
One of the things the machine learners never tire of saying is that their neural-network approach to classification is superior to previous methods because, in part, those older methods use hand-crafted features. They put it in different ways, but somewhere in the introductory section of a machine-learning modulation-recognition paper (ML/MR), you’ll likely see the claim. You can look through the ML/MR papers I’ve cited in The Literature ([R133]-[R146]) if you are curious, but I’ll extract a couple here just to illustrate the idea.
Let’s start with O’Shea’s comment to my original ML/MR post: he laments the excessive time it would take to explain my “careful manual feature engineering” and he notes that “we are not all extreme experts in high order moment engineering.”
From Kulin et al ([R135]), “without requiring design of hand-crafted expert features like higher-order cyclic moments,” and “design of these specialized solutions have proven to be time-demanding as they typically rely on manual extraction of expert features.”
From Rajendran et al ([R136]), “without requiring expert features like higher-order cyclic moments,” and “This manual selection of expert features is tedious …”. Dogberry: but truly, for mine own part, if I were as tedious as a king, I could find it in my heart to bestow it all of your worship. Leonato: All thy tediousness on me, ah? –Shakespeare.
But all of these, and more, seem to derive from [R138] itself. We see statements like
This [good MR] is a significant challenge in the community as expert systems designed to perform well on specialized tasks often lack flexibility and can be expensive and tedious to develop analytically.
I’ve also seen similar monikers in unpublished technical reports, where the phrases “deterministic feature” and “engineered feature” are used to distinguish anything that is used for MR that is not a result of training a neural network.
As I’ve remarked before, almost nobody advocates using higher-order cyclic moments to do MR. Many advocate stationary-signal cumulants (The Literature [R90] and [R147] for example) and many advocate cyclic cumulants (My Papers [25,26,28]). And there is a decades-long sequence of papers that investigate the use of second-order cyclic moments for MR; such moments can be viewed in almost all cases as cyclic cumulants. That just shows that these researchers don’t really pay attention to prior work (too long; didn’t read).
But my task here is not to reprise my criticism of [R138]; this is a lighthearted post. The question at hand is what do these researchers mean by a hand-crafted or engineered feature. And then to make our own assessment: are cyclic moments hand-crafted? Are cyclic cumulants engineered? What about probability density functions?
What Could an ‘Engineered Feature’ or ‘Hand-Crafted Feature’ Mean?
Let’s start where one usually starts with this kind of musing: The dictionary. Dictionary.com defines ‘handcrafted’ as ‘made by handicraft.’ Not too helpful. Looking at the synonyms and antonyms is more revealing. Synonyms are ‘homespun’ and ‘homemade’ and antonyms are ‘factory-made’ and … wait for it … ‘machine-made.’
Well, this is 2020, these are old words, the CSP Blog is international, and so we have to dig deeper: what exactly does homespun mean? From Oxford Languages and Merriam-Webster, we find it means ‘simple and unsophisticated’ and, sadly, ‘homely,’ which means ugly. Ouch.
Taking this all in, the learners are saying any feature-based modulation-recognition method is not machine-made (OK!) and is simple, unsophisticated, and quite possibly ugly. I don’t have much criticism for calling CSP ugly since beauty is in the eye of the beholder. But … simple? CSP and CSP-based modulation recognition are simple and unsophisticated? To me, this is starting to look like a diss rather than any kind of substantive naming or accurate technical description.
Turning to ‘engineered feature,’ if we do a Google search of that phrase we find lots of links to the juxtaposed phrase ‘feature engineering.’ From Wikipedia:
Feature engineering is the process of using domain knowledge to extract features from raw data via data mining techniques. These features can be used to improve the performance of machine learning algorithms. Feature engineering can be considered as applied machine learning itself.
https://en.wikipedia.org/wiki/Feature_engineering
Uh-oh! So when they talk about engineered features, perhaps they are talking about feature engineering in machine learning, but features like the cyclic cumulants, spectral correlation function, PSD, cyclic polyspectra, etc., are not found or created by ‘data-mining techniques.’ They are developed or discovered using mathematical modeling and mathematical analysis–analysis that is independent of the modulation-recognition problem. But other quantities derived from a signal or signal model might have no clear connection to mathematical analysis or modeling. I might say I want to use the feature that is equal to the floor of the Bessel function applied to the real part of every twelfth sample, except on Tuesday when it is every thirteenth (The name of the game is called … Fizzbin. -James T. Kirk). Seems fine to call that hand-crafted and simple.
My conclusion about ‘engineered features’ is that this is a bucket that the learners place anything that might be of value for the problem at hand but that is found by rooting around in voluminous data rather than directly training a neural network. When they see things like moments and cumulants, they throw them into the bucket too.
PDFs and Features
I sense a gap in this taxonomy where we’ve got inscrutable machine-created neural-network connections on one hand and mysterious made-up hand-crafted features on the other. That gap is called decision theory. This is a branch of mathematics that combines probability, statistics, and estimation theory. Running all through decision theory is the mathematical object called the probability density function (PDF). You can characterize a random variable, a collection of random variables, and random processes by one or more PDFs. In the simplest case of a single random variable, you just need its PDF. For collections of random variables, and random processes, you need a set of joint PDFs.
Crucially, the cyclic autocorrelation functions, spectral correlation functions, cyclic moments, cyclic cumulants, and cyclic polyspectra are all intimately related to PDFs. If you know the set of moments for a random variable, you can construct the PDF. If you know the PDF, you can find any moment you want. If you know the moments, you know the cumulants. If you know the moments or cumulants, you know the polyspectra. If you know the moments or cumulants, you know the spectral correlation function.
We use moments and cumulants instead of PDFs because they are much easier to estimate when we restrict our attention to just a few of them, such as all the cyclic cumulants for orders 
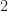
This line of thought leads me to wonder if the learners think that PDFs themselves are ‘hand-crafted’ or ‘engineered’ features. Scoff scoff. Well … um, er, … are they?
Someone, somewhere, at some time had the idea of characterizing a random quantity with mathematics. The random quantity is random because it is not completely predictable. We don’t know the value of the variable in advance of observing it. This contrasts with a deterministic function like 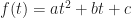

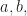

The PDF is the derivative of the cumulative distribution function (CDF), which is the probability that a random variable 

But maybe there are other sets of events that are even better than those involved in the CDF. Maybe analyzing those events would lead to even more powerful functions and analysis than can be afforded by the CDF and PDF. And if so, I suppose that might lend credibility to the putative claim that even PDFs and CDFs are just made-up things, just hand-crafted items not really distinguishable from a bunch of other hand-crafted similar items. Not fundamental, and certainly not machine-made.
Alternatives to the CDF?
The most basic event I can think of is the equality event

where 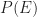
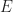
The problem with the equality event in (1) is that the probability is zero for many kinds of random variables ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
OK, then, the next simplest is whether the random variable

which is simply related to the probability that the random variable is less than or equal to

because either it is greater than or it is less-than-or-equal-to, never both.
We could conceive of building a probability theory from events on an interval, such as
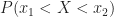
but again this kind of event can be decomposed into expressions involving only probabilities of the form 
We could conceive of building the theory using events that involve some function operating on
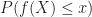
But this is surely less fundamental than (2). So it seems to me that the CDF, which is simply

is basic to the mathematical modeling of uncertain–random–variables. What is more basic?
Just a Diss
In the end, then, the CDF and PDF are fundamental to the mathematical modeling of random phenomena, which includes the communication signals that are of primary interest on the CSP Blog, and which comprise the inputs to the learners’ recognizers just the same as they comprise the inputs to statistics-based or feature-based recognizers.
The refrain of ‘save us, machines, from the horrors of hand-crafted tediously extracted painstakingly manually created features’ really seems to boil down to ‘your math and your features are sooo old-fashioned, man … try to keep up, will ya?’ Jus’ a diss, is all. Gully Foyle is my name; And Terra is my nation; Deep space is my dwelling place; The stars my destination. -Alfred Bester It would sting if I ever saw evidence that the learners actually understand decision theory or the structure of communication signal models. It may sting yet.
‘Hand-crafted’ is a synonym for ‘homespun’ which means simple and unsophisticated, and is an antonym to ‘machine-made’ which is what the learners are striving for. So I suggest that if we in the statistics community want to return the diss favor, we might refer to the machine-learning modulation-recognition work as ‘factory-farmed MR’.

Research paper get published only rely on how “novelty” impress the editor and reviewer. Deep learning is such a place everyone wants to succeed even high-level journal such as JSAC calls for paper in the topic of learning-based method for communication. Criticizing non-sense doesn’t help at all in my opinion. But leaning-based paper still get publish even their work may not be fully workable. One thing that disturbs me is that they generate “test” sample in the same way they used for “training” at the same baud rate and sample rate for instance.
BTW, I came across the example shipped with MATLAB R2020a “ModulationClassificationWithDeepLearningExample”, which is a replica of O’shea’s paper. The first impression with the pre-trained model is that it is heavily rely on the sample rate of 8SpS.
Thanks for the comment, philbar6.
I think you’re probably right that criticizing the nonsense doesn’t help those who are producing the nonsense. But maybe it will help onlookers.
I agree. This is part of what I call the “One BPSK Signal” problem. It is like the learners make their machine recognize a single instance of a signal (one fixed set of parameters such as symbol rate and carrier offset), then walk away declaring that the modulation-recognition problem is fully solved. Weird.
Dr. Spooner. I found your blog recently and it looks like a valuable online resource for rigorous DSP and mathematical modeling. Your reviews also exhibit the kind of detail you would hope to receive from the peer-review process.
The machine-learning community is exploring, perhaps somewhat awkwardly, applications for signal processing. I’ve seen some calls by other reviewers for “patience” in response to your skepticism of its application in classification (or at least claims of its relative effectiveness to traditional techniques). I think there’s a significant bridge to cross from ML practitioner’s backgrounds in computer science and programming to signals analysis.
I am a former member of the research group who won the Army Blind Signal Classification Challenge (I didn’t participate) whereby competitors attempted to train ML algos to identify unknown signal modulations from signal traces. Many of those participants were communications engineers first, ML dabblers second. They had significant experience with traditional approaches to signal classification. They were crossing that knowledge bridge from the other side.
I also know personally a number of people from some of the companies you’ve noted. A lot of these researchers are approaching the problems in good faith, though they may oversell their results. I think all of these researchers, regardless of which approach they start from, could use more guidance from the other side of the bridge.
There are probably good applications of ML to communications problems where the models are unknown and rigorous analysis is too costly, e.g. electronic warfare scenarios, low-cost hardware with wide tolerances or physical damage, unusual propagation conditions, etc. I imagine it’s useful to be able to compare these early results in ML to more rigorous theory to validate the approach before moving into more novel and less studied applications.
Anyways, I appreciate your blog.
End of comment.
Thanks for the thoughtful comment Jared, and welcome to the CSP Blog.
I don’t think there should be an accepted place for overselling results in the scientific and engineering literature. I say leave the selling to businesses and put as much truth as possible in published papers. Perhaps that just marks me as old-fashioned. I also don’t think that good faith and overselling are compatible. That being said, my bad experiences with high-profile ML researchers in 2017-2019 has given way to some good recent experiences with a couple of graduate-student and academic researchers.
Interested readers can see the comment I think you are referring to here, which is a comment on the All BPSK Signals post.
This is the opposite of my conclusion having lived through the neural-network hype of the 90s and now of today. The literature and projects I am familiar with do supervised learning–training of NNs using labeled data. It is precisely the absence of labeled data for rare events and new signal types that is a problem for trained NNs. Unless you believe the generalization problem is solved or will be solved soon? My current work with PhD students doing ML for modulation recognition indicates the generalization problem is far from being solved. Or … maybe you are talking about application of unsupervised learning to these wide-tolerance or malfunctioning RF sources? In that case, I’m just not privvy to that work I guess. I don’t see it out there in the open. One would still need a lot of data, though, to find patterns, and that’s just what’s hard to come by in the situations you mention. For my part, as long as the captured signal exhibits cyclostationarity, I can characterize it to some degree even with only one time-series.
I’m flattered that you think the CSP Blog is rigorous. The mission of the CSP Blog is to sit right in the middle between the rigorous signal-theory/decision-theory work in the dense academic literature and the day-to-day practice of the working engineer. Medium rigor I guess. Rigor, like complexity, is in the eye of the beholder …
Your blog, Dr. Spooner, is definitely one of a kind. But if this is all that is said about it, this is a sin. Your careful thinking, careful writing (these go hand in hand), the depth of your analysis, the breadth of your perspective, the rigor (about which you are quite modest) are all components of the unusual level of rigor you demonstrate. Your bravery in challenging the latest (and I fully agree oversold) fad in this era of demand for instant gratification is exemplary and highly commendable for its wisdom and utility, both of which are transparent to knowledge learners–of the human not machine variety.
It is clear that your major contribution in this blog is deeply valued by those not inflicted with machine learning as the panacea of the future of knowledge expansion and one would hope problem solving. If machine-learning aficionados of the day will make the effort to even slightly understand some of the knowledge created by committed HI (In contrast to AI) sources like yourself, there would be more hope for the intriguing concept of AI than that provided by the hacks that oversell their underperforming ML solutions to signal classification challenges.
You hardly require the encouragement but I offer it anyway, as a form of congratulation: keep up the good work; it is deeply appreciated by HI and perhaps will someday be properly built upon in the AI development of ML systems.
William A Gardner
University of California, Davis
Welcome to the CSP Blog Professor Gardner! And thank you for the comment and compliment. Very much appreciated.
I like the coinage “HI.” I will continue to help HI expand for as long as I’m able.