
Update October 2020:
Since I wrote the paper review in this post, I’ve analyzed three of O’Shea’s data sets (O’Shea is with the company DeepSig, so I’ve been referring to the data sets as DeepSig’s in other posts): All BPSK Signals, More on DeepSig’s Data Sets, and DeepSig’s 2018 Data Set. The data set relating to this paper is analyzed in All BPSK Signals. Preview: It is heavily flawed.
In this post I provide some comments on another paper I’ve seen on arxiv.org (I have also received copies of it through email) that relates to modulation classification and cyclostationary signal processing. The paper is by O’Shea et al and is called “Convolutional Radio Modulation Recognition Networks.” (The Literature [R138]) You can find it at this link.
My main interest in commenting on this paper is that it makes reference to cyclic moments as good features for modulation recognition. Although I think cyclic cumulants are a much better way to go, we do know that for order 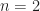
Let’s start with Section 2.1, titled “Expert Cyclic-Moment Features.” We have the quote:
Integrated cyclic-moment based features [1] are currently widely popular in performing modulation recognition and for forming analytically derived decision trees to sort modulations into different classes.
In general, they take the form given in equation 3
By computing the mth order statistic on the nth power of the instantaneous or time delayed received signal
, we may obtain a set of statistics which uniquely separate it from other modulations given a decision process on the features. For our expert feature set, we compute 32 features. These consist of cyclic time lags of 0 and 8 samples. And the first 2 moments of the first 2 powers of the complex received signal, the amplitude, the phase, and the absolute value of the phase for each of these lags.

And that’s all that they say about “expert cyclic-moment features.”
I’m not at all sure what they mean, but I think I am an expert in cyclic moments. So I’m going to take take the quote from Section 2.1 seriously for a moment to see if there is an interpretation that is charitable.
In the quote, reference [1] is my paper with Gardner My Papers [1], which is titled “Signal Interception: Performance Advantages of Cyclic Feature Detectors,” which is all about the cycle detectors, not modulation classification. And it says nothing about moments with orders higher than two except we intend to study their effectiveness in the future. So the first part of the quote doesn’t make much sense.
Now let’s look at Equation (3). I’ve looked through the paper several times, but I cannot find a definition of 
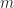

But then 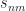
On the right side of (3), what is 


Perhaps
I couldn’t find any other mentions of
So let’s now ignore (3) and focus on the words that follow it: “And the first 2 moments of the first 2 powers of the complex received signal …” Let’s let the received data be denoted by

and

The first moments of the first two powers are then
![\displaystyle z_1(t) = E[y_1(t)] = E[r(t)] \hfill (D)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+z_1%28t%29+%3D+E%5By_1%28t%29%5D+%3D+E%5Br%28t%29%5D+%5Chfill+%28D%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
and
![\displaystyle z_2(t) = E[y_2^2(t)] = E[r^2(t)] \hfill (E)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+z_2%28t%29+%3D+E%5By_2%5E2%28t%29%5D+%3D+E%5Br%5E2%28t%29%5D+%5Chfill+%28E%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The moment 
The second moments of the first two powers are
![\displaystyle z_3(t) = E[y_1^2(t)] = z_2(t) \hfill (F)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+z_3%28t%29+%3D+E%5By_1%5E2%28t%29%5D+%3D+z_2%28t%29+%5Chfill+%28F%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
and
![\displaystyle z_4(t) = E[y_2^2(t)] = E[r^4(t)] \hfill (G)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+z_4%28t%29+%3D+E%5By_2%5E2%28t%29%5D+%3D+E%5Br%5E4%28t%29%5D+%5Chfill+%28G%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
And I suppose all of these with one or more of the factors delayed by 
Out of the four quantities, two are redundant, one is typically zero for the signals of interest to the authors, and the last one is the expected value of the fourth power of the signal. This is what we call here on the CSP Blog the “(4,0) moment”, because the order 
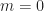
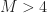
Where are the conjugations?
Later in the paper, the authors describe their simulated signals, and they say
“Data is modulated at a rate of roughly 8 samples per symbol with a normalized average transmit power of 0 dB.”
Now if they use 
So, in the end, I can’t see how the section on Expert Cyclic-Moment Features lives up to its name.
Much of the rest of the paper is devoted to applying machine learning tools to a large simulated data set, and there are confusing issues there too, but I digress. There are a few more instances of strange comments relating to signals and their properties:
“We treat the complex valued input as an input dimension of 2 real valued inputs and use
vectors into a narrow 2D Convolutional Network where the orthogonal synchronously sampled In-Phase and Quadrature (I & Q) samples make up this 2-wide dimension.”
In Figure 2 (which is quite tiny), the authors show high-SNR PSDs for some of their generated signals. BPSK appears to contain a tone (is it really OOK?), AM-SSB appears to span the entire sampling bandwidth, and WBFM looks like a sine wave.

In explaining how 8PSK might be confused for QPSK,
“An 8PSK symbol containing the specific bits is indiscernible from QPSK since the QPSK constellation points are spanned by 8PSK points.”
But QPSK is not confused for BPSK here, and yet the BPSK constellation points are spanned by the QPSK points.
I think we get to the real motivation for the paper in the last sentence of the section on Future Work:
“This application domain is ripe for a wide array of further investigation and applications which will significantly impact the state of the art in wireless signal processing and cognitive radio domains, shifting them more towards machine learning and data driven approaches.”
I would welcome this conclusion, and the new research avenues, if it was based on a study that accurately represented what has come before.
Chad,
We’ve implemented a much more rigorous version of your excellent prior work as a baseline in this more recent paper on the topic https://arxiv.org/abs/1702.00832. Including all possible combinations of conjugations for the orders considers and a very strong boosted tree classifier operating on them. I appreciate your harping on semantics and minutia within a preliminary conference paper (the term “Expert … Features” is quite, the feature extractors are derived by an expert to do one specific thing) — we make an effort to leverage your work but do not wish to make it the main focus of discussion in this paper (as you’ve shown it takes a lot of time and detail to explain the careful manual feature engineering required which would take up the whole paper) as we are simply exploring a new approach here — if there were better open source tools and implementations of your work and the datasets, perhaps we could advance the community as a whole, and more easily baseline against your best practice, recall we are not all extreme experts in high order moment engineering. Rather than critiquing the dataset, feel free to send pull requests to the github repository and help improve it so we can all have a good baseline to compare with, if you feel I’ve not done justice to your work, please release quantitative results and a reference implementation we can compare against. I’ve personally been reading and appreciate your blog here, but I have not had great success in executing the limited number of matlab scripts you’ve provided —
Best Regards
Tim
I’ll take a look at your new paper.
I wouldn’t have done the post if I knew that. The paper I commented on is found on arxiv.org and has a revision history of posts on Feb 12, Apr 24, and Jun 10 of 2016. It is 15 pages long and I can’t find any indication that it is a conference paper draft, much less a preliminary one. My experience with arxiv.org is that people post submitted journal papers in order to get them out while the lengthy review process proceeds. So I figured after three drafts were uploaded, this was something you were standing by as solid. Is there a way I can tell on arxiv.org that the paper is a preliminary draft of a conference paper? I admit I am not an expert on that site.
Is that called for?
I don’t get the grammar of that parenthetical remark, but I would very much like to know what you intended.
I admit my interest is narrow at the CSP Blog. I didn’t even try to critique the ML setup or all the parameters for the algorithm you put forth. I just saw that the cyclic moment feature part was so confusing that I didn’t think any reader would be able to understand what your Machine was doing, and that my name was explicitly connected to that confusion. Was I wrong?
Nice writing style. Looking forward to reading more from you. I finally decided to write a comment on your blog. I just wanted to say good job. I really enjoy reading your post, Thanks for your great information,
Hi Dr. Spooner,
Thanks for your useful blog. I learned a lot about cyclostationary and, implemented second order and higher order cyclostationary reading your blog posts.
I am working on automatic modulation recognition (non-linear modulations e.g. CPFSK , MSK, …) for my master of science dissertation output and I was wondering if you could help me about which cyclic features can help me for a better results on non-linear v.s non-linear or non-linear v.s linear cases.
Mohammad:
Thanks for your comment and for using the CSP Blog! It sounds like you have made a lot of progress.
First, I do have a paper with Antonio Napolitano (My Papers [8]) on the cyclostationarity of CPM signals, which includes CPFSK, MSK, and GMSK as special cases. You might want to check that out for some basics on the features you can expect.
A second point is that MSK is actually exactly equal to a SQPSK signal, and so is a linear modulation from that point of view. It is also exactly a CPM signal with full response rectangular pulses, a binary alphabet, and a modulation index of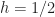 , so it falls in the class of CPM signals too.
, so it falls in the class of CPM signals too.
More generally, many CPM signals of interest are approximately linear. I think you can use Laurent’s approximation to find an approximation to a CPM signal that is the sum of several PAM signals, and usually one of those constituent PAM signals has most of the signal’s energy.
Finally, in my own work I don’t make much of a distinction between linear and nonlinear modulation types. I just try to find out what the spectral correlation function (and, maybe, the cyclic cumulants) looks like. What are the features for the signal, and what is the pattern of exhibited cycle frequencies? Sometimes this is most easily done empirically if the modulation is too crazy, like LTE.
Hope this helps…
Thanks Dr. Spooner,
I just read your paper [8] and learned about Laurent’s approximation. I think it would be very helpful extracting higher order features of linear signals e.g. some PAM modulated signals instead of extracting those directly from CPMs. My next challenge is to simulate this approximation.
Is there any source I could use to simulate this approximation and get some PAM signals from a CPM modulated signal?
I really appreciate your help
I’m not sure I understand your approach. If you approximate a CPM signal by its dominant PAM signal using the approximation in the referenced paper, and then compute the cyclic moments and cumulants of that dominant PAM signal, those moments and cumulants will not match the moments and cumulants extracted from the CPM signal itself. The approximation is a useful way to get at the basic cycle-frequency pattern exhibited by the CPM signals. It turns out that the cycle-frequency pattern depends on the modulation index. For most modulation indices, the cycle-frequency pattern is that exhibited by high-alphabet PSK, such as 16PSK, provided you don’t consider moment and cumulant orders greater than eight. For some special cases of the modulation index (multiples of 0.5), the cycle-frequency pattern is much different.
So I would try to learn the cycle-frequency patterns for the particular kinds of CPM signals of interest to you, then simulate those signals, and extract the cyclic cumulants to form classification features.
Does that make sense? Perhaps I’ve missed something or misinterpreted your remarks…
Hi Chad,
I want to calculate higher-order joint for 2 variables. I calculated the higher order single-variable and bivariate moments numerically. Now I need to combine them into cumulants (upto the 6th order cumulant, eg k_{3,3})
However, surprisingly, I was unable to find the equations for this anywhere online. Wikipedia gives the general formula and provides a few examples for joint cumulants. Also, the [summary wolfram site][2] gives a few more examples for bivariate cumulants. However, I was not able to find any comprehensive table that gives all the equations. I feel I understand the formula and the partition concept, but it is tedious to do all the calculations by hand and I dont trust myself not to make an error.
My questions are:
1) Do these equations exist anywhere online?
2) Is there an easy way to get these equations using computing software like Python or Matlab?
3) If not, what else can I do to get them?
Thanks!
[2]: http://mathworld.wolfram.com/Cumulant.html
Thanks for stopping by the CSP Blog rsandler00. Good question.
Well, I favor writing your own functions for this kind of thing, including power spectrum estimation, spectral correlation estimation, cyclic-cumulant estimation, and polyspectrum estimation, rather than relying on a function someone else wrote. Yes, higher-order CSP, higher-order cumulants, are tedious. But you don’t really have to trust yourself all that much. If you stick to using input signals for which you know the mathematical result that your estimator is striving toward, you can eventually remove all bugs. (But see below. I am feeling confused about whether you want to obtain the formula, create a corresponding estimator, or both.)
Not that I know of.
I don’t think so, but maybe for “stationary” cumulants. I don’t bother too much with that stuff since the cyclic-moment/cyclic-cumulant formulas are much more complex and so best to write them from scratch. Or do you mean you want to use symbolic math packages that output the formulas?
Are you trying to write down the formula for the bivariate sixth-order cumulant, or just estimate it for arbitrary inputs? I feel that writing down specific examples of higher-order cumulants or cyclic cumulants isn’t so important–we have the general formula already for the nth-order cyclic cumulant in terms of the nth-order cyclic moment and all the relevant lower-order cyclic moments (the Shiryaev-Leonov formula specialized to CS signals).
Hi Chad,
Thanks for the response! Its somewhat shocking to me these equations don’t exist online given how ubiquitous cumulants are in signal processing & statistics.
My goal is to extract features from finite (e.g. 2000 sample) complex IQ signals to input to upstream modulation classification algorithms (e.g. SVM). This is essentially what was done in the O’shea paper as a control for the neural networks. Since as you said O’Shea did not provide adequate details to recreate their methods (and did not provide online code despite the paper saying it will be provided upon publication), I was hoping you could point me in the right direction to implement it myself.
I was thinking to start with regular (non-cycle or 0-lag) cumulants and then work my way up to cyclic cumulants.
Thanks!
Well I don’t think the written-out-for-a-particular-n formula is all that useful. We have the general formula, and it isn’t so hard to program. For large n, the cyclic cumulants take considerable computational effort to compute, yes, but the programming needed isn’t that hard, just a lot of bookkeeping for the partitions and how the cycle frequencies vary as a function of order n and number of conjugated terms m.
I don’t recall any “cross” cumulants or moments being used in O’Shea’s papers. Can you point out where you saw cross statistics? Are we both talking about the paper that I reviewed in the present post?
What do you mean by “non-cycle or 0-lag”? I see conventional stationary-signal cumulants as a degenerate case of cyclic cumulants: Cyclic cumulants applied to a stationary signal simplify to conventional cumulants. But that is independent of the choice of the lag vector.