
In most of the posts on the CSP Blog we’ve applied the theory and tools of CSP to parameter estimation of one sort or another: cycle-frequency estimation, time-delay estimation, synchronization-parameter estimation, and of course estimation of the spectral correlation, spectral coherence, cyclic cumulant, and cyclic polyspectral functions.
In this post, we’ll switch gears a bit and look at the problem of waveform estimation. This comes up in two situations for me: single-sensor processing and array (multi-sensor) processing. At some point, I’ll write a post on array processing for waveform estimation (using, say, the SCORE algorithm The Literature [R102]), but here we restrict our attention to the case of waveform estimation using only a single sensor (a single antenna connected to a single receiver). We just have one observed sampled waveform to work with. There are also waveform estimation methods that are multi-sensor but not typically referred to as array processing, such as the blind source separation problem in acoustic scene analysis, which is often solved by principal component analysis (PCA), independent component analysis (ICA), and their variants.
The signal model consists of the noisy sum of two or more modulated waveforms that overlap in both time and frequency. If the signals do not overlap in time, then we can separate them by time gating, and if they do not overlap in frequency, we can separate them using linear time-invariant systems (filters).
Relevant FRESH filtering publications include My Papers [45, 46] and The Literature [R6].
Motivating Example
Let’s first illustrate the problem using a concrete example.
Our signal model consists of a desired signal 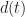



where the interference 



We’ll use the setup in Figure 1 throughout the post to unify the exposition. All frequencies and times in this post are normalized by the sampling rate, as is the custom at the CSP Blog, which is equivalent to using a sampling rate of unity. The parameters of each of the involved signals are shown in Table 1.
| Signal Name | Parameter Name | Parameter Value | Parameter Units |
|---|---|---|---|
| Signal of Interest | Modulation Type | BPSK | |
| Power | 0 | dB | |
| Bit Rate | 1/5 | Hz | |
| Carrier Offset | -0.01 | Hz | |
| Pulse Type | SRRC | ||
| Excess Bandwidth | 0.5 | ||
| Interferer 1 | Modulation Type | BPSK | |
| Power | -10 | dB | |
| Bit Rate | 1/6 | Hz | |
| Carrier Offset | 0.13 | Hz | |
| Pulse Type | SRRC | ||
| Excess Bandwidth | 0.5 | ||
| Interferer 2 | Modulation Type | BPSK | |
| Power | 4 | ||
| Bit Rate | 1/7 | ||
| Carrier Offset | -0.08 | ||
| Pulse Type | SRRC | ||
| Excess Bandwidth | 0.5 | ||
| Noise | Type | AWGN | |
| Power | -20 | dB |
The goal of a FRESH filter is to process the received noisy interference-corrupted data and return a signal that has the interference attenuated as much as possible, while maintaining the amplitude of the signal of interest. (We can always reduce the interference to zero by just multiplying the whole input data signal by zero, but that also annihilates the signal of interest.) In particular, if the interference is so bad that we cannot successfully demodulate the signal of interest, can we use a FRESH filter to bring the interference level down enough to permit demodulation?
To measure how much interference and noise is present in the input or output of a FRESH filter, or any other signal-separation system, we will use the normalized mean-squared error (NMSE) expressed in decibels (dB). For the model (1), the NMSE is given by
![\displaystyle E = \frac{1}{P_d} \left[ \frac{1}{N} \sum_{t=0}^{N-1} |x(t) - d(t)|^2 \right] \hfill (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E+%3D+%5Cfrac%7B1%7D%7BP_d%7D+%5Cleft%5B+%5Cfrac%7B1%7D%7BN%7D+%5Csum_%7Bt%3D0%7D%5E%7BN-1%7D+%7Cx%28t%29+-+d%28t%29%7C%5E2+%5Cright%5D+%5Chfill+%282%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
where 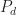
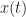

For our motivating example in Figure 1, the NMSE is about 4.2 dB. That means the ratio of the total power of the interference and noise to the signal power is about 2.6. So think of the NMSE as the reciprocal of an SNR–higher is worse, lower is better. If the NMSE is -10 dB, then the total noise and interference power corrupting the signal is ten times less than the signal power–the SNR is about +10 dB.
That’s the motivating example. How do we separate the signal from the cochannel interference and noise? That depends on what kind of processing we are willing to apply. As usual in such situations, let’s start with a linear time-invariant system–a filter.
An Optimal LTI Solution: Wiener Filtering
One way to approach the signal-separation problem is to specify the form of the processing and then attempt to find the optimal version of that form. When the form is restricted to a linear time-invariant system, or filter, the resulting optimal form is called the Wiener filter, when the criterion for optimality is to minimize the mean-squared error.
The Wiener filter has transfer function given by

where 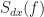
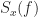
Does the filter in (4) make physical sense? Let’s try to check. Suppose 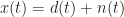
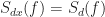


For those frequencies for which 
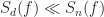

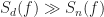

Now add back in the interference. Suppose the interference

and notice that for those frequencies 

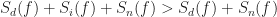
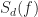


But … what about when the functions 

When the SNR is not low, 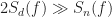

So that all frequency components–signal and interferer–are passed without any relative attenuation. That is, the NMSE of the output is the same as the NMSE at the input, neglecting the slight decrease obtained due to filtering the out-of-band noise components.
When the interferer(s) substantially spectrally overlaps the signal of interest, and the interferer and signal have similar bandwidths and power levels, the optimal linear time-invariant signal-separation system [Wiener filter] is ineffective.
Let’s get quantitative and apply the Wiener filter to our motivating example in Figure 1. We use the FSM to estimate the power spectra needed to form the filter’s transfer function in (5). To form the impulse-response function for the filter, we simply inverse transform the obtained transfer function and retain only the 128 values in the energetic central portion near 

The Wiener filter computed by my software, applied to obtain the signal corresponding to the green line in Figure 2, has transfer function shown in Figure 3.
A typical desired output SINR needed for adequate demodulation performance is something around 6 dB. So we see that the Wiener filter cannot separate the signals adequately in this particular case. So we need something else. Since the linear time-invariant system is ineffective, we can consider nonlinear time-invariant systems, nonlinear time-variant systems, or linear time-variant systems. In particular, we can consider linear time-variant systems where the time variation is periodic (surprised?): linear periodically time-variant filtering.
Linear Periodically Time-Variant Filtering
To fully understand FRESH filtering, I recommend starting with The Literature [R6] and W. A. Brown’s doctoral dissertation. I’ll sketch my understanding of linear periodically time-variant (LPTV) filtering and FRESH filtering here, following closely The Literature [R6].
As we know well, a linear time-invariant system is characterized by the impulse-response function 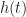
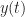

For a linear time-varying system, the impulse response is now a general function of time and delay, so that 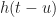


For a linear periodically (or almost periodically) time-varying system, the form of that general impulse response is constrained to be representable by a generalized Fourier series,

where the 

Putting (11) together with (10), we have the input-output relation for a general linear periodically time-varying system
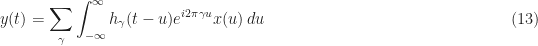
Now associate the complex exponential with the input 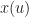
![\displaystyle y(t) = \sum_\gamma h_\gamma(t) \otimes [x(t)e^{i 2 \pi \gamma t}] \hfill (14)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+y%28t%29+%3D+%5Csum_%5Cgamma+h_%5Cgamma%28t%29+%5Cotimes+%5Bx%28t%29e%5E%7Bi+2+%5Cpi+%5Cgamma+t%7D%5D+%5Chfill+%2814%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
which is a sum of filtered frequency-shifted versions of the input: FREquency-SHift (FRESH) filtering.
A final wrinkle involves whether the input
Suppose we have real-valued signals

How is the analytic signal of 

That is, using our normal CSP-Blog Fourier transform notation,
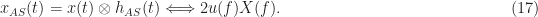
Now, what is 
![\displaystyle y_{AS}(t) = y(t) \otimes h_{AS}(t) = \left[\int_{-\infty}^\infty h(t-u)x(u)\,du \right] \otimes h_{AS}(t) \hfill (18)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+y_%7BAS%7D%28t%29+%3D+y%28t%29+%5Cotimes+h_%7BAS%7D%28t%29+%3D+%5Cleft%5B%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+h%28t-u%29x%28u%29%5C%2Cdu+%5Cright%5D+%5Cotimes+h_%7BAS%7D%28t%29+%5Chfill+%2818%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = \int_{-\infty}^\infty h_{AS}(t-v) \left[\int_{-\infty}^\infty h(v-u)x(u)\, du \right] \, dv \hfill (19)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+h_%7BAS%7D%28t-v%29+%5Cleft%5B%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+h%28v-u%29x%28u%29%5C%2C+du+%5Cright%5D+%5C%2C+dv+%5Chfill+%2819%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

![\displaystyle = \int_{-\infty}^\infty \int_{-\infty}^\infty h(w) \left[h_{AS}(t-u-w)x(u) \, du \right] \, dw \hfill (21)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+h%28w%29+%5Cleft%5Bh_%7BAS%7D%28t-u-w%29x%28u%29+%5C%2C+du+%5Cright%5D+%5C%2C+dw+%5Chfill+%2821%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = \int_{-\infty}^\infty h(w) \left[ \int_{-\infty}^\infty h_{AS}([t-w] - u) x(u)\, du \right] \, dw \hfill (22)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+h%28w%29+%5Cleft%5B+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+h_%7BAS%7D%28%5Bt-w%5D+-+u%29+x%28u%29%5C%2C+du+%5Cright%5D+%5C%2C+dw+%5Chfill+%2822%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)


We see that the analytic signal for
In the case of linear time-invariant filtering, then, filtering can be performed using the complex envelope and we’ll get what we would have gotten had we processed the real-valued bandpass signal.
What about when the processing is not linear time-invariant processing? In particular, we know we’re interested in linear time-varying processing. Let’s look at that case now.
The input-output relationship between real-valued

which is not a convolution unless 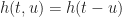
![\displaystyle y_{AS}(t) = y(t)\otimes h_{AS}(t) = \left[ \int_{-\infty}^\infty h(t,u) x(u)\, du \right] \otimes h_{AS}(t) \hfill (26)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+y_%7BAS%7D%28t%29+%3D+y%28t%29%5Cotimes+h_%7BAS%7D%28t%29+%3D+%5Cleft%5B+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+h%28t%2Cu%29+x%28u%29%5C%2C+du+%5Cright%5D+%5Cotimes+h_%7BAS%7D%28t%29+%5Chfill+%2826%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

We need to express 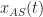

where

and 


and so we can express the transform of

Here we are neglecting a complication that occurs when 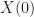
Equation (31) implies the following formulation of the real-valued signal

because

Substituting our expression involving the analytic signal into (27) gives
![\displaystyle y_{AS}(t) = \int_{-\infty}^\infty \int_{-\infty}^\infty h(t-v, u) h_{AS}(v) \frac{1}{2} \left[ x_{AS}(u) + x^*_{AS}(u)\right] \, du \, dv \hfill (34)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+y_%7BAS%7D%28t%29+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+h%28t-v%2C+u%29+h_%7BAS%7D%28v%29+%5Cfrac%7B1%7D%7B2%7D+%5Cleft%5B+x_%7BAS%7D%28u%29+%2B+x%5E%2A_%7BAS%7D%28u%29%5Cright%5D+%5C%2C+du+%5C%2C+dv+%5Chfill+%2834%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
or

which means to get the analytic signal for
![\displaystyle y(t) = \sum_{m=1}^M a_m(t) \otimes [x(t)e^{i2\pi \alpha_m t}]+\sum_{n=1}^N b_n(t) \otimes [x^*(t) e^{i 2 \pi \beta_n t}], \hfill (36)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+y%28t%29+%3D+%5Csum_%7Bm%3D1%7D%5EM+a_m%28t%29+%5Cotimes+%5Bx%28t%29e%5E%7Bi2%5Cpi+%5Calpha_m+t%7D%5D%2B%5Csum_%7Bn%3D1%7D%5EN+b_n%28t%29+%5Cotimes+%5Bx%5E%2A%28t%29+e%5E%7Bi+2+%5Cpi+%5Cbeta_n+t%7D%5D%2C+%5Chfill+%2836%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
where 

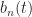



Optimal Linear Periodically Time-Variant Filtering: The Cyclic Wiener Filter
The signal-processing structure that we want to investigate is (36), the FRESH filter, which is a linear (almost) periodically time-variant system. It accepts a single complex-valued input that contains two or more temporally and spectrally overlapping cyclostationary signals, and aims to produce a single complex-valued output that is a high-SINR version of just one of the signals in the input. That is, it performs signal separation through waveform estimation.
The engineering question is: How do we choose the frequency shifts 

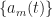
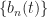
To proceed, The Literature [R6] keeps the FRESH structure generic–we don’t specify the shifts, which is equivalent to keeping the kernel


where 

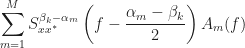
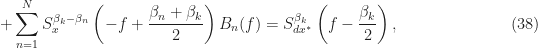
where
There are a couple things to notice about the design equations and some terminology to introduce to help us understand experimental results (outputs of a software system aimed at implementing (37)-(38)).
First, notice that on the left-hand sides, two kinds of non-conjugate spectral correlation function appear: one that involves differences between the non-conjugate frequency shifts 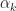

Second, notice that on the left-hand sides, two kinds of conjugate spectral correlation function appear: one that involves 

The mathematical problem is to solve (37)-(38) for the 
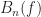


A secondary, and vexing, problem is how to choose the frequency-shift sets. The design equations, if solved, will provide the filters
There is some optimal set of frequency shifts, possibly infinite in size, that provides the smallest minimum mean-squared error. For this set of frequency shifts, and the filters corresponding to the solution of the design equations for those shifts, the corresponding FRESH filter is called the cyclic Wiener filter. For all other sets of shifts, we just have some suboptimal (non-cyclic-Wiener) FRESH filter, which of course may be quite good.
In the remainder of this post, we’ll look at various selections of the frequency shifts for our motivating problem and variants, we’ll discuss how to solve the design equations, and we’ll introduce adaptive FRESH filtering.
Constrained Optimal FRESH Filtering (FRESH Filtering in Practice)
Solving the Design Equations
The way I solve the design equations (37)-(38) is one frequency



And a similar expression exists for the long form of (38). We can write the two sets of equations as a single set of linear equations in the unknown filter transfer functions by defining the following vectors and matrix,
![\displaystyle \mathbf{B}(f) = [S_{dx}^{\alpha_1}(f - \frac{\alpha_1}{2}) \ldots S_{dx}^{\alpha_M}(f-\frac{\alpha_M}{2}) \ S_{dx^*}^{\beta_1}(f - \frac{\beta_1}{2}) \ldots S_{dx^*}^{\beta_N}(f - \frac{\beta_N}{2})]^\top \hfill (40)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbf%7BB%7D%28f%29+%3D+%5BS_%7Bdx%7D%5E%7B%5Calpha_1%7D%28f+-+%5Cfrac%7B%5Calpha_1%7D%7B2%7D%29+%5Cldots+S_%7Bdx%7D%5E%7B%5Calpha_M%7D%28f-%5Cfrac%7B%5Calpha_M%7D%7B2%7D%29+%5C+S_%7Bdx%5E%2A%7D%5E%7B%5Cbeta_1%7D%28f+-+%5Cfrac%7B%5Cbeta_1%7D%7B2%7D%29+%5Cldots+S_%7Bdx%5E%2A%7D%5E%7B%5Cbeta_N%7D%28f+-+%5Cfrac%7B%5Cbeta_N%7D%7B2%7D%29%5D%5E%5Ctop+%5Chfill+%2840%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle \mathbf{H}(f) = [A_1(f) \ldots A_M(f) \ B_1(f) \ldots B_N(f)]^\top \hfill (41)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbf%7BH%7D%28f%29+%3D+%5BA_1%28f%29+%5Cldots+A_M%28f%29+%5C+B_1%28f%29+%5Cldots+B_N%28f%29%5D%5E%5Ctop+%5Chfill+%2841%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

The vectors 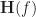


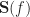
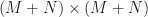

Therefore we can obtain the filters 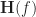

for all frequencies 

There are some nuances, though, relating to solving the design equations. The equations specify the filter transfer functions in terms of the spectral correlation functions–the limit parameters–rather than in terms of estimates of spectral correlation functions. We will be using estimates here. The main reason is that using estimates is closer to what we want to do in practice because specifying the limit parameters, while possible in our motivating example because we can numerically evaluate the theoretical spectral-correlation formulas for BPSK, requires that we know the symbol-clock and carrier phases exactly, as well as the pulse-shaping function, power levels, and of course the cycle frequencies.
Another nuance is whether to use the noise-free desired signal 
One interesting performance metric is the frequency spectrum of the error signal 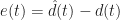


We’ll show plots of the spectrum for 

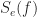 for the Wiener filter shown in Figures 2-3. Note that the power in the error signal is high for the negative frequencies
for the Wiener filter shown in Figures 2-3. Note that the power in the error signal is high for the negative frequencies ![[-0.15, 0]](https://s0.wp.com/latex.php?latex=%5B-0.15%2C+0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) , where the interference is strongest, and lowest near
, where the interference is strongest, and lowest near 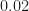 , where the combined effect of the two interferers is smallest.
, where the combined effect of the two interferers is smallest.Application to the Motivating Example
Ok, that was a long setup with a lot of math, rather abstract ideas, and little in the way of graphical aids. But the good thing about having a blog is that you can put as many plots and diagrams and pictures and tables as you want. No reviewers complaining you gotta make it shorter! So let’s do some processing.
First let’s look at the motivating example, which has a BPSK desired signal and two cochannel BPSK interferers (see Figure 1 and Table 1 to refresh your memory).
We have to select the frequency shifts 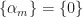

The basic guide to shift selection is to include the signals’ non-conjugate cycle frequencies in the non-conjugate shift set and the conjugate cycle frequencies in the conjugate shift set, because those choices lead to non-trivial design equations. But the shifts can also be linear combinations of the various signals’ cycle frequencies, so where to start?
I’m going to start with an intuitive choice: the three bit rates and zero for the non-conjugate shifts and the three doubled-carrier frequencies for the conjugate shifts. Considering that we could (and perhaps should?) include the negative of the bit rates, the negative doubled carriers, the doubled carriers plus-and-minus the bit rates, etc., this intuitive choice is rather sparse, and we’ll refer to it as Sparse 3A. To be perfectly clear, then, the shifts are


which are all cycle frequencies exhibited by the individual signals.
Let’s start by verifying that the input signal, which is the sum of the three BPSK signals and noise, shown in Figure 1, exhibits the cycle frequencies that we think it should. I apply the SSCA to each individual signal as it is generated and plot the results. The obtained cycle frequencies (again, blindly detected) are shown for the desired signal, interferer 1, and interferer 2 in Figures 5-10. All the cycle frequencies check out, which means that we can use them as frequency shifts in a FRESH filter with confidence.






We choose to solve the design equations using spectral correlation estimates in place of the theoretical spectral correlation functions and these estimates are formed using the frequency-smoothing method applied to 32,768 samples of the observable data and the reference signal
The input NMSE is 4.2 dB, and for the Sparse 3A set of frequency shifts, the output NMSE is -8.1 dB, for a total gain of 12.3 dB. The final result, in terms of PSDs, is shown in Figure 11, and in terms of waveforms in Figure 12.


Now let’s look at some of the internals of the process. First is the error spectrum shown in Figure 13. Compare with the error spectrum in Figure 4 for the Wiener filter.

Figures 14 and 15 show the solutions to the design equations in the frequency and time domains. That is, these are the filter transfer-function and impulse-response-function magnitudes obtained by solving the design equations using spectral correlation estimates in place of the theoretical spectral correlation functions.
 non-conjugate branch filter (blue line in top graph). It ‘wants’ to pass all the frequency components from about
non-conjugate branch filter (blue line in top graph). It ‘wants’ to pass all the frequency components from about 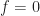 to about
to about 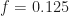 with no attenuation or amplification. Compare that ‘Wiener component’ of the FRESH filter to the Wiener filter itself in Figure 3. Presumably the Wiener component here ‘wants’ to pass these frequency components unattenuated so that they can be used by other branches.
with no attenuation or amplification. Compare that ‘Wiener component’ of the FRESH filter to the Wiener filter itself in Figure 3. Presumably the Wiener component here ‘wants’ to pass these frequency components unattenuated so that they can be used by other branches.
In the next section of this post, we’ll show that an adaptive version of this filter outperforms the FRESH filter of Figures 14-15. How can that be?
Adaptive FRESH Filtering
Clearly the filters obtained by solving the FRESH design equations can provide much better signal-separation performance than the Wiener filter, even for frequency-shift selections that are not optimal (non-cyclic-Wiener FRESH filters). In evisaged applications, however, the involved signals may change over time, leading to a discrepancy between the design-equation filters for the original situation and the current situation. One way out of this is to periodically re-solve the design equations, possibly informed by a fresh blind spectral-correlation analysis to see if the cycle frequencies of the interferers have changed.
Another way to deal with changing interference/noise statistics is to make the filter adaptive in the usual least-mean-squares (LMS) sense. Normally one would adapt the filter’s impulse-response values in accordance with an error signal, but here we want to adapt a set of filters simultaneously. That is, we want to adapt the impulse responses for each of the filters in the branches of the FRESH filter. So in the usual complex-signal LMS (The Literature [R184]), we use an extended data vector and an extended impulse-response vector instead of the input and a single impulse response.
The extended data vector is simply the concatenation of 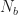
![\displaystyle \mathbf{X} = [\mathbf{x}_1 \ldots \mathbf{x}_M \ \mathbf{x^*}_1 \ldots \mathbf{x^*}_N] \hfill (48)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbf%7BX%7D+%3D+%5B%5Cmathbf%7Bx%7D_1+%5Cldots+%5Cmathbf%7Bx%7D_M+%5C+%5Cmathbf%7Bx%5E%2A%7D_1+%5Cldots+%5Cmathbf%7Bx%5E%2A%7D_N%5D+%5Chfill+%2848%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
where the vectors have elements given by

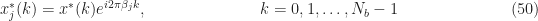
which are just the current frequency-shifted versions of the input data. Similarly, the filter to be adapted is the concatenation of the
Application to the Motivating Example
Let’s revisit the Sparse 3A FRESH filter and the motivating problem with two interferers, but this time after we solve the design equations, we’ll run the extended-vector complex-signal LMS algorithm to adapt the filters over time. The result is an output NMSE of -12.2 dB, for a gain of 4.2 – 12.2 = 16.4 dB, a full 4 dB better than the non-adaptive FRESH filter! The adapted transfer functions and impulse-response functions are shown in Figures 16 and 17, and the output at the end of adaptation is shown in the frequency domain in Figure 18 and in the time domain in Figure 19.

It isn’t clear to me why the adaptive FRESH filter almost always outperforms the FRESH filter implied by the solution to the design equations (using spectral correlation estimates). I can show, however, that the performance of the design-equation FRESH filter depends on the quality of the spectral correlation estimates used to construct the branch filters, which is intuitively reasonable. We’ll have more to say about these aspects of the FRESH-filtering quest in subsequent sections.
Application to a Modified Version of the Motivating Example
The motivating problem is a hard one in that one of the interferers is quite a bit stronger than the desired signal, and all frequency components of the desired signal are corrupted by one or the other of the interferers. To show how excellent performance is possible in other, less difficult but still hard for the Wiener filter problems, let’s set the power level of interferer 1 to zero and find the Wiener filter and look at a FRESH filter.
The spectral situation is now as shown in Figure 18–interferer 1 is gone.

The transfer-function magnitude for the computed Wiener filter is shown in Figure 19. This filter produces an output NMSE of -0.9 dB, which means that the input NMSE was reduced by a total of 4.9 dB. The input and output spectra are shown in Figure 20.

The adaptive Wiener filter for this situation only does slightly better, producing an output NMSE of -1.9 dB, for a total gain of 5.9 dB.
Turning to an adaptive FRESH filter, we use a sparse set of frequency shifts, as before, except we don’t include any of the cycle frequencies associated with interferer 1 since it is absent. The Sparse1_2 frequency shifts are:
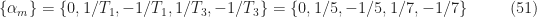
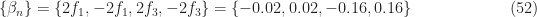
For the adaptive Sparse1_2 FRESH filter, the output NMSE is -18.4 dB, for a NMSE gain of 22.4 dB. The input and output spectra are shown in Figure 21 and a segment of the time-domain input and output is shown in Figure 22.


The adapted branch transfer functions for the Sparse1_2 adaptive FRESH filter are shown in Figure 23.
So we conclude that we can, in principle, get very large gains in SNR by applying a FRESH filter when a signal of interest is subject to cochannel interference. But we must be able to find the right branch-filter impulse responses. This isn’t as easy as solving the design equations, as we’ve already seen–the adaptive filter often does better than the design-equation filter. Why? We’ll discuss that in the next section.
Estimating Interferer Cycle Frequencies and Cycle-Frequency Patterns Blindly from Received Data
In this post, I’ve assumed that I know the cycle frequencies for each of the involved signals: the BPSK signal of interest and the two BPSK interferers. That may indeed be the case in some practical situations. In other situations, we will likely know the cycle frequencies, signal type, and cycle-frequency pattern for our desired signal, but not for the interference. In such cases, if we desired to use the interference cycle frequencies to form FRESH-filter frequency shifts (and the results here show that we do), then we need to blindly estimate the cycle frequencies from received data.
But blindly estimating cycle frequencies from noisy data, and identifying the cycle-frequency patterns exhibited by those cycle frequencies, are key steps in a common topic on the CSP Blog: blind cochannel modulation recognition. So we can do this step, in general, but it may be difficult when the involved signal-to-interference-and-noise ratios are small for some of the signals.
As an illustration, I applied the strip spectral correlation analyzer (SSCA) algorithm to the first 32,768 samples of the generated received data for the motivating example and plotted the results in the following figure:

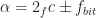 . Here the two strong signals’ conjugate cycle frequencies are found, two of the weakest signal’s conjugate cycle frequencies are found, and there is one false alarm.
. Here the two strong signals’ conjugate cycle frequencies are found, two of the weakest signal’s conjugate cycle frequencies are found, and there is one false alarm.This illustration, and many other results on the CSP Blog and in the literature, show that it is feasible to estimate the needed cycle frequencies from the data. These cycle frequencies can be used directly as FRESH-filter shifts, or parsed into subgroups with a cycle-frequency pattern recognizer so that the role, or nature, of each one can be determined. Once that is done, it is easier to select subsets of the detected cycle frequencies that are likely to produce good results. For example, if the doubled-carrier for each of the signals is identified from the items in the conjugate list, these three numbers can be used to good effect as frequency shifts in the conjugate branches of a FRESH filter.
An Issue with Solving the Design Equations: Spikes in the Transfer Functions
Let’s return to the motivating example, where two BPSK signals are cochannel with the desired BPSK signal, as in Figure 1. Here we are going to use yet another set of frequency shifts in the FRESH structure. There will be a single non-conjugate branch with shift 0, and the conjugate branches have the following shifts:
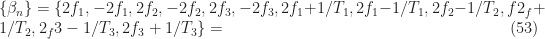
When we go to solve the design equations using 32768 samples of data, as before, we obtain the transfer functions shown in Figure 24.
. These lead to large NMSE values when the filters are employed.We observe two very large spikes in the transfer functions of Figure 24. These translate into long tails of the various impulse-response functions, and the output NMSE obtained by using these filters is -0.4 dB, for a gain of 4.2 – (-0.4) = 4.6 dB. If these filters are used to initialize the LMS adaptive FRESH filter, the output NMSE improves to -7.6 dB for a total gain of 11.8 dB.
These spikes in the solutions to the design equations are fairly common, although I was able to avoid them in the various examples I provided up to this point. I also track the condition number of the matrix 
 versus frequency for the FRESH filter using the shifts in (53) and also using 32768 samples to approximate the spectral correlation functions used in the design equations. Note the large increase in the condition number at the locations of the two spikes in the transfer functions of Figure 24.
versus frequency for the FRESH filter using the shifts in (53) and also using 32768 samples to approximate the spectral correlation functions used in the design equations. Note the large increase in the condition number at the locations of the two spikes in the transfer functions of Figure 24.So the matrix
If we increase the number of samples used to estimate the spectral correlation functions needed to solve the design equations to 131072, we eliminate the spikes and the resulting output NMSE is a much more reassuring -11.0 dB. The transfer functions are shown in Figure 26.
that are evident in Figure 24.The spikes in the transfer functions cause the error spectrum to be much more energetic, which is consistent with the large NMSEs we see whenever we use such transfer functions in the FRESH filter. The error spectrum for the short-input case of Figure 24 is shown in Figure 27 and for the long-input case of Figure 26 in Figure 28.


The problem is that we would very much like to solve the design equations using a small number of samples, as this might render FRESH filtering more practical. One possible approach is to track the derivative of the condition number and when it exceeds a threshold, instead of accepting the solution to the design equations, perform interpolation using nearby transfer-function values that correspond to smaller condition numbers.
I’ve talked with other researchers that have encountered the spikes in the design-equation-obtained transfer functions, and they have employed completely independent software to implement their system, so I’m confident that this isn’t a peculiar fluke of my own set of software tools.
Concluding Remarks and Research Questions
We see that FRESH filtering is a complicated idea and a complex set of signal-processing software tools are needed to implement it. We have skipped over describing possible practical adaptation methods–perhaps that will appear in a future CSP Blog post. There are many other signal types and signal combinations to study as well.
Here are some questions that I think would be valuable to investigate as a signal-processing researcher.
- For a given signal and interference scenario, how do we pick good frequency shifts? We’d like an algorithm that can find a minimal set of shifts that provides output NMSE to within
dB of the cyclic Wiener filter for the scenario.
- What is the best way to solve the design equations using data? Here we’ve used the FSM with a smoothing window width of 2 percent of the sampling rate. Might more sophisticated methods or more complex smoothing windows help reduce the prevalence of the spikes when forming estimates with relatively short input-data blocks?
- What are the fundamental reasons for the occurrence of the transfer-function spikes? Some choices of frequency shifts present no spikes–the condition number of
- Can the transfer-function spikes always be removed or attenuated by simply increasing the time-bandwidth product (resolution product) of the spectral correlation estimates used in the design equations? Are there situations where
- In almost all cases I’ve run, the adaptive FRESH filter produces smaller NMSE than the corresponding design-equation-solution FRESH filter. Is this always due to the imperfect solution of the design equations implied by the use of spectral correlation estimates instead of theoretical spectral correlation function values?
If you’ve found significant value in this post, please consider donating to the CSP Blog to keep it ad-free and keep the posts and datasets coming.
I have been looking forward to the post about the FRESH filter for a long time, and I will find time to read it carefully. Thank you for your sharing. I have seen the video you explained before.
Welcome to the CSP Blog Comments chaoqi! Sorry I took so long getting that post out. I think I’m now in a good position to render some “Comments On …” FRESH-filtering papers that have been accumulating in my files. Enjoy, and please let me know your thoughts on the strengths and weaknesses of the post, and most especially errors in the post.
Thank you professor for your efforts…after reading every article, I get more insights on the subject of cyclo-stationarity.
After my first reading, I don’t catch why the eq 11 and 12 take these form? Did you imposed the form of the time varying impulse response? The eq 12 I didn’t understand because a little differences with classical Fourier coefficients…
Can the concept of “non-circular” (Dr. Picinbono) or equivalently “improper” (Dr. Shereier) signal explain also the necessity to use an additional complex conjugate input to the FRESH filter?
I am progressing through several possible forms for the signal processor that is to perform signal separation: linear time-invariant, general time-variant, periodically time-variant, and almost periodically time-variant. Each time, yes, the form is imposed on the processor.
Yes. The question “What is the best signal separator if the separator is constrained to be a linear time-invariant system?” is answered by “The Wiener filter if the figure of merit is mean-squared error.” Now we ask the question “What is the best signal separator if the separator is constrained to be a linear periodically (or almost periodically) time-variant system?” And the answer is “The cyclic Wiener filter.”
The Fourier-series formula in (12) uses an infinite time average instead of the usual Fourier-series average over a single period. This is to simultaneously accommodate both periodic systems and almost periodic systems. See The Literature [R8] and [R131].
Yes. Those two researchers were a bit late to the party, though. I still recall, with some amusement, Schreier and Scharf at Asilomar 2001 explaining about random variables with non-zero second-order moments where one does not conjugate one of the factors (“improper”)! They were surprised and amazed and expected the listeners in the audience to be so too. I raised my hand and said “I’m not surprised or amazed. We’ve been using so-called “improper” variables for years and publishing about it too. They arise naturally in mathematical models of communication signals.” But those researchers you cite are from the statistics school of electrical engineering. They don’t pay attention to the signal-processing school. Their training has, unfortunately, led them to focus on Gaussian random variables and strict proofs of estimator consistency. They end up being late to the application side of things, especially in communication signal processing.
Thank you professor for your answers.
I agree with you about statistic school but I think sometimes it brings more insights about the subject.
Do you have any recommended works about processing non-gaussian signals and interferences ? Volterra structure, in addition to its complexity in most cases it modifies noise distribution and make hard subsequent processing like detection or estimation.
It’s a great pleasure to have such an opportunity to exchange with you, professor.
Best regards.
Almost every signal that I process using CSP is non-Gaussian. The noise associated with receiving a non-Gaussian communication signal using a physical radio receiver is Gaussian. But all the signals in the Gallery are non-Gaussian, except analog AM because I typically generate the message signal there as a bandlimited Gaussian signal.
Academic papers and books sometimes focus on Gaussian cyclostationary signals, but such signals don’t come up for me in real-world work.
Does that answer your question?
I meant is there any nonlinear structure other than volterra one to deal with non-gaussian signals ? From statistical perspective, optimal solution isn’t linear one but nonlinear in non Gaussian scenario.
Optimal nonlinear structure modifies background noise (e.g. PDF) which create other challenges to subsequent processing…What is your opinion on this issue ?
Recently, I heard about Signal Processing in generalized metric space with new nonlinear operation. Do you have any feedback on this question ?
Thank you Chad for this post! It was an invaluable companion piece to “Cyclic Wiener filtering: theory and method” to better my understanding of FRESH/Cyclic Wiener filtering concepts, especially the walkthrough of your motivating example. Might I suggest a subtitle (punny, although funny may be a stretch)? “Getting mixed signals? Keep it FRESH!”
Hi, many thanks for your blog. I have just recently became aware of it, and I already find it useful.
I have some questions following your post:
1. When using the Weiner filter you write – “We use the FSM to estimate the power spectra needed to form the filter’s transfer function in (5). ”
When using the FRESH filter you write – “We choose to solve the design equations using spectral correlation estimates in place of the theoretical spectral correlation functions and these estimates are formed using the frequency-smoothing method applied to 32,768 samples of the observable data and the reference signal d(t). ”
So is there some assumption being made about knowing the desired/reference signal apriori?
What happens if we don’t know the reference signal apriori, but rather only have some coarse knowledge of what its CF might be?
2. You assume different carrier offsets and bit rates for the signals, which in turn implies different CFs for them. What would happen if some of the parameters would have been the same? Say, same bit rate but different carrier offsets, would it still be possible to filter out the interferences?
Welcome to the CSP Blog George! Thanks much for the thoughtful comment.
When solving the design equations (39), you need the spectral correlation functions for the data as well as the cross spectral correlation functions between the desired signal and the data (right-hand side). The latter includes the power spectrum for the desired signal. If you know that in advance, you can just use it. If you have a good model for the desired signal, you can do as I say. For all the other spectral correlation functions, you can, in principle, estimate them from the received data, or you can use analytical formulas, depending on the problem set up. The thing that is hard to estimate directly from the data is the power spectrum of the desired signal, because signal-selectivity doesn’t apply.
I address the issue of estimating the required cycle frequencies, blindly, from the data itself in the post section called “Estimating Interferer Cycle Frequencies and Cycle-Frequency Patterns Blindly from Received Data.”
If the symbol rates were identical, but the carrier offsets were different, and the signal type is BPSK or MSK (some signal with conjugate cyclostationarity), I think performance would be similar to the examples I’ve shown. If all of the cycle frequencies are shared by the two signals, then they completely spectrally overlap, and the problem is more difficult. In principle, FRESH filtering could still provide some separation, provided that the symbol-clock and carrier phases weren’t also identical. To see how the FRESH approach might work, you could evaluate the error spectrum (45) for this kind of problem.
This is probably a silly question, but what PSD method did you use to generate the PSD plots? I think the one I found lacks some kind of smoothing since they look like yours but more noisy and scale by 2 in dB. The function I used is below.
function stream = PSD(stream, fs)
N = length(stream);
stream = fftshift(fft(stream, [], 1), 1);
stream = abs(stream).^2 / (N * fs);
stream = pow2db(stream);
end
Never mind, I solved it. I just did not look hard enough at first.
Welcome to the CSP Blog John!
Glad you answered your own question.
The function in your previous comment computes the periodogram, which is not a good estimate of the power spectrum. Just saying it for future readers of your comment.
Hope the FRESH filtering is going well.
Thanks!
I do have another question. I understand the idea behind the math involving the matrices and convolution, but I am not familiar with the notation used for the spectral densities completely. Starting at the design equation section there appears a superscript with either alpha, beta, or a difference of them. I tried re-reading the post but I still do not get it. Could you explain what this notation means?
Those are not spectral densities in (37)-(38). They are spectral correlation functions.
More accurately, if the superscript is zero, the function is a spectral density (PSD), otherwise it is a spectral correlation density, or just spectral correlation function.
What I am doing in this post is trying to explain and illustrate cyclic Wiener filtering (The Literature [R6]), which is a method of separating signals that are contemporaneous and cochannel (like Figure 1). Cyclic Wiener filtering differs from conventional Wiener filtering in that the latter employs only power spectra or time-invariant autocorrelation functions, whereas the former uses spectral correlation functions or time-variant autocorrelation functions. That is, the Wiener filter exploits only stationarity and the cyclic Wiener filter exploits both stationarity and cyclostationarity. Cyclic Wiener filters are also called frequency-shift (FRESH) filters, which is part of the post title here.
To understand, implement, and debug an implementation of a FRESH filter, you’ll need to study and understand other, more basic, parts of the CSP Blog.
I suggest you take a look at this post, which is for beginners at CSP, and follow the links within it:
For the Beginner at CSP