
Or maybe “Comments on” here should be “Questions on.”
In a recent paper in EURASIP Journal on Advances in Signal Processing (The Literature [R165]), the authors tackle the problem of machine-learning-based modulation recognition for highly oversampled rectangular-pulse digital signals. They don’t use the DeepSig datasets (one, two, three, four), but their dataset description and use of ‘signal-to-noise ratio’ leaves a lot to be desired. Let’s take a brief look. See if you agree with me that the touting of their results as evidence that they can reliably classify signals with ‘SNRs of 
First, let me give credit where credit is due. These authors put the results of O’Shea et al (The Literature [R138]) in proper perspective:
O’Shea et al [18] trained the CNN with the received base banded [sic] signals directly, and the classification accuracy was higher than those trained by HOC features.
All other summations of O’Shea et al say that they compared the I/Q-samples trained CNNs with conventional modulation-recognition techniques, and the latter came out poorly indeed. However, O’Shea et al (and no machine learners that I know about) never even attempted to compare the performance of a trained neural network with an actual signal-processing algorithm for modulation recognition. I’ll leave you to your own thoughts about why that may be. They simply wrote down some garbled versions of extractable statistics and threw those into the machine.
But on to the main issue at hand: SNR. In Section 2 of [R165], the authors lay out their signal models, including this one for MASK, MFSK, and MPSK:


(Which doesn’t actually work for MFSK because the 

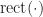
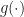
The OFDM signal is incorrectly defined by some indefinite sum of sine waves (there is no machinery to produce OFDM symbols),

Later we are told there are 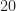
So, not exactly realistic signal types here. But I think we readers get the idea, and I am hopeful that the simulation of the various signals has a higher quality that the provided mathematical descriptions. Although I have no way to check.
Unlike many signal-processing papers, the authors do explicitly define their SNR measure,

which is what we at the CSP Blog call ‘total SNR’, in contrast to our favored definition, which is ‘inband SNR.’ The latter is the ratio of the signal power to the power of the noise that falls within the signal band, whereas the former is the ratio of the signal power to the power of the noise that falls within the sampling band (also called the analysis band).
For sampled signals with large fractional bandwidth, which means the signal bandwidth is a large fraction of the sampling rate, the two measures are not too far off from each other. But when the fractional bandwidth is small, they can be very different. What’s the case here? Well, here are the stated signal parameter values for the dataset the authors generate for input to the neural network:

Unfortunately, the symbol used to define the symbol rate in the signal-model section, 

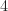
The ratio of the signal bandwidth to the sample rate is then 
Yes, you say, but the processor acts on the entire waveform, and so ‘sees’ the total SNR. Sure. But what matters, I argue (and here is the crux of the question), is the inband SNR. For you can easily detect the presence of a 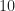
The authors provide results like this:

Which seem to indicate good performance for low SNR–after all, the left side of the plot is labeled with a negative SNR. But that SNR actually corresponds to an inband SNR of
If we increased the sampling rate to 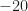
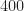
I read the graph above in light of the signal and SNR definitions and think: OK, cool, good performance can be had once the inband SNR gets to about
In other words, the joint use of very high oversampling and total SNR allows the appearance of processing signals at low SNR, without the actual processing of weak signals.
Resumé padding? Or is this fair?
Talking about the “total SNR” is quite common. E.g. in amateur radio it is said that the JT weak signal modes work at -25 dB SNR and below. This is of course only true because the signal bandwidth (few 10 Hz) is a small fraction of the typically used 3 kHz bandwidth.
But isn’t this perfectly fine for a practical system? Rearding the discussed paper: A 400 MHz ADC has typically a lot higher noise figure than a 4 MHz ADC. So the question is always how and where in the system you define the SNR: Before the ADC, after the ADC, after reducing the sample rate to the desired signal? What if the sample rate cannot perfectly be reduced to the actual signal?
So I would think that total vs inband SNR is perhabs a more theory-related issue.
So is resume-padding.
Sure, although here we are talking about a digital signal processing subsystem.
Well, since we’re talking about processing a discrete-time signal, after the antenna, receiver, ADC, I’d say it is pretty clear that it should be at the input to the signal-processing algorithm. DSP Engineer 1: “Hey, I can successfully process these signals at -10 dB SNR!” DSP Engineer 2: “Uh, do you mean the SNR at the input to the ADC?” Not a likely conversation.
I’m not clear on what this means. Do you mean that a system operator cannot select a sampling rate that is exactly equal to the occupied bandwidth of the signal of interest? No problem! That’s why inband SNRs are so helpful. All that matters is specifying the amount of noise power that falls within the signal bandwidth, irrespective of the sampling rate.
I think it is a communication issue–an issue of writing and speaking with the intent to clearly convey technical information. The issue applies equally well to theoretical analyses and their write-ups and practical experimentation and its write-ups.
Suppose we consider the parameters of the paper, but change the symbol rate from 2 MHz to 20 kHz, reducing it by a factor of 100. The total SNR is unchanged, but the inband SNR is now 20 dB higher. Is it a good practice to label these two situations with the same name: SNR = X dB?