A PSK/QAM/SQPSK data set with randomized symbol rate, inband SNR, carrier-frequency offset, and pulse roll-off.
Update April 2025: All but the first five batch files have been removed. I needed to make space since WordPress has a hard limit on storage. Use CSPB.ML.2018R2 in any case.
Update September 2023: A randomization flaw has been found and fixed for CSPB.ML.2018, resulting in CSPB.ML.2018R2. Use that one going forward.
Update February 2023: I’ve posted a third challenge dataset here. It is CSPB.ML.2023 and features cochannel signals.
Update April 2022. I’ve also posted a second dataset here. This new dataset is similar to the original ML Challenge dataset except the random variable representing the carrier frequency offset has a slightly different distribution.
If you refer to either of the posted datasets in a published paper, please use the following designators, which I am also using in papers I’m attempting to publish:
Original ML Challenge Dataset: CSPB.ML.2018.
Shifted ML Challenge Dataset: CSPB.ML.2022.
Update September 2020. I made a mistake when I created the signal-parameter “truth” files signal_record.txt and signal_record_first_20000.txt. Like the DeepSig RML datasets that I analyzed on the CSP Blog here and here, the SNR parameter in the truth files did not match the actual SNR of the signals in the data files. I’ve updated the truth files and the links below. You can still use the original files for all other signal parameters, but the SNR parameter was in error.
Update July 2020. I originally posted 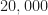 signals in the posted dataset. I’ve now added another
signals in the posted dataset. I’ve now added another 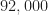 for a total of
for a total of 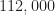 signals. The original signals are contained in Batches 1-5, the additional signals in Batches 6-28. I’ve placed these additional Batches at the end of the post to preserve the original post’s content.
signals. The original signals are contained in Batches 1-5, the additional signals in Batches 6-28. I’ve placed these additional Batches at the end of the post to preserve the original post’s content.
Continue reading “Dataset for the Machine-Learning Challenge [CSPB.ML.2018]”

 and cycle frequency
and cycle frequency  variables and of the frequency-domain functions in the spectral frequency
variables and of the frequency-domain functions in the spectral frequency  and cycle frequency
and cycle frequency 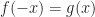 , where
, where 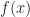 and
and 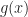 are closely related functions. We have to consider the
are closely related functions. We have to consider the  -th order
-th order 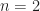 , cyclic moments and cyclic cumulants are usually identical. They differ when the signal contains one or more finite-strength additive sine-wave components. In the common case when such components are absent (as in our recurring numerical example involving
, cyclic moments and cyclic cumulants are usually identical. They differ when the signal contains one or more finite-strength additive sine-wave components. In the common case when such components are absent (as in our recurring numerical example involving ![\boldsymbol{\tau} = [\tau_1\ \ \tau_2]](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7B%5Ctau%7D+%3D+%5B%5Ctau_1%5C+%5C+%5Ctau_2%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) is set equal to
is set equal to ![[\tau/2\ \ -\tau/2]](https://s0.wp.com/latex.php?latex=%5B%5Ctau%2F2%5C+%5C+-%5Ctau%2F2%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
.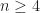 using a sampled-data record of length
using a sampled-data record of length  .
.