Neural networks with CSP-feature inputs DO generalize in the modulation-recognition problem setting.
In some recently published papers (My Papers [50,51]), my ODU colleagues and I showed that convolutional neural networks and capsule networks do not generalize well when their inputs are complex-valued data samples, commonly referred to as simply IQ samples, or as raw IQ samples by machine learners.(Unclear why the adjective ‘raw’ is often used as it adds nothing to the meaning. If I just say Hey, pass me those IQ samples, would ya?, do you think maybe he means the processed ones? How about raw-I-mean–seriously-man–I-did-not-touch-those-numbers-OK? IQ samples? All-natural vegan unprocessed no-GMO organic IQ samples? Uncooked IQ samples?) Moreover, the capsule networks typically outperform the convolutional networks.
In a new paper (MILCOM 2022: My Papers [52]; arxiv.org version), my colleagues and I continue this line of research by including cyclic cumulants as the inputs to convolutional and capsule networks. We find that capsule networks outperform convolutional networks and that convolutional networks trained on cyclic cumulants outperform convolutional networks trained on IQ samples. We also find that both convolutional and capsule networks trained on cyclic cumulants generalize perfectly well between datasets that have different (disjoint) probability density functions governing their carrier frequency offset parameters.
That is, convolutional networks do better recognition with cyclic cumulants and generalize very well with cyclic cumulants.
So why don’t neural networks ever ‘learn’ cyclic cumulants with IQ data at the input?
The majority of the software and analysis work is performed by the first author, John Snoap, with an assist on capsule networks by James Latshaw. I created the datasets we used (available here on the CSP Blog [see below]) and helped with the blind parameter estimation. Professor Popescu guided us all and contributed substantially to the writing.
Continue reading “Neural Networks for Modulation Recognition: IQ-Input Networks Do Not Generalize, but Cyclic-Cumulant-Input Networks Generalize Very Well”



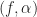 plane we so often see associated with CSP. I’m talking about the principal domain for the discrete-time/discrete-frequency
plane we so often see associated with CSP. I’m talking about the principal domain for the discrete-time/discrete-frequency  dB’ is unwarranted and misleading.
dB’ is unwarranted and misleading.