
In some recently published papers (My Papers [50,51]), my ODU colleagues and I showed that convolutional neural networks and capsule networks do not generalize well when their inputs are complex-valued data samples, commonly referred to as simply IQ samples, or as raw IQ samples by machine learners.(Unclear why the adjective ‘raw’ is often used as it adds nothing to the meaning. If I just say Hey, pass me those IQ samples, would ya?, do you think maybe he means the processed ones? How about raw-I-mean–seriously-man–I-did-not-touch-those-numbers-OK? IQ samples? All-natural vegan unprocessed no-GMO organic IQ samples? Uncooked IQ samples?) Moreover, the capsule networks typically outperform the convolutional networks.
In a new paper (MILCOM 2022: My Papers [52]; arxiv.org version), my colleagues and I continue this line of research by including cyclic cumulants as the inputs to convolutional and capsule networks. We find that capsule networks outperform convolutional networks and that convolutional networks trained on cyclic cumulants outperform convolutional networks trained on IQ samples. We also find that both convolutional and capsule networks trained on cyclic cumulants generalize perfectly well between datasets that have different (disjoint) probability density functions governing their carrier frequency offset parameters.
That is, convolutional networks do better recognition with cyclic cumulants and generalize very well with cyclic cumulants.
So why don’t neural networks ever ‘learn’ cyclic cumulants with IQ data at the input?
The majority of the software and analysis work is performed by the first author, John Snoap, with an assist on capsule networks by James Latshaw. I created the datasets we used (available here on the CSP Blog [see below]) and helped with the blind parameter estimation. Professor Popescu guided us all and contributed substantially to the writing.
I’ve already gone on record as saying that the reason networks don’t learn cumulants is probably that the typical neural networks used by modulation-recognition machine learners involve layers and a structure that is appropriate for image-classification problems rather than the more abstract modulation-classification problems. The many machine-learning papers on modulation recognition typically use a network borrowed from, or closely modeled on, some successful network for ‘finding the cat in the image.’
The blithe wholesale borrowing of neural-network structures from one domain to another arises from a couple mental habits I’ve been pointing out for a while. The first is the habit of looking at signal- or data-processing problems from the point of view of the processor, but never from the point of view of the data. Data is data, the network will sort it out. The second habit is a reflexive disdain for mathematical modeling and analysis relating to data models. We don’t understand the mathematical or probabilistic structure of the data, we aren’t equipped to, and it is easier not to try. This all leads to a mad rush to apply something that worked ‘over there’ to the problem ‘over here’ with little consideration for whether or not ‘over there’ is a good match for ‘over here.’ Harrumph.
So in our new paper [52], we take a close look at the performance and generalization ability for a couple different neural networks using the two CSP-Blog digital-signal machine-learning datasets CSPB.ML.2018 and CSPB.ML.2022. Both datasets feature the same eight digital modulation types with randomized parameters. The major difference between the two is that the carrier-frequency offset (CFO) random variable has disjoint distributions. In all cases the CFO is small relative to the occupied bandwidth of the signal, so both datasets are similarly realistic in that the signals are good examples of an operational conversion to complex baseband. However, a drawback is that the signals are textbook modulations with independent and identically distributed symbols and no media-access control elements.
The way we look at the performance is by constructing networks that use as input the complex-valued signal samples themselves (‘IQ data’) and, alternately, that use blindly estimated cyclic-cumulant (CC) matrices. Which combination of network and feature performs classification best? Which combination generalizes best? Here is a key result from My Papers [52] that will help us answer these questions:

We considered a capsule network (CAP) and a convolutional network (CNN) and applied the two different kinds of inputs during training. So we have four networks for a given training dataset: CAP with IQ, CAP with CC, CNN with IQ, and CNN with CC. The capsule network with IQ input generally performs the best but it has by far the worst generalization ability. The networks with CC input perform nearly as well and also generalize very well.
So IQ-trained networks are brittle–small changes in the involved signal random variables cause massive performance degradation. But IQ-trained networks can deliver excellent performance for data that strictly conforms to the probabilistic model embodied by the training dataset. Perhaps all of this is not so surprising. As Gary Marcus said recently
Second, there is also a strong specific reason to think that deep learning in principle faces certain specific challenges, primarily around compositionality, systematicity, and language understanding. All revolve around generalization and “distribution shift” (as systems transfer from training to novel situations) and everyone in the field now recognizes that distribution shift is the Achilles’ heel of current neural networks.
Gary Marcus in Noema Magazine
To me, these results (together with the earlier papers in this research program My Papers [50, 51] and more that are forthcoming) provoke fundamental research questions:
Why don’t IQ-input networks learn cyclic-cumulant features? CC-input networks produce superior performance relative to that shown by typical IQ-input networks, so why doesn’t the error get minimized in the IQ-network by learning CCs? Can we modify the hyperparameters, network structure, or the form of the feedback error to force the network to learn things like CCs?
Why don’t IQ-input networks generalize? What is it about the features that are extracted (learned) by the network that makes them so specific to the particular signal instances in the training dataset? What is the machine actually learning?
These are the types of questions we are seeking to answer. Stay tuned for further chapters to the story.
Now go read the paper! And I hope to see you at MILCOM 2022, where John will present the paper.
Some people are raw vegan. I’m raw samples. ha.
Very informative. Thanks.
Congratulations on your new paper, Dr.Chad!
The questions listed in this article is really compelling! And I’ve been thinking about them for a while!
A fundamental work about the latent space in RFML applications is required!
The issue is that even when you feed CC features to the network, we do not know what the network actually learns! It could be that the network latches into something that does not have much to do with actual CC features.
Thank you for this interesting article as usual!
Wholeheartedly agree Abdurrahman!
And also, I think, a new conception of the fundamental layers in the network–much less emphasis on convolution.
This is such a great paper.
What are the consequences of the assumptions in section III? If I understand correctly, the assumptions are specific to QAM/PSK.
Has there been any success when using waveforms outside of PSK/QAM, such as FSK?
I think you’re asking about the assumption that the cycle-frequency pattern conforms to the general equation
where is the cumulant order,
is the cumulant order, 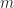 is the number of conjugated factors,
is the number of conjugated factors, 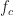 is the carrier-frequency offset,
is the carrier-frequency offset, 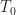 is the symbol interval, and
is the symbol interval, and  is a harmonic number. Signals other than traditional (textbook) PSK and QAM also can conform to this formula: DSSS, CPFSK, many CPM, some forms of FSK, AM-DSB, ATSC-DTV, and others I think. In addition, even if the cycle-frequency pattern deviated from that generic formula, the concept of using a collection of properly estimated cyclic cumulants is valid in general. We might have to work harder if the patterns associated with the signals in the catalog of interest differ greatly, but still the notion of using principled features (features closely related to mathematical transformations or representations of probability density functions) is valid and likely more useful than using I/Q samples.
is a harmonic number. Signals other than traditional (textbook) PSK and QAM also can conform to this formula: DSSS, CPFSK, many CPM, some forms of FSK, AM-DSB, ATSC-DTV, and others I think. In addition, even if the cycle-frequency pattern deviated from that generic formula, the concept of using a collection of properly estimated cyclic cumulants is valid in general. We might have to work harder if the patterns associated with the signals in the catalog of interest differ greatly, but still the notion of using principled features (features closely related to mathematical transformations or representations of probability density functions) is valid and likely more useful than using I/Q samples.
Not that I know of. However, recalling the post on FSK signals, incoherent FSK always has an ‘8-PSK’-like cycle frequency pattern, and clock-phase-coherent FSK typically has a BPSK-like pattern. Carrier-phase-coherent FSK can differ from the PSK/QAM pattern, but is still sensible. So many FSK and CPM types can be folded into the exact same framework we use in the paper.
Thank you! We just submitted paper to MILCOM 23. It continues the line of research embodied by My Papers [50]-[52]. We are switching focus from features (I/Q vs something else) to the structure of the neural network itself.