Understanding and Using the Statistics of Communication Signals
Cumulant (4, 2) is a Good Discriminator? Comments on “Energy-Efficient Processor for Blind Signal Classification in Cognitive Radio Networks,” by E. Rebeiz et al.
Let’s talk about another published paper on signal detection involving cyclostationarity and/or cumulants. This one is called “Energy-Efficient Processor for Blind Signal Classification in Cognitive Radio Networks,” (The Literature [R69]), and is authored by UCLA researchers E. Rebeiz and four colleagues.
My focus on this paper is its idea that broad signal-type classes, such as direct-sequence spread-spectrum (DSSS), QAM, and OFDM can be reliably distinguished by the use of a single number: the fourth-order cumulant with two conjugated terms. This kind of cumulant is referred to as the cumulant here at the CSP Blog, and in the paper, because the order is and the number of conjugated terms is .
The referenced paper claims that multi-carrier modulation (OFDM is the main type of practical multi-carrier modulation [MCM]) can be distinguished from single-carrier modulation using the cumulant. Typical single-carrier modulation types are our old friends the digital QAM/PSK/CPM signals, DSSS signals (non-frequency-hopped), ATSC DTV, AM, FM, and many others.
The authors of the paper aren’t interested in using cyclic cumulants. The cumulant they are talking about is the conventional stationary-signal cumulant. That’s why they call it rather than, say, where the third value is the harmonic number . The cumulant for a zero-mean complex-valued stationary signal and all lags equal to zero is defined by
Equation (A) here is the theoretical counterpart to the estimator in the paper, which is Equation (1).
There is a large number of very different signals in the non-MCM class, so it seemed to me upon first reading the paper that it might be hard to find one statistic that could distinguish all of these non-MCM signals from all of the MCM signals. So I devised an experiment to see for myself.
In the experiment, I first applied the authors’ to a set of captured waveforms, each of which is downconverted to complex baseband before processing, and each of which has inband SNR greater than dB. The captured signals include several OFDM signals (LTE, satellite radio) and two non-MCM signals (CDMA, WCDMA).
The authors are trying to minimize computational cost, so they want to use the minimum number of samples to estimate ; they recommend samples. (This appears to be independent of the sampling bandwidth, something I don’t understand.) So I applied the cumulant estimator to samples of the various captured signals.
I then created a set of simulated signals that included OFDM, DSSS, and a couple textbook DQAMs (QPSK and 64QAM). The results are shown here:
Figure 1. Histogram of the C(4,2) cumulant as applied to short blocks (128 samples irrespective of the sampling rate) of simulated and captured communication signals. All involved signals have high SNR.
The lower plot indicates that the cumulant is centered at value near zero for the simulated OFDM signals, and is large and negative for the DSSS and QPSK signals. The value for the 64QAM signal is somewhere in-between. If the threshold could be moved to around or so, then the MCM and non-MCM simulated signals could be distinguished with some error due to the overlap in the distributions for 64QAM and OFDM.
However, the upper plot shows the opposite for captured signals. The value for white Gaussian noise is centered near zero, as it should be, but the distributions for the various captured MCM and non-MCM signals all overlap with each other and with the distribution for WGN. There is no threshold that could be used to distinguish between MCM and non-MCM captured signals here.
I also redid the experiment with a much larger block length of 4096 samples:
Figure 2. Histogram of the C(4,2) cumulant as applied to long blocks (4096 samples irrespective of the sampling rate) of simulated and captured communication signals. All involved signals have high SNR.
We see mostly the same behavior as for the short block length of samples. The various distributions are more compact, but the conclusion is the same: simulated signals might be accurately categorized as either MCM or non-MCM through the use of a thresholded value, but the captured signals cannot be (or at least these particular captured signals cannot be). In fact, the value for one of the OFDM signals is actually smaller than the others, the opposite of the simulated case.
So this appears to be another case of Textbook Signals Ruining Everything. I’ve also applied this experimental approach to captured ATSC-DTV and broadcast FM (both non-MCM signals) for a block length of samples. For the DTV signal, the values were tightly clustered around and for the FM signal around .
Have I missed something? Please leave a comment if you think I’ve made a mistake or overlooked something crucial.
Author: Chad Spooner
I'm a signal processing researcher specializing in cyclostationary signal processing (CSP) for communication signals. I hope to use this blog to help others with their cyclo-projects and to learn more about how CSP is being used and extended worldwide.
View all posts by Chad Spooner
5 thoughts on “Cumulant (4, 2) is a Good Discriminator? Comments on “Energy-Efficient Processor for Blind Signal Classification in Cognitive Radio Networks,” by E. Rebeiz et al.”
I’ve noticed a few mistakes in this paper such as mixing up conjugates and forgetting to filter the periodogram which. This post saved me from going down a rabbit-hole. Thank you.
Is it true that equation (2) simplifies to equation (5) with “Class 1” signals when only looking for center frequency offset and symbol rate?
Is it true that equation (2) simplifies to equation (5) with “Class 1” signals when only looking for center frequency offset and symbol rate?
I don’t think (2) ‘simplifies’ to (5) in any meaningful sense. Let’s be sure we are talking about the same numbered equations. I’ve extracted a couple images from the paper. Here is equation (2):
Although Rebeiz states that (2) and (3) are the cyclic autocorrelation functions (non-conjugate and conjugate), these two equations simply define finite-time estimators of the cyclic autocorrelation functions, the latter of which are probabilistic functions (arising either from a stochastic process model or from a fraction-of-time model, but either way infinities are involved), and the former are statistics.
Then equation (5) is an estimator of a cycle frequency:
This particular cycle-frequency estimator is a search over cycle frequency for the maximum magnitude of (2) with . That is, it maximizes an estimate of the non-conjugate cyclic autocorrelation where all autocorrelation lags are ignored except that for .
So this is just a choice of an estimator. An expedient choice for many signals, to be sure, but just a choice, and the use of the “therefore” in introducing (5) is not logical. (5) doesn’t ‘follow’ from (2). A somewhat more logical choice would be to construct a cycle detector (which inherently uses all autocorrelation lags in an optimal manner) and then search for the cycle frequency that maximizes the cycle-detector output magnitude. See also My Papers [43] for the related concept of cycle-frequency refinement.
Note also several sources of confusion in the discussion near (2)–(6). Below (2)–(3), Rebeiz states that in the blind context (cycle frequencies are not known in advance), a big problem is that a cycle frequency in the data might not be equal to an expected cycle frequency arising from some known signal model. But this backwards: when doing blind cycle-frequency estimation, the fact that some cycle frequencies in the data may deviate from those in a mathematical model for the signal, or from those that exist in the signal that exits the transmit antenna, doesn’t matter. The cycle frequencies will still be estimated, and their pattern can be determined. The problem arises in the non-blind setting, where we have a cycle frequency in mind, and we go looking for it in the data. If the receiver chain, ADC, propagation environment, or even transmitter impairments cause the cycle frequency in the received data to deviate from expected, then ‘going looking for it’ might fail–it won’t be where you think it should be, should the signal indeed be present. Again, see My Papers [43].
And then in the discussion near (6), about the grid-spacing and size of the candidate cycle-frequency set in the search implied by (5), there is a more natural way to define the search grid fineness–use the native cycle-frequency resolution of the measurement (5) to find the minimum acceptable grid spacing. No need to search on a more fine grid than implied by the cycle-frequency resolution of the measurement, and your performance will suffer if the grid spacing is much larger than the native resolution of the reciprocal of the processed-data length .
“So, the suboptimal version of the multicycle detector sums the magnitudes of the individual terms, rather than summing the complex-valued terms. This obviates the need for high-quality estimates of the synchronization parameters of the signal. But the coherent average advantage implied by adding together complex numbers is lost.”

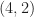


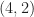
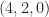

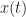

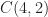
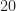

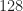

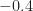

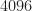
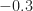
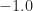
I’ve noticed a few mistakes in this paper such as mixing up conjugates and forgetting to filter the periodogram which. This post saved me from going down a rabbit-hole. Thank you.
Is it true that equation (2) simplifies to equation (5) with “Class 1” signals when only looking for center frequency offset and symbol rate?
I don’t think (2) ‘simplifies’ to (5) in any meaningful sense. Let’s be sure we are talking about the same numbered equations. I’ve extracted a couple images from the paper. Here is equation (2):
Although Rebeiz states that (2) and (3) are the cyclic autocorrelation functions (non-conjugate and conjugate), these two equations simply define finite-time estimators of the cyclic autocorrelation functions, the latter of which are probabilistic functions (arising either from a stochastic process model or from a fraction-of-time model, but either way infinities are involved), and the former are statistics.
Then equation (5) is an estimator of a cycle frequency:
This particular cycle-frequency estimator is a search over cycle frequency for the maximum magnitude of (2) with . That is, it maximizes an estimate of the non-conjugate cyclic autocorrelation where all autocorrelation lags
. That is, it maximizes an estimate of the non-conjugate cyclic autocorrelation where all autocorrelation lags  are ignored except that for
are ignored except that for  .
.
So this is just a choice of an estimator. An expedient choice for many signals, to be sure, but just a choice, and the use of the “therefore” in introducing (5) is not logical. (5) doesn’t ‘follow’ from (2). A somewhat more logical choice would be to construct a cycle detector (which inherently uses all autocorrelation lags in an optimal manner) and then search for the cycle frequency that maximizes the cycle-detector output magnitude. See also My Papers [43] for the related concept of cycle-frequency refinement.
Note also several sources of confusion in the discussion near (2)–(6). Below (2)–(3), Rebeiz states that in the blind context (cycle frequencies are not known in advance), a big problem is that a cycle frequency in the data might not be equal to an expected cycle frequency arising from some known signal model. But this backwards: when doing blind cycle-frequency estimation, the fact that some cycle frequencies in the data may deviate from those in a mathematical model for the signal, or from those that exist in the signal that exits the transmit antenna, doesn’t matter. The cycle frequencies will still be estimated, and their pattern can be determined. The problem arises in the non-blind setting, where we have a cycle frequency in mind, and we go looking for it in the data. If the receiver chain, ADC, propagation environment, or even transmitter impairments cause the cycle frequency in the received data to deviate from expected, then ‘going looking for it’ might fail–it won’t be where you think it should be, should the signal indeed be present. Again, see My Papers [43].
And then in the discussion near (6), about the grid-spacing and size of the candidate cycle-frequency set in the search implied by (5), there is a more natural way to define the search grid fineness–use the native cycle-frequency resolution of the measurement (5) to find the minimum acceptable grid spacing. No need to search on a more fine grid than implied by the cycle-frequency resolution of the measurement, and your performance will suffer if the grid spacing is much larger than the native resolution of the reciprocal of the processed-data length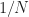 .
.
Math is hard.
This really helped clarify things:
“So, the suboptimal version of the multicycle detector sums the magnitudes of the individual terms, rather than summing the complex-valued terms. This obviates the need for high-quality estimates of the synchronization parameters of the signal. But the coherent average advantage implied by adding together complex numbers is lost.”
Thank you.
You’re welcome Dylan. For other readers, the quoted text appears in the Cycle Detectors post, not the present C42 post.