
Previous SPTK Post: Examples of Random Variables Next SPTK Post: The Sampling Theorem
In this Signal Processing ToolKit post, I provide an introduction to the concept and use of random processes (also called stochastic processes). This is my perspective on random processes, so although I’ll introduce and use the conventional concepts of stationarity and ergodicity, I’ll end up focusing on the differences between stationary and cyclostationary random processes. The goal is to illustrate those differences with informative graphics and videos; to build intuition in the reader about how the cyclostationarity property comes about, and about how the property relates to the more abstract mathematical object of a random process on one hand and to the concrete data-centric signal on the other.
So … this is the first SPTK post that is also a CSP post.
Jump straight to ‘Significance of Random Processes in CSP’ below.
Introduction
We started our signal-processing toolkit journey by looking at signals, including rectangles, triangles, unit-steps, sinc, etc. We then looked at representing arbitrary signals of time in terms of building-block functions such as Walsh functions, impulses, and harmonically related sine waves. The latter led us to the useful frequency-domain signal representations of the Fourier series and Fourier transform.
We shifted focus to systems–those entities that act on our signals to achieve some goal–and found that our analysis tools enabled much insight into system behavior if the system was linear and time-invariant. We added the crucial tool of convolution to our toolkit, and looked at various kinds of linear time-invariant systems, also known as filters.
We then realized that many of our most important signals (in CSP) don’t quite fit into our analysis framework. In particular, communication signals are well-modeled as random infinite-duration power signals, which are not Fourier transformable. So we started learning probability.
The concept of a random variable bridges the gap between an abstract probability space of events and sets of measurements or numbers that we can operate on with arithmetic, algebra, calculus, and associated computing devices. But random variables are not functions of time. Communication signals are. So we now take the next logical step: going from a random variable to a random function or, as it is more commonly referred to, a random process.
How should we generalize the concept of a signal to include both probability and infinite time? We need infinite time because we want to study our systems’ behavior for arbitrarily long-duration inputs. We need probability because the signals we use in communication theory and practice are inherently unpredictable–they are random.
A useful model of a communication signal is an infinite-duration signal that incorporates some parameters or variables that are in some sense unknown to a receiver of the signal:
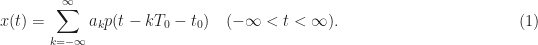
Here 


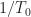
It is possible to use such a model–a single infinite-duration random signal–to construct an entire probabilistic theory of signals. That theory is the fraction-of-time (FOT) probability theory, and I hope to get to that in the SPTK series, or in a CSP post. A more conventional way, and a way that is somewhat easier mathematically even if more obscure physically, is to use a generalization of our previous notion of a probability space.
Probability
A random process is a collection of random variables indexed by time. It is actually more general than that. The indexing can be some other independent variable, such as distance. But for us, swimming in the deep waters of CSP, our random processes are indexed by time 
We use the notation 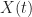



Given the definition of a random process, it follows that the random variable 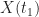



The joint PDF for the two random variables 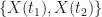
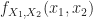
All the usual probability and random-variable definitions and tools apply.
For random variables, a particular occurrence of the variable, such as the outcome of a particular card draw or die throw, is called an instance or sample of the variable. For a random process, a particular occurrence of the process is a function, and we call it, variously, a sample path, a sample function, a time-series, or a signal.
Moments
Suppose we have knowledge of a random process 


![\displaystyle M_X(t_j) = E[X(t_j)] = \int_{-\infty}^\infty x f_{X_{t_j}}(x) \, dx, \hfill (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_X%28t_j%29+%3D+E%5BX%28t_j%29%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+x+f_%7BX_%7Bt_j%7D%7D%28x%29+%5C%2C+dx%2C+%5Chfill+%282%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
and any particular 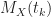

Similarly, we can look at the correlation between two elements of the random process,
![\displaystyle R_X(t_1, t_2) = E[X(t_1) X(t_2)], \hfill (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R_X%28t_1%2C+t_2%29+%3D+E%5BX%28t_1%29+X%28t_2%29%5D%2C+%5Chfill+%283%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
which may turn out to be independent of 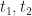

The covariance is the correlation of the two variables after their means are removed,
![\displaystyle K_X(t_1, t_2) = E[(X(t_1)-M_X(t_1))(X(t_2)-M_X(t_2))], \hfill (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+K_X%28t_1%2C+t_2%29+%3D+E%5B%28X%28t_1%29-M_X%28t_1%29%29%28X%28t_2%29-M_X%28t_2%29%29%5D%2C+%5Chfill+%284%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
as usual.
In many cases we don’t actually know the densities (PDFs) of the process itself. However, this is often no barrier to finding the mean, autocorrelation, and covariance functions. Suppose we have a random process that is characterized by a couple specific random variables, such as a sine-wave phase or amplitude. Then we can consider 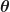
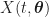
Example: The Random-Phase Sine Wave
Let’s consider the random process defined by

Here 
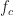
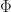


What is the mean value of this random process? Is it a function of time?
![\displaystyle M_X(t) = E[X(t)] \hfill (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_X%28t%29+%3D+E%5BX%28t%29%5D+%5Chfill+%286%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = E[A\cos(2 \pi f_c t + \Phi)]. \hfill (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+E%5BA%5Ccos%282+%5Cpi+f_c+t+%2B+%5CPhi%29%5D.+%5Chfill+%287%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
To evaluate the expectation in (6) requires the joint distribution of all involved random variables. Since there is only one,
The mean value, also known as the first moment of
![\displaystyle M_X(t) = E[X(t)], \hfill (8)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_X%28t%29+%3D+E%5BX%28t%29%5D%2C+%5Chfill+%288%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
which may be a function of 


This definite integral is easily evaluated,
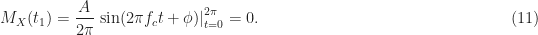
Since 
The reason the mean is zero for each and every time instant is that we are averaging over the ensemble of sample functions, where each sample function is delayed by some amount 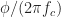

Now let’s look at the autocorrelation function for the random-phase sine wave. We want to find the average value of the product of two values of the process,
![\displaystyle R_X(t_1, t_2) = E[X(t_1)X(t_2)]. \hfill (12)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R_X%28t_1%2C+t_2%29+%3D+E%5BX%28t_1%29X%28t_2%29%5D.+%5Chfill+%2812%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Normally we (and many others) reparameterize the two times 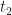



Our autocorrelation is
![\displaystyle R_X(t_1, t_2) = E[A\cos(2\pi f_c t_1 + \Phi) A\cos(2 \pi f_c t_2 + \Phi)] \hfill (13)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R_X%28t_1%2C+t_2%29+%3D+E%5BA%5Ccos%282%5Cpi+f_c+t_1+%2B+%5CPhi%29+A%5Ccos%282+%5Cpi+f_c+t_2+%2B+%5CPhi%29%5D+%5Chfill+%2813%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = \frac{A^2}{2} E[\cos(2\pi f_c t_1 - 2\pi f_c t_2) + \cos(2\pi f_c t_1 + 2\pi f_c t_2 + 2\Phi)] \hfill (14)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cfrac%7BA%5E2%7D%7B2%7D+E%5B%5Ccos%282%5Cpi+f_c+t_1+-+2%5Cpi+f_c+t_2%29+%2B+%5Ccos%282%5Cpi+f_c+t_1+%2B+2%5Cpi+f_c+t_2+%2B+2%5CPhi%29%5D+%5Chfill+%2814%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = \frac{A^2}{2} \cos(2\pi f_c(t_1-t_2)) + \frac{A^2}{2} \underbrace{E [\cos(2\pi f_c(t_1+t_2) + 2\Phi)]}_{=\ 0 \mbox{\rm \ for\ similar\ reasons\ as } M(t) = 0} \hfill (15)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cfrac%7BA%5E2%7D%7B2%7D+%5Ccos%282%5Cpi+f_c%28t_1-t_2%29%29+%2B+%5Cfrac%7BA%5E2%7D%7B2%7D+%5Cunderbrace%7BE+%5B%5Ccos%282%5Cpi+f_c%28t_1%2Bt_2%29+%2B+2%5CPhi%29%5D%7D_%7B%3D%5C+0+%5Cmbox%7B%5Crm+%5C+for%5C+similar%5C+reasons%5C+as+%7D+M%28t%29+%3D+0%7D+%5Chfill+%2815%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
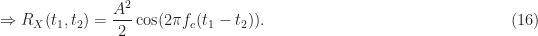
So the mean is independent of time, being identically zero, and the autocorrelation is a function only of the difference between the two considered times 
What happens when we try to compute the first and second moments (mean and autocorrelation) using only a single sample path? We (and I mean mathematicians, engineers, and statisticians) define the mean and autocorrelation by infinite-time averages in such situations. The mean is just the infinite-time average,
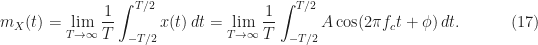
Here 
The time-average autocorrelation is typically defined as the following infinite-time average
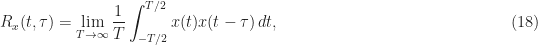
where we recognize that 
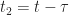



which does not depend on time, and which cannot depend on time, since we integrated over time to obtain the average.
Notice that the ensemble mean matches the time-average mean (zero), and that the ensemble correlation matches the time-average correlation. Does this always happen? No. The ways the two kinds of average can diverge are important, and depend on the particular random variables involved.
For example, consider a different random process given by

where ![[-B, B]](https://s0.wp.com/latex.php?latex=%5B-B%2C+B%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
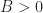
![\displaystyle M_X(t) = E[X(t)] = E[A\cos(2\pi f_c t + \phi)] \hfill (23)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_X%28t%29+%3D+E%5BX%28t%29%5D+%3D+E%5BA%5Ccos%282%5Cpi+f_c+t+%2B+%5Cphi%29%5D+%5Chfill+%2823%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = \cos(2\pi f_c t + \phi) E[A] \hfill (24)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Ccos%282%5Cpi+f_c+t+%2B+%5Cphi%29+E%5BA%5D+%5Chfill+%2824%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)




On the other hand, the temporal mean of some sample path where ![a \in [-B, B]](https://s0.wp.com/latex.php?latex=a+%5Cin+%5B-B%2C+B%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

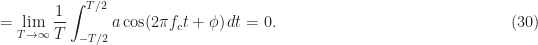
So, as with the random phase, the mean of this random-amplitude sine wave is zero (but what if the distribution of ![[0, 2B]](https://s0.wp.com/latex.php?latex=%5B0%2C+2B%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Next let’s compute and compare the probabilistic (ensemble-average) autocorrelation with the temporal (time-average) autocorrelation.
The probabilistic autocorrelation is
![\displaystyle R_X(t_1, t_2) = E[X(t_1)X(t_2)] \hfill (31)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R_X%28t_1%2C+t_2%29+%3D+E%5BX%28t_1%29X%28t_2%29%5D+%5Chfill+%2831%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = E[A^2] \cos(2\pi f_c t_1 + \phi)\cos(2\pi f_c t_2 + \phi) \hfill (32)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+E%5BA%5E2%5D+%5Ccos%282%5Cpi+f_c+t_1+%2B+%5Cphi%29%5Ccos%282%5Cpi+f_c+t_2+%2B+%5Cphi%29+%5Chfill+%2832%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)



If we let

which is a function of both 
On the other hand, the temporal correlation is

which is not–cannot be–a function of time
Averaging Over the Ensemble vs Over Time
Let’s take a closer look at the differences and similarities between ensemble and temporal averages using a prototypical communication signal: binary pulse-amplitude modulation (PAM) with rectangular pulses. The signal is defined by

where 
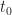
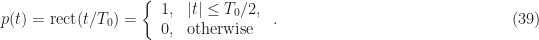
The symbols are independent and identically distributed–the 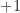
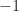
It is relatively easy to show that the mean value of this random process is zero and that the autocorrelation function is dependent on the nature of the symbol-clock phase random variable
When the symbol-clock phase variable is a constant (nonrandom), the autocorrelation is a periodic function of time; we have a cyclostationary process. When the symbol-clock phase variable is a uniform random variable on an interval with width 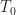
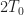
Let’s illustrate these claims using calculations on simulated versions of (38). We can do both ensemble (probabilistic) averaging and single-sample-path (temporal) averaging, approximately, because we can generate a sizeable ensemble, and each sample path can be made quite long (length equal to many thousands times
Figure 2 shows a portion of an ensemble of rectangular-pulse PAM sample paths for the case of a random phase variable

 and
and 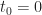 . Each sample path (function of time) in the ensemble is a rectangular-pulse binary PAM signal with the same symbol-transition instants (‘the same timing’). When we ‘average over the ensemble,’ we average quantities vertically in terms of this graphical representation of the ensemble. When we ‘average over time,’ we pick one of the sample paths and perform some time average using just that signal.
. Each sample path (function of time) in the ensemble is a rectangular-pulse binary PAM signal with the same symbol-transition instants (‘the same timing’). When we ‘average over the ensemble,’ we average quantities vertically in terms of this graphical representation of the ensemble. When we ‘average over time,’ we pick one of the sample paths and perform some time average using just that signal.We can use this non-infinite ensemble to approximate the kinds of ensemble averaging we do with math. For example, we can pick some time 

If we pick two times, 
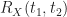
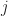


 for fixed and the ensemble shown in Figure 2.
for fixed and the ensemble shown in Figure 2.When we turn to a time average of a single sample path in the ensemble of Figure 2, we get a much different result, as shown in Figure 4. Moreover, this is the same result we get for any of the sample paths–it does not vary with the index
 (nonrandom symbol-clock phase).
(nonrandom symbol-clock phase).The autocorrelation function estimate for the case of no phase variable in Figures 3 and 4 depends on
). Notice that the variation with is periodic.Another way of looking at the time variation of the ensemble-average autocorrelation is by fixing the difference 
 for ensemble averaging the no-symbol-clock-phase ensemble for each of a number of fixed values of . Each autocorrelation estimate is periodic, but they are different periodic functions, and so will have different Fourier-series coefficients. Once the difference exceeds the symbol period , the correlation between two samples in the ensemble is zero.
for ensemble averaging the no-symbol-clock-phase ensemble for each of a number of fixed values of . Each autocorrelation estimate is periodic, but they are different periodic functions, and so will have different Fourier-series coefficients. Once the difference exceeds the symbol period , the correlation between two samples in the ensemble is zero.Now let’s look at these same estimated quantities for the ensemble we generated with a uniform random phase variable
 and a uniformly distributed random symbol-clock phase . Each sample path (function of time) in the ensemble is a rectangular-pulse binary PAM signal with the same symbol-transition instants governed by the particular value of for that path (‘different timing’).
and a uniformly distributed random symbol-clock phase . Each sample path (function of time) in the ensemble is a rectangular-pulse binary PAM signal with the same symbol-transition instants governed by the particular value of for that path (‘different timing’). Figure 7 shows the correspondence between the ensemble-average autocorrelation function and the temporal-average autocorrelation for the random-phase ensemble. Here the two match; you get the same answer whether you average over the ensemble or over time.
 is uniform on
is uniform on ![[0, T_0]](https://s0.wp.com/latex.php?latex=%5B0%2C+T_0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) ).
). Figure 8 shows that the ensemble-average autocorrelation is a function of 

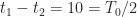
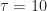
 for ensemble averaging the random-symbol-clock-phase ensemble for each of a number of fixed values of . Each autocorrelation estimate is constant–the individual values of and don’t matter–just their difference. Once the difference exceeds the symbol period , the correlation between two samples in the ensemble is zero.
for ensemble averaging the random-symbol-clock-phase ensemble for each of a number of fixed values of . Each autocorrelation estimate is constant–the individual values of and don’t matter–just their difference. Once the difference exceeds the symbol period , the correlation between two samples in the ensemble is zero.Stationarity
When the probabilistic functions of a random process are independent of time, the process possesses a kind of time-invariance that is called stationarity. This property is reminiscent of the all-important system property of time-invariance that we made use of in characterizing linear systems. Systems that are linear and time-invariant are filters, and signals that are time-invariant are stationary, loosely speaking. Of course the signal isn’t actually a constant as a function of time, it is the underlying ensemble that possesses the time-invariance in its statistical functions–stationarity. But we still speak of ‘stationary signals’ in day-to-day work.
There are kinds of stationary random processes. The stricter kind requires all probabilistic parameters (all moments) to be time-invariant. The weaker kind requires only the first two moments to be time-invariant. This latter kind of stationarity is known as wide-sense stationarity (WSS). Remember, stationarity of any kind is a property of a random process–an ensemble together with a set of joint PDFs for all choices of
Strict-sense stationarity is hard to check because you have to have a simple enough process, and the time, to be able to check all the moments (or PDFs). Wide-sense stationarity saves us from this hassle: we need only check the mean and autocorrelation.
For a wide-sense stationary (WSS) process, the mean must be a constant,
![\displaystyle M_X(t_1) = E[X(t_1)] = M, \hfill (40)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_X%28t_1%29+%3D+E%5BX%28t_1%29%5D+%3D+M%2C+%5Chfill+%2840%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
and the autocorrelation is a function only of the time difference between the two involved times
![\displaystyle R_X(t_1, t_2) = E[X(t_1)X^*(t_2)] = R_X(t_1-t_2). \hfill (41)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R_X%28t_1%2C+t_2%29+%3D+E%5BX%28t_1%29X%5E%2A%28t_2%29%5D+%3D+R_X%28t_1-t_2%29.+%5Chfill+%2841%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
We’ve abused the notation a bit in (41): we’re using 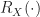

For our two PAM ensembles, only one is wide-sense stationary, and that is the one with the random-phase variable. The other ensemble produces a time-varying autocorrelation (second moment), and is therefore neither wide-sense nor strict-sense stationary.
On the other hand, the sample paths of each of the ensembles are cyclostationary signals. That is, if we compute the cyclic autocorrelation function for 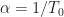
Ergodicity
Ergodicity is a property of a random process that ensures that the time-averages of the sample paths correspond to the ensemble averages. This is the property that mathematicians must invoke so that they can pursue actual real-world utility of the ensemble sample paths.
Ergodic random processes must be stationary because the time averages of sample paths are, by construction, not functions of time. Therefore, if those averages have any chance to match the ensemble averages, those ensemble averages also cannot be functions of time, and so the process must be stationary.
Our ensemble with the random-phase variable is stationary and ergodic because the mean and the autocorrelation functions in ensemble- and temporal-averaging agree.
Cyclostationarity
A wide-sense cyclostationary random process is one for which the mean and autocorrelation are periodic (or almost-periodic) functions of time, rather than being time-invariant.
A second-order cyclostationary signal, or cyclostationary time-series, is simply a signal for which the infinite-time average defined by

or that defined by

is not identically zero for all non-trivial cycle frequencies 

It is perfectly possible that there are no non-trivial cycle frequencies for which either the non-conjugate cyclic autocorrelation function 
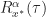
Cycloergodicity
If we do have a cyclostationary random process, and we want to use stochastic machinery to, say, derive an algorithm, we will also want to know whether the sample paths of that cyclostationary random process are cyclostationary, and that they possess the same cyclic parameters as the process. This is done by checking for, or invoking, cycloergodicity.
For ergodicity, we check the ensemble-average mean value against the temporal-average mean value for a sample path,
![\displaystyle M_X(t) = E[X(t)] \stackrel{?}{=} \left\langle x(t) \right\rangle, \hfill (44)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_X%28t%29+%3D+E%5BX%28t%29%5D+%5Cstackrel%7B%3F%7D%7B%3D%7D+%5Cleft%5Clangle+x%28t%29+%5Cright%5Crangle%2C+%5Chfill+%2844%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
and we check the ensemble-average second moment against the temporal-average second moment,
![\displaystyle R_X(t_1,t_2) = E[X(t+t_1)X^*(t+t_2)] \stackrel{?}{=} R_X(t_1-t_2) \stackrel{?}{=} \left\langle x(t+t_1)x^*(t+t_2) \right\rangle. \hfill (45)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%C2%A0+R_X%28t_1%2Ct_2%29+%3D+E%5BX%28t%2Bt_1%29X%5E%2A%28t%2Bt_2%29%5D+%5Cstackrel%7B%3F%7D%7B%3D%7D+R_X%28t_1-t_2%29+%5Cstackrel%7B%3F%7D%7B%3D%7D+%5Cleft%5Clangle+x%28t%2Bt_1%29x%5E%2A%28t%2Bt_2%29+%5Cright%5Crangle.+%5Chfill+%2845%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
For cycloergodicity, we need a new tool involving time averages to compare with the time-varying ensemble-average autocorrelation. This is the fraction-of-time (FOT) expectation, also called the multiple-sine-wave extractor (or similar), ![\displaystyle E^{\{\alpha\}} [\cdot]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5E%7B%5C%7B%5Calpha%5C%7D%7D+%5B%5Ccdot%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
For now, a couple examples should suffice to illustrate the idea. The FOT mean value of a single sine wave is just that sine wave
![\displaystyle E^{\{\alpha\}} [Ae^{i 2 \pi f_0 t + i \phi_0}] = Ae^{i 2 \pi f_0 t + i \phi_0}. \hfill (46)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5E%7B%5C%7B%5Calpha%5C%7D%7D+%5BAe%5E%7Bi+2+%5Cpi+f_0+t+%2B+i+%5Cphi_0%7D%5D+%3D+Ae%5E%7Bi+2+%5Cpi+f_0+t+%2B+i+%5Cphi_0%7D.+%5Chfill+%2846%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
(Compare that with the usual temporal average applied to a sine wave.)
Suppose we have a periodic function 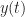

The FOT sine-wave extractor is linear, so that again we have
![\displaystyle E^{\{\alpha\}}[y(t)] = y(t). \hfill (48)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5E%7B%5C%7B%5Calpha%5C%7D%7D%5By%28t%29%5D+%3D+y%28t%29.+%5Chfill+%2848%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Suppose some periodic signal

Then
![\displaystyle E^{\{\alpha\}}[z(t)] = y(t). \hfill (50)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5E%7B%5C%7B%5Calpha%5C%7D%7D%5Bz%28t%29%5D+%3D+y%28t%29.+%5Chfill+%2850%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
To check the cycloergodic property of a random process, we check the ensemble-average mean value against the FOT mean value
![\displaystyle M_X(t) = E[X(t)] \stackrel{?}{=} E^{\{\alpha\}}[x(t)]. \hfill (51)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_X%28t%29+%3D+E%5BX%28t%29%5D+%5Cstackrel%7B%3F%7D%7B%3D%7D+E%5E%7B%5C%7B%5Calpha%5C%7D%7D%5Bx%28t%29%5D.+%5Chfill+%2851%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Note that in (51), the ensemble average on the left and the temporal (non-stochastic) average on the right can be functions of time
![\displaystyle R_X(t+t_1, t+t_2) = E[X(t+t_1)X^*(t+t_2)] \stackrel{?}{=} E^{\{\alpha\}}[x(t+t_1)x^*(t+t_2)]. \hfill (52)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R_X%28t%2Bt_1%2C+t%2Bt_2%29+%3D+E%5BX%28t%2Bt_1%29X%5E%2A%28t%2Bt_2%29%5D+%5Cstackrel%7B%3F%7D%7B%3D%7D+E%5E%7B%5C%7B%5Calpha%5C%7D%7D%5Bx%28t%2Bt_1%29x%5E%2A%28t%2Bt_2%29%5D.+%5Chfill+%2852%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
If these averages match, and the process is cyclostationary, then we say the process is a cycloergodic process.
From this point of view, then, the random process corresponding to the PAM ensemble with a uniform random phase variable is stationary, ergodic, and non-cycloergodic. The autocorrelation functions obtained from ensemble averaging match those obtained from the sample paths (almost surely), and the ensemble and temporal means are zero. We end up with strong observable (sample-path-based) cyclic features, but no cyclic features in the stochastic domain, as illustrated in Figure 9.

On the other hand, if we perform the same operations on the ensemble and sample paths using the ensemble without phase randomization, we see that the cyclic features match (Figure 10). This process is cyclostationary, nonergodic, and cycloergodic.
 . By refusing to add random-phase variables to our random-process signal model, we accept nonstationarity, but we gain cycloergodicity.
. By refusing to add random-phase variables to our random-process signal model, we accept nonstationarity, but we gain cycloergodicity.The properties of the two PAM random processes we have studied in this post are summarized in Table 1.
| Property | PAM with no Symbol-Clock Phase (  Constant) Constant) | PAM with Random Symbol-Clock Phase ( Uniform on ) |
| Zero Mean Process? | Yes | Yes |
| Stationary Process? | No | Yes |
| Cyclostationary Process? | Yes | No |
| Ergodic Process? | No | Yes |
| Cycloergodic Process? | Yes | No |
| Stationary Sample Paths? | No | No |
| Cyclostationary Sample Paths? | Yes | Yes |
This was a complex, difficult post. I’m sure there are errors. If you find one, please let me know in the Comments.
Significance of Random Processes in CSP
The theory of cyclostationary signals can be formulated in terms of conventional non-stationary random processes, and so from that point of view, random processes are central to CSP. To bridge the gap between a random process (infinite collection of time-series of infinite durations together with a set of probability density functions for all possible collections of random variables plucked from the process) and a signal (one infinite-time member of the ensemble), we need to invoke a kind of ergodicity called cycloergodicity.
A good way to achieve cycloergodicity is to refrain from adding random variables to the random process model that attempt to account for what are simply unknown constants in a given sample path. For instance, refrain from adding random symbol-clock phases and random carrier phases. This will render the process non-stationary (cyclostationary), but will also lead to cycloergodicity. Include random variables in the random process that are models of quantities that also randomly vary in a single sample path–such as transmitted symbols in a PSK or QAM signal.
It is possible to formulate a theory of cyclostationary signals that completely sidesteps the creation of a random process (ensemble plus probability rules). What is needed is a way to characterize the random (erratic, unpredictable) behavior of a signal using only infinite-time averages. This leads to the idea of a fraction-of-time probability to take the place of the ensemble probability. We’ll look at that in a future CSP post.
Previous SPTK Post: Examples of Random Variables Next SPTK Post: The Sampling Theorem