
Dr. Snoap’s final journal paper related to his recently completed doctoral work has been published in IEEE Transactions on Broadcasting (My Papers [56]).
Continue reading “Final Snoap Doctoral-Work Journal Paper: My Papers [56] on Novel Network Layers for Modulation Recognition that Generalizes”Tag: Modulation Recognition
CSPB.ML.2023G1
Another dataset aimed at the continuing problem of generalization in machine-learning-based modulation recognition. This one is a companion to CSPB.ML.2023, which features cochannel situations.
Quality datasets containing digital signals with varied parameters and lengths sufficient to permit many kinds of validation checks by signal-processing experts remain in short supply. In this post, we continue our efforts to provide such datasets by offering a companion unlabeled dataset to CSPB.ML.2023.
Continue reading “CSPB.ML.2023G1”PSK/QAM Cochannel Dataset for Modulation Recognition Researchers [CSPB.ML.2023]
The next step in dataset complexity at the CSP Blog: cochannel signals.
I’ve developed another dataset for use in assessing modulation-recognition algorithms (machine-learning-based or otherwise) that is more complex than the original sets I posted for the ML Challenge (CSPB.ML.2018 and CSPB.ML.2022). Half of the new dataset consists of one signal in noise and the other half consists of two signals in noise. In most cases the two signals overlap spectrally, which is a signal condition called cochannel interference.
We’ll call it CSPB.ML.2023.
Continue reading “PSK/QAM Cochannel Dataset for Modulation Recognition Researchers [CSPB.ML.2023]”Neural Networks for Modulation Recognition: IQ-Input Networks Do Not Generalize, but Cyclic-Cumulant-Input Networks Generalize Very Well
Neural networks with CSP-feature inputs DO generalize in the modulation-recognition problem setting.
In some recently published papers (My Papers [50,51]), my ODU colleagues and I showed that convolutional neural networks and capsule networks do not generalize well when their inputs are complex-valued data samples, commonly referred to as simply IQ samples, or as raw IQ samples by machine learners.(Unclear why the adjective ‘raw’ is often used as it adds nothing to the meaning. If I just say Hey, pass me those IQ samples, would ya?, do you think maybe he means the processed ones? How about raw-I-mean–seriously-man–I-did-not-touch-those-numbers-OK? IQ samples? All-natural vegan unprocessed no-GMO organic IQ samples? Uncooked IQ samples?) Moreover, the capsule networks typically outperform the convolutional networks.
In a new paper (MILCOM 2022: My Papers [52]; arxiv.org version), my colleagues and I continue this line of research by including cyclic cumulants as the inputs to convolutional and capsule networks. We find that capsule networks outperform convolutional networks and that convolutional networks trained on cyclic cumulants outperform convolutional networks trained on IQ samples. We also find that both convolutional and capsule networks trained on cyclic cumulants generalize perfectly well between datasets that have different (disjoint) probability density functions governing their carrier frequency offset parameters.
That is, convolutional networks do better recognition with cyclic cumulants and generalize very well with cyclic cumulants.
So why don’t neural networks ever ‘learn’ cyclic cumulants with IQ data at the input?
The majority of the software and analysis work is performed by the first author, John Snoap, with an assist on capsule networks by James Latshaw. I created the datasets we used (available here on the CSP Blog [see below]) and helped with the blind parameter estimation. Professor Popescu guided us all and contributed substantially to the writing.
Continue reading “Neural Networks for Modulation Recognition: IQ-Input Networks Do Not Generalize, but Cyclic-Cumulant-Input Networks Generalize Very Well”Shifted Dataset for the Machine-Learning Challenge: How Well Does a Modulation-Recognition DNN Generalize? [Dataset CSPB.ML.2022]
Another RF-signal dataset to help push along our R&D on modulation recognition.
Update October 2023: A flaw in the way a random-number generator was used to create CSPB.ML.2022 (and CSPB.ML.2018) has led me to recreate the dataset and post it here. It is called CSPB.ML.2022R2.
Update February 2023: A third dataset has been posted to the CSP Blog: CSPB.ML.2023. It features cochannel signals.
Update January 2023: I’m going to put Challenger results in the Comments. I’ve received a Challenger’s decisions and scored them in January 2023. See below.
In this post I provide a second dataset for the Machine-Learning Challenge I issued in 2018 (CSPB.ML.2018). This dataset is similar to the original dataset, but possesses a key difference in that the probability distribution of the carrier-frequency offset parameter, viewed as a random variable, is not the same, but is still realistic.
Blog Note: By WordPress’ count, this is the 100th post on the CSP Blog. Together with a handful of pages (like My Papers and The Literature), these hundred posts have resulted in about 250,000 page views. That’s an average of 2,500 page views per post. However, the variance of the per-post pageviews is quite large. The most popular is The Spectral Correlation Function (> 16,000) while the post More on Pure and Impure Sinewaves, from the same era, has only 316 views. A big Thanks to all my readers!!
Continue reading “Shifted Dataset for the Machine-Learning Challenge: How Well Does a Modulation-Recognition DNN Generalize? [Dataset CSPB.ML.2022]”Cyclostationarity of DMR Signals
Let’s take a brief look at the cyclostationarity of a captured DMR signal. It’s more complicated than one might think.
In this post I look at the cyclostationarity of a digital mobile radio (DMR) signal empirically. That is, I have a captured DMR signal from sigidwiki.com, and I apply blind CSP to it to determine its cycle frequencies and spectral correlation function. The signal is arranged in frames or slots, with gaps between successive slots, so there is the chance that we’ll see cyclostationarity due to the on-burst (or on-frame) signaling and cyclostationarity due to the framing itself.
Continue reading “Cyclostationarity of DMR Signals”Comments on “Deep Neural Network Feature Designs for RF Data-Driven Wireless Device Classification,” by B. Hamdaoui et al
Another post-publication review of a paper that is weak on the ‘RF’ in RF machine learning.
Let’s take a look at a recently published paper (The Literature [R148]) on machine-learning-based modulation-recognition to get a data point on how some electrical engineers–these are more on the side of computer science I believe–use mathematics when they turn to radio-frequency problems. You can guess it isn’t pretty, and that I’m not here to exalt their acumen.
Continue reading “Comments on “Deep Neural Network Feature Designs for RF Data-Driven Wireless Device Classification,” by B. Hamdaoui et al”Are Probability Density Functions “Engineered” or “Hand-Crafted” Features?
The Machine Learners think that their “feature engineering” (rooting around in voluminous data) is the same as “features” in mathematically derived signal-processing algorithms. I take a lighthearted look.
One of the things the machine learners never tire of saying is that their neural-network approach to classification is superior to previous methods because, in part, those older methods use hand-crafted features. They put it in different ways, but somewhere in the introductory section of a machine-learning modulation-recognition paper (ML/MR), you’ll likely see the claim. You can look through the ML/MR papers I’ve cited in The Literature ([R133]-[R146]) if you are curious, but I’ll extract a couple here just to illustrate the idea.
Continue reading “Are Probability Density Functions “Engineered” or “Hand-Crafted” Features?”DeepSig’s 2018 Dataset: 2018.01.OSC.0001_1024x2M.h5.tar.gz
The third DeepSig dataset I’ve examined. It’s better!
Update February 2021. I added material relating to the DeepSig-claimed variation of the roll-off parameter in a square-root raised-cosine pulse-shaping function. It does not appear that the roll-off was actually varied as stated in Table I of [R137].
DeepSig’s datasets are popular in the machine-learning modulation-recognition community, and in that community there are many claims that the deep neural networks are vastly outperforming any expertly hand-crafted tired old conventional method you care to name (none are usually named though). So I’ve been looking under the hood at these datasets to see what the machine learners think of as high-quality inputs that lead to disruptive upending of the sclerotic mod-rec establishment. In previous posts, I’ve looked at two of the most popular DeepSig datasets from 2016 (here and here). In this post, we’ll look at one more and I will then try to get back to the CSP posts.
Let’s take a look at one more DeepSig dataset: 2018.01.OSC.0001_1024x2M.h5.tar.gz.
Continue reading “DeepSig’s 2018 Dataset: 2018.01.OSC.0001_1024x2M.h5.tar.gz”More on DeepSig’s RML Datasets
The second DeepSig data set I analyze: SNR problems and strange PSDs.
I presented an analysis of one of DeepSig’s earlier modulation-recognition datasets (RML2016.10a.tar.bz2) in the post on All BPSK Signals. There we saw several flaws in the dataset as well as curiosities. Most notably, the signals in the dataset labeled as analog amplitude-modulated single sideband (AM-SSB) were absent: these signals were only noise. DeepSig has several other datasets on offer at the time of this writing:

In this post, I’ll present a few thoughts and results for the “Larger Version” of RML2016.10a.tar.bz2, which is called RML2016.10b.tar.bz2. This is a good post to offer because it is coherent with the first RML post, but also because more papers are being published that use the RML 10b dataset, and of course more such papers are in review. Maybe the offered analysis here will help reviewers to better understand and critique the machine-learning papers. The latter do not ever contain any side analysis or validation of the RML datasets (let me know if you find one that does in the Comments below), so we can’t rely on the machine learners to assess their inputs. (Update: I analyze a third DeepSig dataset here. And a fourth and final one here.)
Continue reading “More on DeepSig’s RML Datasets”All BPSK Signals
An analysis of DeepSig’s 2016.10A dataset, used in many published machine-learning papers, and detailed comments on quite a few of those papers.
Update March 2021
See my analyses of three other DeepSig datasets here, here, and here.
Update June 2020
I’ll be adding new papers to this post as I find them. At the end of the original post there is a sequence of date-labeled updates that briefly describe the relevant aspects of the newly found papers. Some machine-learning modulation-recognition papers deserve their own post, so check back at the CSP Blog from time-to-time for “Comments On …” posts.
On Impulsive Noise, CSP, and Correntropy
And I still don’t understand how a random variable with infinite variance can be a good model for anything physical. So there.
I’ve seen several published and pre-published (arXiv.org) technical papers over the past couple of years on the topic of cyclic correntropy (The Literature [R123-R127]). I first criticized such a paper ([R123]) here, but the substance of that review was about my problems with the presented mathematics, not impulsive noise and its effects on CSP. Since the papers keep coming, apparently, I’m going to put down some thoughts on impulsive noise and some evidence regarding simple means of mitigation in the context of CSP. Preview: I don’t think we need to go to the trouble of investigating cyclic correntropy as a means of salvaging CSP from the evil clutches of impulsive noise.
A Gallery of Cyclic Correlations
For your delectation.
There are some situations in which the spectral correlation function is not the preferred measure of (second-order) cyclostationarity. In these situations, the cyclic autocorrelation (non-conjugate and conjugate versions) may be much simpler to estimate and work with in terms of detector, classifier, and estimator structures. So in this post, I’m going to provide surface plots of the cyclic autocorrelation for each of the signals in the spectral correlation gallery post. The exceptions are those signals I called feature-rich in the spectral correlation gallery post, such as DSSS, LTE, and radar. Recall that such signals possess a large number of cycle frequencies, and plotting their three-dimensional spectral correlation surface is not helpful as it is difficult to interpret with the human eye. So for the cycle-frequency patterns of feature-rich signals, we’ll rely on the stem-style (cyclic-domain profile) plots that I used in the spectral correlation gallery post.
Dataset for the Machine-Learning Challenge [CSPB.ML.2018]
A PSK/QAM/SQPSK data set with randomized symbol rate, inband SNR, carrier-frequency offset, and pulse roll-off.
Update April 2025: All but the first five batch files have been removed. I needed to make space since WordPress has a hard limit on storage. Use CSPB.ML.2018R2 in any case.
Update September 2023: A randomization flaw has been found and fixed for CSPB.ML.2018, resulting in CSPB.ML.2018R2. Use that one going forward.
Update February 2023: I’ve posted a third challenge dataset here. It is CSPB.ML.2023 and features cochannel signals.
Update April 2022. I’ve also posted a second dataset here. This new dataset is similar to the original ML Challenge dataset except the random variable representing the carrier frequency offset has a slightly different distribution.
If you refer to either of the posted datasets in a published paper, please use the following designators, which I am also using in papers I’m attempting to publish:
Original ML Challenge Dataset: CSPB.ML.2018.
Shifted ML Challenge Dataset: CSPB.ML.2022.
Update September 2020. I made a mistake when I created the signal-parameter “truth” files signal_record.txt and signal_record_first_20000.txt. Like the DeepSig RML datasets that I analyzed on the CSP Blog here and here, the SNR parameter in the truth files did not match the actual SNR of the signals in the data files. I’ve updated the truth files and the links below. You can still use the original files for all other signal parameters, but the SNR parameter was in error.
Update July 2020. I originally posted 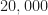
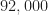
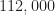
Machine Learning and Modulation Recognition: Comments on “Convolutional Radio Modulation Recognition Networks” by T. O’Shea, J. Corgan, and T. Clancy
Update October 2020:
Since I wrote the paper review in this post, I’ve analyzed three of O’Shea’s data sets (O’Shea is with the company DeepSig, so I’ve been referring to the data sets as DeepSig’s in other posts): All BPSK Signals, More on DeepSig’s Data Sets, and DeepSig’s 2018 Data Set. The data set relating to this paper is analyzed in All BPSK Signals. Preview: It is heavily flawed.
Radio-Frequency Scene Analysis
Modulation recognition is one thing, holistic radio-frequency scene analysis is quite another.
Update October 2023: RFSA is a Wicked Problem.
So why do I obsess over cyclostationary signals and cyclostationary signal processing? What’s the big deal, in the end? In this post I discuss my view of the ultimate use of cyclostationary signal processing (CSP): Radio-Frequency Scene Analysis (RFSA). Eventually, I hope to create a kind of Star Trek Tricorder for RFSA.