
Previous SPTK Post: The Characteristic Function Next SPTK Post: Wavelets
In this post, we take a look at a special linear time-invariant system called the matched filter. It is used to detect the presence of a known signal. In practice, it is often applied to the detection of a periodically repeated known portion of a communication signal, such as a channel-estimation frame or frequency-correction burst. It is also widely used in the detection of radar pulses, where the matched-filtering operation is renamed to pulse compression. Filtering, which implies a convolution operation, and correlation are nearly the same thing. Therefore applying a matched filter is sometimes referred to as applying a correlator.
Continue reading “SPTK: The Matched Filter”
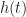 .
.