
Previous SPTK Post: Complex Envelopes Next SPTK Post: Examples of Random Variables
In this Signal Processing ToolKit post, we examine the concept of a random variable.
[Jump straight to ‘Significance of Random Variables in CSP’ below.]
What is a random variable? As the authors of The Literature [R153] say, “a random variable is actually neither random nor a variable.” Good start! They go on to give the usual definition of a random variable, which is a mapping between events in a probability space and the real or complex numbers. We need to review the basics of probability so that we can grasp these key ideas of mappings, events, and probability space.
Axiomatic Probability
Probability theory is often motivated by games of chance, such as those involving dice and cards, and by the associated familiar actions of counting things and forming ratios. When we want to understand what the “chances” are of throwing a six-sided die and seeing that the top face shows two pips, we count all the possible occurrences, or outcomes, associated with throwing the die and divide the number of desired occurrences by the obtained number of possible occurrences to arrive at the desired chance or probability. In this dice example, that chance would be 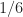
Each time we perform the experiment (also called a trial), we obtain an outcome or event. Suppose our experiment can have some outcome called 

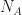


We must have, then

which is the origin of the fact that probabilities lie between zero and one. The frequentist then imagines letting the number of experimental trials increase without bound, 

A complication in interpretation arises for the cases of 
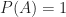

Let the experiment have 




Now, an experimental trial always produces an outcome so that

When we pass to the limit of an infinite number of trials, we obtain

with

We can consider more complicated experiments and associated events (outcomes). We might, for example, wish to know the probability of the occurrence of two events, should the experiment allow that kind of situation. This leads to the notion of the joint probability of two events 

This joint probability may or may not be equal to the product of the individual probabilities 
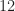

Other events are more tangled up together. Consider next the joint event that on a single throw the sum is seven (event 

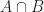
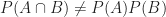
The conditional probability is the probability of one event given that another event happened, which is denoted by 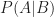

which is the probability of the joint event as a fraction of the probability of the conditioning event. This leads immediately to

The symmetry of this relation with respect to events

In the important case for which the conditioning event has no effect on the probability,

we have

and we say that the two events are statistically independent.
This frequentist, or frequency of occurrence, approach to probability is usually too cumbersome to apply to complex problems, such as analyzing the probabilistic behavior of radio signals (but eventually we will cover the attempt, called fraction-of-time probability, at the CSP Blog), so it is relegated to its role as a motivator, and a more abstract axiomatic probability theory is embraced.
The axioms of axiomatic probability are the following:



The key abstraction is the probability space 
The axioms can be used to develop joint probabilities and conditional probabilities, and they are consistent with Bayes’ Rule. In probability theory, the union of two sets in 

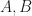
From the axioms, we can develop the following relationships


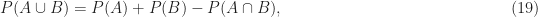


Here the bar on 
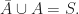
If 
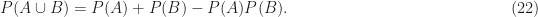
Random Variables
A random variable is a function that maps the elements of the probability space 
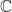

Once we have a probability space 
The issue now becomes characterization of a random variable–what is it like? There are high-level properties of a random variable, such as whether it is real-valued or complex-valued. If the range of numbers for the random variable is finite or countable (such as the integers), the random variable is called discrete. Otherwise it is continuous. The next step in characterization is to connect the probability theory to the numerical values embodying the random variable.
The Cumulative Distribution Function
A simple way to start a characterization of a random variable 
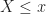
![\displaystyle F_X(x) \triangleq P\left[X \leq x \right]. \hfill (23)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_X%28x%29+%5Ctriangleq+P%5Cleft%5BX+%5Cleq+x+%5Cright%5D.+%5Chfill+%2823%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
This function, 

which follows from the axioms. The function must approach zero as 

Similarly,

The CDF is a non-decreasing function of 
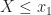


We can use the CDF to find the probability that the random variable lies on some interval, say 

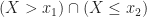


The event



Combining (28) with (31) yields

or

So we can find the probability that the random variable lies on any interval by using the CDF. Further, we can combine different intervals to find the probability that the random variable meets all sorts of conditions, using the basic axioms and derived rules of probability. In this sense, the CDF is fundamental.
Notice that if 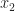

This mathematically formalizes the notion that if one chooses a real number ‘at random’ from the interval 
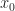
When the CDF possesses step discontinuities, however, we can see that the random variable can take on the value of the independent variable 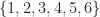
 -axis value is not included in the adjacent line segment. For example,
-axis value is not included in the adjacent line segment. For example,  not .
not .The CDF is one complete way of quantifying the probabilistic behavior of a random variable, but in many kinds of calculations we favor working with its derivative, the probability density function (PDF).
The Probability Density Function
The PDF is defined as the derivative of the CDF,

It follows that the CDF is the integral of the PDF,

Recalling the fundamental theorem of calculus, which says that

where 


provided that 

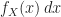
The PDF for the CDF in Figure 2, which corresponds to throwing a fair six-sided die, is shown in Figure 3. Since the random variable

The value
Non-Negativity. 
Unit Total Area. 
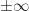
Integrates to a CDF. 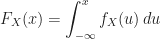
Subinterval Integrals are Probabilities. 
Expectation and Moments
The notion of averaging over time to characterize the gross behavior of a time function is intuitive and we use it a lot in signal processing, and in CSP. You simply add up all the values of the time function over some interval of time ![[t_1, t_2]](https://s0.wp.com/latex.php?latex=%5Bt_1%2C+t_2%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
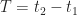

When dealing with a random variable defined on a probability space, there is no time to average over. To find the gross properties of a random variable we must average over the only thing we’ve got: the probability space
The average value of a random variable
![\displaystyle \bar{X} = E[X] = \int_{-\infty}^\infty x f_X(x) \, dx. \hfill (40)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbar%7BX%7D+%3D+E%5BX%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+x+f_X%28x%29+%5C%2C+dx.+%5Chfill+%2840%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
This is a reasonable average because we are taking the probability that the random variable takes on values near 
![E[X]](https://s0.wp.com/latex.php?latex=E%5BX%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Similarly, the expected value of any function of
![\displaystyle E[g(X)] = \int_{-\infty}^\infty g(x) f_X(x) \, dx. \hfill (41)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5Bg%28X%29%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+g%28x%29+f_X%28x%29+%5C%2C+dx.+%5Chfill+%2841%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The most important and useful functions 


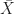
![\displaystyle E[X^2] = \int_{-\infty}^\infty x^2 f_X(x) \, dx. \hfill (42)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX%5E2%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+x%5E2+f_X%28x%29+%5C%2C+dx.+%5Chfill+%2842%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
More useful are the centralized moments, which are the expected values of ![[X - \bar{X}]^n](https://s0.wp.com/latex.php?latex=%5BX+-+%5Cbar%7BX%7D%5D%5En&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle \sigma_X^2 \triangleq E \left[ X - \bar{X} \right]^2 = \int_{-\infty}^\infty (x-\bar{X})^2 f_X(x) \, dx. \hfill (43)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csigma_X%5E2+%5Ctriangleq+E+%5Cleft%5B+X+-+%5Cbar%7BX%7D+%5Cright%5D%5E2+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+%28x-%5Cbar%7BX%7D%29%5E2+f_X%28x%29+%5C%2C+dx.+%5Chfill+%2843%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The square root of the variance is called the standard deviation. An important property of the expectation is that it is linear: ![E[g(X) + h(Y)] = E[g(X)] + E[h(Y)]](https://s0.wp.com/latex.php?latex=E%5Bg%28X%29+%2B+h%28Y%29%5D+%3D+E%5Bg%28X%29%5D+%2B+E%5Bh%28Y%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle \sigma_X^2 = E\left[(X - \bar{X})^2\right] \hfill (44)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csigma_X%5E2+%3D+E%5Cleft%5B%28X+-+%5Cbar%7BX%7D%29%5E2%5Cright%5D+%5Chfill+%2844%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = E\left[ X^2 + \bar{X}^2 -2X\bar{X} \right] \hfill (45)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+E%5Cleft%5B+X%5E2+%2B+%5Cbar%7BX%7D%5E2+-2X%5Cbar%7BX%7D+%5Cright%5D+%5Chfill+%2845%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = E[X^2] + \bar{X}^2 -2\bar{X}E[X] \hfill (46)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+E%5BX%5E2%5D+%2B+%5Cbar%7BX%7D%5E2+-2%5Cbar%7BX%7DE%5BX%5D+%5Chfill+%2846%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = E[X^2] - \bar{X}^2. \hfill (47)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+E%5BX%5E2%5D+-+%5Cbar%7BX%7D%5E2.+%5Chfill+%2847%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
so that the variance is the mean-square minus the squared mean.
Canonical Example: The Uniform Distribution
Quite a few examples of random-variable density functions are provided in the next SPTK post. Here we consider only two: the uniform and the Gaussian. First the uniform, which is simple and so provides clear basic illustrations of the fundamental random-variable characterizations of CDF, PDF, mean, and variance.
The uniform distribution has a PDF that is a rectangle on some interval ![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
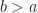

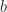

where 

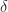

Let’s illustrate the use of the PDF and expectation by calculating the first- and second-order moments for this simple random variable. The mean value is given by
![\displaystyle E[X] = \bar{X} = \int_{-\infty}^\infty x f_X(x) \, dx \hfill (49)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX%5D+%3D+%5Cbar%7BX%7D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+x+f_X%28x%29+%5C%2C+dx+%5Chfill+%2849%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)


which is the midpoint of the interval 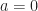

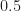
The second moment, or mean-square, is given by
![\displaystyle E[X^2] = \int_{-\infty}^\infty x^2 f_X(x) \, dx \hfill (52)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX%5E2%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+x%5E2+f_X%28x%29+%5C%2C+dx+%5Chfill+%2852%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)



We can use (47) find the variance,

and the standard deviation

These values become quite simple for the rand.m case of
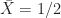
![\displaystyle E[X^2] = 1/3](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX%5E2%5D+%3D+1%2F3&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
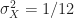
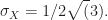
In the next SPTK post we’ll verify these formulas by using MATLAB’s random-number generator and a histogram function.
A Ubiquitous Random Variable: The Gaussian Distribution
From numerous observations of random phenomena, it has been found that many physical processes are well-modeled by using Gaussian random variables. The Gaussian distribution is also known as the normal distribution (because it is so common) and the Gaussian probability density function is the well-known and oft-cited ‘bell-shaped curve.’
The PDF for the Gaussian random variable is explicitly a function of the mean value ![\bar{X} = E[X]](https://s0.wp.com/latex.php?latex=%5Cbar%7BX%7D+%3D+E%5BX%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\sigma_X^2 = E[(X - \bar{X})^2]](https://s0.wp.com/latex.php?latex=%5Csigma_X%5E2+%3D+E%5B%28X+-+%5Cbar%7BX%7D%29%5E2%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

The ubiquity of the Gaussian distribution is due to the interesting fact that when a large number of random variables are added together, the distribution of the resulting sum approaches a Gaussian independently of the particular distributions of the variables. This fact is summarized in the central limit theorem, which we will briefly touch on near the end of the post. The Gaussian PDF and CDF are illustrated in Figure 4. Note that most of the ‘probability action’ lies within one standard deviation of the mean value (about 


More Than One Random Variable: Joint Densities and Correlation
In many situations we are interested in the relationship between two or more random variables. We must therefore generalize our definitions of the cumulative distribution and probability density functions.
Let’s consider two random variables 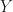
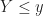
![\displaystyle F_{XY}(x, y) = P \left[ (X \leq x) \cap (Y \leq y) \right]. \hfill (59)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_%7BXY%7D%28x%2C+y%29+%3D+P+%5Cleft%5B+%28X+%5Cleq+x%29+%5Ccap+%28Y+%5Cleq+y%29+%5Cright%5D.+%5Chfill+%2859%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The function 

The properties of 




Expectation works the same way as before,
![\displaystyle E[g(X, Y)] = \int_{-\infty}^\infty \int_{-\infty}^\infty g(x, y) f_{XY}(x,y) \, dx \, dy. \hfill (63)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5Bg%28X%2C+Y%29%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+g%28x%2C+y%29+f_%7BXY%7D%28x%2Cy%29+%5C%2C+dx+%5C%2C+dy.+%5Chfill+%2863%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The expected value of 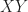

The conditional probability density functions are related to the joint density functions as follows

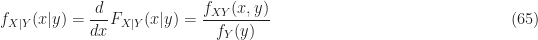


Two random variables

For statistically independent variables, the conditioning makes no difference to the density function

The cross correlation between two statistically independent random variables
![\displaystyle E[XY] = \int_{-\infty}^\infty \int_{-\infty}^\infty xy f_{XY}(x,y) \, dx\, dy, \hfill (70)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BXY%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+xy+f_%7BXY%7D%28x%2Cy%29+%5C%2C+dx%5C%2C+dy%2C+%5Chfill+%2870%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)


If either 
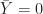
The cross correlation, ![R_{XY} = E[XY]](https://s0.wp.com/latex.php?latex=R_%7BXY%7D+%3D+E%5BXY%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![K_{XY} = E[(X-\bar{X})(Y-\bar{Y})]](https://s0.wp.com/latex.php?latex=K_%7BXY%7D+%3D+E%5B%28X-%5Cbar%7BX%7D%29%28Y-%5Cbar%7BY%7D%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)


![\displaystyle \rho = E\left[ \left(\frac{X-\bar{X}}{\sigma_X}\right) \left(\frac{Y-\bar{Y}}{\sigma_Y}\right) \right], \hfill (73)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Crho+%3D+E%5Cleft%5B+%5Cleft%28%5Cfrac%7BX-%5Cbar%7BX%7D%7D%7B%5Csigma_X%7D%5Cright%29+%5Cleft%28%5Cfrac%7BY-%5Cbar%7BY%7D%7D%7B%5Csigma_Y%7D%5Cright%29+%5Cright%5D%2C+%5Chfill+%2873%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
which is called the correlation coefficient. The correlation coefficient always lies between 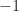





![\displaystyle E[(\alpha \pm \beta)^2] = E[\alpha^2 \pm 2\alpha\beta + \beta^2] \hfill (74)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%28%5Calpha+%5Cpm+%5Cbeta%29%5E2%5D+%3D+E%5B%5Calpha%5E2+%5Cpm+2%5Calpha%5Cbeta+%2B+%5Cbeta%5E2%5D+%5Chfill+%2874%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = E[\alpha^2] \pm 2E[\alpha\beta] + E[\beta^2] \hfill (75)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+E%5B%5Calpha%5E2%5D+%5Cpm+2E%5B%5Calpha%5Cbeta%5D+%2B+E%5B%5Cbeta%5E2%5D+%5Chfill+%2875%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = 1 \pm 2E[\alpha\beta] + 1 = 2 \pm E[\alpha\beta]. \hfill (76)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+1+%5Cpm+2E%5B%5Calpha%5Cbeta%5D+%2B+1+%3D+2+%5Cpm+E%5B%5Calpha%5Cbeta%5D.+%5Chfill+%2876%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Now the correlation coefficient is equal to ![\rho = E[\alpha\beta]](https://s0.wp.com/latex.php?latex=%5Crho+%3D+E%5B%5Calpha%5Cbeta%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle E[(\alpha \pm \beta)^2] = 2 \pm 2\rho = 2(1\pm \rho). \hfill (77)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%28%5Calpha+%5Cpm+%5Cbeta%29%5E2%5D+%3D+2+%5Cpm+2%5Crho+%3D+2%281%5Cpm+%5Crho%29.+%5Chfill+%2877%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
We must have ![E[(\alpha\pm\beta)^2] \ge 0](https://s0.wp.com/latex.php?latex=E%5B%28%5Calpha%5Cpm%5Cbeta%29%5E2%5D+%5Cge+0&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

Therefore the correlation coefficient between any two random variables must always be between 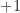

![E[(X-\bar{X})/\sigma_X] = E[(Y-\bar{Y})/\sigma_Y] = 0](https://s0.wp.com/latex.php?latex=E%5B%28X-%5Cbar%7BX%7D%29%2F%5Csigma_X%5D+%3D+E%5B%28Y-%5Cbar%7BY%7D%29%2F%5Csigma_Y%5D+%3D+0&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
At one extreme, if 
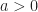

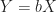

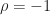

The Central Limit Theorem
Suppose we have a sequence of random variables 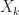


then we’ve simply summed up 

where 

![E[Y_N] = 0](https://s0.wp.com/latex.php?latex=E%5BY_N%5D+%3D+0&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
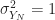


The implication of the central limit theorem is that when a random variable is modeled as the sum of a large number of independent similar events, the distribution of that random variable tends to the Gaussian. A relevant example for the CSP Blog is the electric field value produced by the many electrons in a conductor (thermal noise). Turning to signals, and as a preview, if we consider the reception of a large number of interfering signals at a single radio receiver, we can see that the resulting composite signal will tend to a Gaussian signal no matter the distributions of the involved interferers.
There is a lot more to say about the theory of random variables, and there are many textbooks that treat the topic. I suggest The Literature [R149] and [R156] as good starting points. In the next Signal Processing ToolKit post, we’ll look at several kinds of random variables by using MATLAB to generate them and to investigate their parameters: PDF, mean, variance, correlation, etc.
Significance of Random Variables in CSP
A single random variable, such as that corresponding to a coin toss, a die roll, or even a noise voltage, isn’t central to CSP. As we’ve documented at the CSP Blog, cyclostationary signal processing is about the properties of observable signals, which we conceptualize as functions of time. A random process (also called a stochastic process or a random signal) is what we need to bridge the gap between abstract probability theory and concrete sampled signals.
A random process is a time-indexed collection of random variables (or space-indexed or indexed by any other independent variable, but for us, time-indexed is most appropriate). It is associated with a probability space, just like a random variable. We’ll look into random processes in a future SPTK post. Cyclostationary signals are most often defined as a certain class of random process. I use ‘cyclostationary signal’ instead of ‘cyclostationary random process’ on the CSP Blog because I want to emphasize signal processing rather than probability theory; we’re practitioners here.
Note that the correlation between random variables is used in the spectral correlation function, and that the spectral coherence function is a correlation coefficient. The temporal moment function is a higher-order moment that happens to be periodically time varying, and so has Fourier series coefficients that are the cyclic temporal moments. All of this is connected to cumulants and cyclic cumulants, and cyclic polyspectra too, but we’ll wait to make that connection concrete until we introduce the Fourier transform of the probability density function, which is called the characteristic function.
Previous SPTK Post: Complex Envelopes Next SPTK Post: Examples of Random Variables
Hello! Last term of (11) shouldn’t be P(A) ?
Thanks! 🙂
Yes! Thanks much Rob…