posted might not overlap all that much with the reserved instances…
Yes, good catch! The number of instances like that is tiny, but most of those instances will foil the algorithm I apply because there are no features for such signals. The BPSK signal, though, does still show the conjugate doubled-carrier feature. But, yeah, I shouldn’t have included the case of a symbol period of one.
I did look into Google Drive, but I must have messed up because the prices I saw were much higher–I’d better check again. Thanks much!
The prices for Google Drive are an order of magnitude higher: for 2$/month you only get 100GB. (I have a yearly plan for 21$ that gets me 100GB). Quick google told me, that if you go with OneDrive business, you can get 1TB for 5$/month, personal is a little more at 7$/month, but you also get all the other Office things, which might or might not be useful.
But specifically for hosting datasets for ML, maybe huggingface will serve your needs? I don’t think they have a limit for free tiers. https://discuss.huggingface.co/t/is-there-a-size-limit-for-dataset-hosting/14861/3
Hi Chad, after attempting to parse through the PM_single_truth_10000.txt and assign a Signal Type based on the listed Modulation Type (column 7) and Modulation Variant (column 6) parameters, similar to your Table 1 in this post, I ran into an issue on the following six lines: 644, 2953, 3854, 4330, 8809, and 9468. On those six lines, the Modulation Type (column 7) is “1”, so PSK, which is fine; however, the Modulation Variant (column 6) is “0”, so a bit rate of zero or “zero”-PSK… When you get the chance, can you double check those indices and let us know what was intended there? Perhaps those zeros were supposed to be ones and therefore those are BPSK? Thanks.
Good catch! (Another one, see above for the first catch.)
The random-number generator has some quirks (not using MATLAB’s here) and there was never supposed to be a 0PSK signal. These six signals were generated as sine waves at the carrier frequency offset listed in the truth file. I suppose people can either remove them from their investigations or introduce the “SINUSOID” label.
Hello Mr Chad Spooner
This is a fantastic initiative. Your dedication to exploring the AI and Signal Processing is both commendable and inspiring. Sorry for my dumb question, but, is there any tutorial to learn how to read the files? I run downloaded the first 10.000 and run the readme.m and results in “>> read_binary
Not enough input arguments.
Error in read_binary (line 11)
localName = [‘./’ filename];”
Hey Daniel! Thanks for the compliments, reading the Blog, and your comment.
I can help.
In MATLAB, you want to run read_binary.m to read in one of my supplied binary CMS files. These files have a format that is very close to sigMF and also to Ettus binary data files. The difference is that there are two integers at the top of my data files. The first is either a ‘1’ or a ‘2’, indicating whether the data file is real numbers or complex numbers. The second is the number of numbers.
If you want to see how to use a MATLAB function, typically you type ‘help a_matlab_function.m’ or ‘help a_matlabl_function’ and the comments at the top of the corresponding m-file are displayed. So here is an illustration of that for my read_binary.m file:
You can put this in a loop to read in a bunch of the data files, then format them however your mod-rec or signal-analysis system requires.
Does that help?
Thank you Chad. I’m new on Matlab, but it’s working now.
Best regards,
Daniel
Hi, I was on your post PSK/QAM Cochannel Dataset for Modulation Recognition Researchers [CSPB.ML.2023] : https://cyclostationary.blog/2023/02/02/psk-qam-cochannel-data-set-for-modulation-recognition-researchers-cspb-ml-2023/comment-page-1/thanks
Thanks for uploading such an interesting dataset.
I am quite a neophyte to this domain, but I want to dwelve more into it, and I face difficulties simply ploting the data :
When I try to plot a BPSK (example the index 14), I don’t find the aspect I am used to.
Here’s what I wrote :
rxSig = read_binary(‘PM_One_Batch_1\psk_mixture_14.tim’);
scatterplot(rxSig)
1) Should I expect to see the general aspect of a BPSK (the 2 clusters of points) ?
2) If so, how to do it ?
I feel like the points drift in the complex plan due to the fact that I didn’t consider the frequency offset, sample rate …
Thank you in advance,
Sincerely,
Alexis
Thanks for reading the CSP Blog, Alexis, and for the comment! I appreciate it very much.
This is fine in terms of reading in the data. A scatterplot of the returned data will not be helpful, though…
No, you should not expect that. The PSK and QAM signals in the dataset employ square-root raised-cosine pulse-shaping functions. These functions do not meet the Nyquist intersymbol-interference-free criterion–even at the proper sampling instants, other symbols with contribute to the current symbol. Additionally, as you note, the carrier-frequency offset (CFO) is not zero for the signals in the dataset (although it can be small), and you have to deal with the symbol-clock phase. To understand the CFO and symbol-clock phase, I recommend reading my post on synchronization.
To get at the constellation when starting with IQ data with unknown CFO, symbol rate, carrier phase, symbol-clock phase, and square-root raised-cosine pulse rolloff (also called the excess bandwidth), you have to do these steps:
1. Isolate the signal via filtering
2. Estimate the CFO and shift the filtered signal toward zero frequency
3. Estimate the symbol rate
4. Estimate the rolloff
5. Apply a matched filter which is the square-root raised-cosine pulse itself, using the estimated rolloff and rate
6. Estimate the symbol-clock phase
7. Sample at time instants implied by the estimated rate and symbol-clock phase
8. Plot the real vs imaginary components of the obtained samples
If you do that correctly, you’ll see two well-separated clouds of points, which indicates a BPSK constellation.
I have a system that does all that blindly and automatically. When I process psk_mixture_14.tim I get this PSD:
and this extracted constellation:
Overall Performance
Classification Accuracy: 94.9 % overall across eight real‑world modulation types, including cochannel interference
Modulation Types: BPSK, QPSK, 8PSK, SQPSK, MSK, GMSK, 16QAM, 64QAM
Detailed Classification Metrics
PSK Family: Perfect/near‑perfect classification (F1 ≥ 0.99).
MSK/GMSK Variants: Strong performance (F1 ≥ 0.97).
Higher‑Order QAM: Most challenging, but still solid (F1 ≥ 0.79)
Parameter Estimation
Symbol Rate MAE: 0.120656 samples/symbol (consistent across all modulations).
Carrier Frequency Offset MAE: 0.102365 Hz (≈4× improvement over prior approaches).
Error Range: All modulation types exhibit MAE < 0.125.
Operational Metrics
Processing Throughput: 22.2 signals / second on standard hardware.
Memory Footprint: < 2 GB RAM for full dataset processing.
Reliability: 100 % file‑access and parsing success rate (no dropped or corrupted files).
Robustness & Error Analysis
Single‑Signal Scenarios: 95.2 % accuracy (baseline).
Cochannel Interference: 94.1 % accuracy (only 1.1 % degradation under spectral overlap).
Total Error Rate: 5.1 % across all 9,994 test signals.
Machine Learning Pipeline
• Pipeline: Feature selection → StandardScaler → GradientBoostingClassifier
• Validation: Stratified 80/20 split with cross‑validation
Welcome to the CSP Blog Jalil! And thanks for the comment and results. Although … the format of the comment makes it seem like it was generated by an LLM.
Anyway, this performance summary is similar to what we’ve seen on various datasets over the past seven or eight years, including some performance results I’ve obtained with my student John Snoap (see My Papers [50-52,54-56]). If you hand-craft your network and its hyperparameters enough, you can usually get a low error on any dataset. The question is, always, what did the machine actually learn, and how well does it generalize? How well does it do on a dataset that is every-so-slightly different in terms of its underlying random variables and their probablility density functions?
That’s why I created the “Generalized” datasets for both the original “Challenge” dataset and the cochannel dataset that you processed.
See CSPB.ML.2023G1 and CSPB.NL.2022.R2
Regarding the rate and CFO MAE you report, I see the symbol-rate MAE is expressed in “samples per symbol” and the CFO MAE is expressed in Hz. I believe both should be expressed in Hz–perhaps this is just a typo. In any case, these are large errors. As a reminder, in the CSP algorithm I used here, no output signal-label string is counted as correct unless the associated signal parameters are correctly estimated to within a couple native “cycle-frequency resolution” widths. That width is the reciprocal of the length of the processed data. It matters because if a system such as yours outputs “BPSK and QPSK”, and the parameters are wildly off (as evidenced by your MAEs), then any downstream processes will not be effective. So … what data length(s) did you use?
Great post and i am really intrested to move forward. can i get the full dataset link to process?
Welcome to the CSP Blog Muhammad! Thanks for reaching out and for your interest in CSPB.ML.2023.
It will take some effort to upload the remaining files for CSPB.ML.2023, so I want to get a picture of what you’ve done with the first 10000 single-signal and first 10000 two-signal data files. Have you trained a network? Have you tried to apply it to the generalized dataset CSPB.ML.2023G1?