
Park the car at the side of the road
“That Joke Isn’t Funny Anymore” by The Smiths
You should know
Time’s tide will smother you…
And I will too
I applaud the intent behind the paper in this post’s title, which is The Literature [R183], apparently accepted in 2022 for publication in IEEE Access, a peer-reviewed journal. That intent is to list all the found ways in which researchers preprocess radio-frequency data (complex sampled data) prior to applying some sort of modulation classification (recognition) algorithm or system.
The problem is that this attempt at gathering up all of the ‘representations’ gets a lot of the math wrong, and so has a high potential to confuse rather than illuminate.
There’s only one thing to do: correct the record.
First let’s just dwell on the word representation. It is commonly used in mathematics and signal processing to mean an alternative description of some mathematical object, typically a function or time-series. That is, it is a way of expressing the mathematical object that has all the information of the original object and no additional information. In this way of using representation, the new object description is invertible–you can get back to the original object expression from the representation.
We looked at several representations in the Signal Processing ToolKit post on signal representations. There we saw how to represent–write down–signals (functions) in terms of weighted sums of simple functions drawn from familiar function sets, such as harmonically related sine waves (Fourier series), piecewise constant binary-valued functions (Walsh series), and impulses.
In The Literature [R183], though, representation is used to mean any kind of mathematical operation applied to sampled data. We’ve seen representation used in various machine-learning papers, such as The Literature [R135], where the performance of a convolutional neural network for modulation recognition is assessed for three versions of the input data: rectangular 

![S(f) = {\cal F}[s(t)]](https://s0.wp.com/latex.php?latex=S%28f%29+%3D+%7B%5Ccal+F%7D%5Bs%28t%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The paper attempts to catalog all the features researchers use to develop modulation recognition algorithms. These features could be used as inputs to a neural network, or used in more traditional ways to develop modulation-recognition signal-processing algorithms. The authors then use many of their defined features (representations) in a simple linear classifier that is applied to the DeepSig 2018 dataset. Which means, yes, they try to apply cyclic cumulants and the spectral correlation function to very short data records with uncertain cycle frequencies.
Representations (Features) Considered in [R183]
Helpfully, the authors provide a table of the representations they aim to cover in their Figure 1 and Table 1, which are reproduced here, together, in my Figure 1.

The signal class for which the features are to be extracted is really the class of digital signals in the RML 2018 dataset, but the authors also decide to try to define the signal class mathematically. So we see Equation (1) is the bare-bones linear pulse-amplitude-modulated signal,

and a better, more realistic, version that includes a carrier frequency offset, symbol-clock offset, noise, and carrier phase in Equation (2). However, this model rules out several of the signals that are considered at various points in the text, including staggered modulations like MSK and GMSK, and frequency modulations like FSK. But, OK, not a terrible start.
In summary, the authors consider many features, and their focus is on simple digital signals, not stuff like OFDM, DSSS, or FH.
Needed Corrections to the Authors’ Mathematics
Now let’s look at some of the equations that the authors use to define all the representations that they think are important for modulation classification. For each one I present, I correct the record.
Section II.B: Preprocessing and Cyclostationary Features
Let’s start with Equation (3),

Here the delay product ![L^{(*)}[n, \boldsymbol{\tau}]](https://s0.wp.com/latex.php?latex=L%5E%7B%28%2A%29%7D%5Bn%2C+%5Cboldsymbol%7B%5Ctau%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

The first thing to notice is that the average in (3) is biased: the sum is over 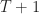

![\displaystyle \lim_{T\rightarrow\infty} \frac{1}{T+1} \sum_{n=-T/2}^{T/2} L^{(*)} [n, \underline{\tau}] e^{-i 2 \pi \alpha n} \hfill [1]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7BT%5Crightarrow%5Cinfty%7D+%5Cfrac%7B1%7D%7BT%2B1%7D+%5Csum_%7Bn%3D-T%2F2%7D%5E%7BT%2F2%7D+L%5E%7B%28%2A%29%7D+%5Bn%2C+%5Cunderline%7B%5Ctau%7D%5D+e%5E%7B-i+2+%5Cpi+%5Calpha+n%7D+%5Chfill+%5B1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
In the table, the correntropy kernel is listed as 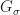
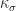
![x[n]x^*[n +\tau]](https://s0.wp.com/latex.php?latex=x%5Bn%5Dx%5E%2A%5Bn+%2B%5Ctau%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![L[\cdot, \cdot]](https://s0.wp.com/latex.php?latex=L%5B%5Ccdot%2C+%5Ccdot%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle L_x(t, \boldsymbol{\tau};n,m) = \sum_{j=1}^n x^{(*)_j} (t + \tau_j), \hfill [2]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+L_x%28t%2C+%5Cboldsymbol%7B%5Ctau%7D%3Bn%2Cm%29+%3D+%5Csum_%7Bj%3D1%7D%5En+x%5E%7B%28%2A%29_j%7D+%28t+%2B+%5Ctau_j%29%2C+%5Chfill+%5B2%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
where there are 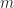


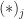
Turning to the last row in the column, the higher-order cumulants, we have to assume that the underbar notation 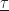
![\boldsymbol{\tau} = [\tau_1\ \tau_2\ \ldots, \tau_j]](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7B%5Ctau%7D+%3D+%5B%5Ctau_1%5C+%5Ctau_2%5C+%5Cldots%2C+%5Ctau_j%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
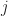
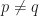
And then that last row is different in character from the others. However you define a cumulant (of a random variable, of a set of random variables, of a random process), it is a limit parameter, not a simple function of the data like the other three rows. In fact, if it is a cumulant of a random variable or a stationary process, it will be independent of 

Also, just below (3) 
Finally, notice that in (3) the optional conjugation is applied to the entire delay product, whereas in the examples in Table 2, different factors possess a conjugation or not. The latter is appropriate, the former is superfluous: you don’t get any extra or different information from using the single optional conjugation applied to the delay product. You just negate the cycle frequencies 
Section III.A: Fourier Transform
The discrete Fourier transform is introduced, correctly, in Equation (4), which is followed by an attempt at defining the short-time Fourier transform (STFT) in Equation (5),
But notice the sloppiness creeping in here–the window ![h[n]](https://s0.wp.com/latex.php?latex=h%5Bn%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

![x[n]](https://s0.wp.com/latex.php?latex=x%5Bn%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

![\displaystyle \mbox{\rm STFT}(x)(\tau, k) = \sum_{n=0}^{N_s - 1} x[n-\tau]h[n-\tau]e^{-i 2 \pi nk/N_s} \hfill [3]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmbox%7B%5Crm+STFT%7D%28x%29%28%5Ctau%2C+k%29+%3D+%5Csum_%7Bn%3D0%7D%5E%7BN_s+-+1%7D+x%5Bn-%5Ctau%5Dh%5Bn-%5Ctau%5De%5E%7B-i+2+%5Cpi+nk%2FN_s%7D+%5Chfill+%5B3%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
We then see the sentence “Since the modulation techniques MPSK, MQAM, and MFSK have different numbers of frequency peaks, the peak count of the magnitude of the DFT can be used as a feature.” Well, I don’t think the number of frequency peaks is different between MPSK and MQAM–they have a single peak because they are unimodal (assuming typical filtering like square-root raised-cosine). I suppose Manchester-encoded PSK signals are a special case because they have bimodal spectra. Some forms of MFSK do have multiple peaks–their spectra are truly multi-modal. But MFSK is not included in the authors’ signal model (1).
Section III.B: Wavelet Transform
I have some direct experience with wavelets (My Papers [27,36]). They are useful in some situations, but are not particularly well-suited for ‘Using and understanding the statistics of communication signals,’ our raison d’etre here at the CSP Blog. In defining the continuous wavelet transform in Equation 9,

The ‘defined as’ symbol is used strangely–the two quantities are not necessarily equal (how is 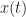

The scaled and shifted wavelet generating function ![\psi_{j,k}[n]](https://s0.wp.com/latex.php?latex=%5Cpsi_%7Bj%2Ck%7D%5Bn%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The wavelets are ostensibly computed for ASK, FSK, PSK, and QAM, and the result is the following:

which is strange because none of the wavelets here are functions of the delay 

So far the mathematical errors and issues are relatively minor. Things get rougher from here on out.
Section IV.A: Estimation of Moments and Cumulants
Just before Section IV.A begins, we have the shout-out:

Their reference [74] (My Papers [28]) considers, like Marchand, features that combine cyclic cumulants of various orders. It builds on the more important and fundamental algorithmic work in My Papers [25,26].
In Section IV.A, we have a brief discussion of how moments arise from the characteristic function, then the paper focuses on moments of a cyclostationary process with equation (20),

Since the process 

Equation (20) is followed by a rather garbled description of the moment-cumulant relationship and the mathematical idea of a partition of a finite set. Then we arrive at a long list of cumulants that are expressed in terms of moments in Equation (23):

But these formulas do not apply when the random variable 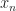
The sentence under (23) is false. The cumulants in Table 4 are cumulants of the symbol random variable associated with digital modulations, not the cumulants of the signal samples themselves, except in the very special and impractical case where the digital signal uses rectangular pulses. And let’s talk about Table 4:

This is a slightly modified version of Table 4 relative to [R183] in that I added small red ovals to indicate each stated cumulant that is in error. For 8PSK, the correct values for those in the red ovals are, from left to right, 


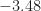
Remember that the cumulants in Table 4 are for the symbol random variable in the general model for all signals in the table given by
![\displaystyle s(t) = \sum_{k=-\infty}^\infty a_k p(t-kT_0-t_0) e^{i 2 \pi f_0 t + i \phi_0} \hfill [4]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+s%28t%29+%3D+%5Csum_%7Bk%3D-%5Cinfty%7D%5E%5Cinfty+a_k+p%28t-kT_0-t_0%29+e%5E%7Bi+2+%5Cpi+f_0+t+%2B+i+%5Cphi_0%7D+%5Chfill+%5B4%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
where 
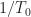
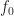
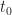
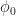

Let’s take 8PSK as an example. For this signal, the symbol random variable is a discrete random variable that can take on one of eight values 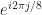
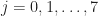
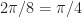
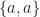
![\displaystyle E[a^2] = E[e^{i 4\pi j /8}] = E[e^{i (j\pi/2)}] \hfill [5]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5Ba%5E2%5D+%3D+E%5Be%5E%7Bi+4%5Cpi+j+%2F8%7D%5D+%3D+E%5Be%5E%7Bi+%28j%5Cpi%2F2%29%7D%5D+%5Chfill+%5B5%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
where 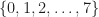

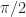
The same simple analysis holds for 8PSK and the set 
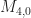
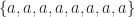
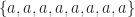


Think of it this way. For 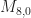
![\displaystyle E[a^8] = E[(e^{i 2 \pi j /8})^8] = E[e^{i 2 \pi j}] = E[1] = 1 \hfill [6]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5Ba%5E8%5D+%3D+E%5B%28e%5E%7Bi+2+%5Cpi+j+%2F8%7D%29%5E8%5D+%3D+E%5Be%5E%7Bi+2+%5Cpi+j%7D%5D+%3D+E%5B1%5D+%3D+1+%5Chfill+%5B6%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
because 
![\displaystyle E[(e^{i 2 \pi j/16})^8] = E[e^{i \pi j}] = 0 \hfill [7]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%28e%5E%7Bi+2+%5Cpi+j%2F16%7D%29%5E8%5D+%3D+E%5Be%5E%7Bi+%5Cpi+j%7D%5D+%3D+0+%5Chfill+%5B7%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
because for 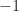
My identification of both the correct and erroneous entries in Table 4 is confirmed by a random-variable cumulant computer I constructed long ago that operates on an arbitrary input probability mass function. Those values are, in turn, validated by connection to theoretical cumulant formulas. Those formulas are also validated by application of simulated PSK/QAM signals to a cyclic-cumulant estimator algorithm. It all hangs together.
So the simplest case of a cumulant of a discrete random variable is not handled correctly by these authors, which will cause confusion in any reader that tries to replicate the results. More importantly, though, it augurs poorly for the upcoming section on cyclic cumulants, which are complicated functions of time 
![\boldsymbol{\tau} = [\tau_1\ \tau_2 \ \cdots \tau_n]](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7B%5Ctau%7D+%3D+%5B%5Ctau_1%5C+%5Ctau_2+%5C+%5Ccdots+%5Ctau_n%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Section IV.B: HOS as Preprocessing Features
So we’re still in Section IV, which is called Signal Statistics, and not yet in Section V, which is called Cyclostationary Analysis. But the authors here, in Section IV, are still throwing around expectations applied to signals, so like it or not, cyclostationarity must be attended to.
We arrive at Equation (24),

There are three lines to (24). The first line specifies a limit parameter (stochastic expectation or fraction-of-time expectation, for that is what a cumulant relates to). Note that in the final 

That’s not the bad part of (24) though.
The second line is an estimate of the 
The third line is just confused and confusing. What are the limits on the sum over 
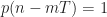
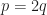
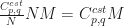

- The cumulant is a limit parameter and is a function of time
- The cumulant is not equal to the moment except in some special cases.
- The cumulant is a limit parameter and is not equal to a finite-time estimate of a moment.
- The cumulant is a limit parameter dependent on time
Section V.A: Second-Order Cyclostationary: CAF and SCD
We start off with incorrect definitions of the autocorrelation and cyclic autocorrelation functions in Equations (26) and (27),

Since neither factor involving
In (26), there has to be a limiting operation, or else the quantity on the left is an estimate, not a limit parameter. And (26) is missing a factor relating to the number of samples considered in the average, probably because the authors have infinite limits on the sum. So (26) is a mess. In (27), the factor out in front of the summation must be 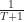
Below (27) we find this tangle of verbiage:

- The delay product
is not the autocorrelation function.
- A first-order cyclostationary function is a function that contains one or more finite-strength additive sine-wave components. Generally we avoid processing such signals with cyclic autocorrelation or spectral correlation estimators because the first-order sine waves interact to produce second-order sine waves, but there is no additional information in these particular second-order sine waves. Plus, the signals we’ve been focusing on in the paper don’t even typically have finite-strength additive sine-wave components (except OOK and maybe the MFSK signals, depending on their nature). So that last sentence is gibberish.
The exposition on second-order cyclostationarity ends with Figure 4, which purports to show salient aspects of the spectral correlation function for OOK, BPSK, QPSK, and M-QAM:

Because we can clearly see a symmetry that is always evident in the PSD of a real-valued PSK/QAM signal, it must be the case that the cycle frequency 




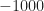

Section V.C: High Order Cyclostationary: Cyclic Moments and Cumulants
The delay product (3) we looked at early in the post is revisited and revised in Equation (30),

Here the optional conjugations are applied to each factor, as they should be, and in contradiction to (3). Good start to the section! But then it is rapidly downhill.
Equation (31) is

and the factor of 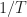

This definition of the CTMF is NOT the discrete Fourier transform of the delay product. That’s exactly the point of including the
Section V.D: RD-CTCF
The authors then move on to the cyclic cumulant itself. We see this claim:

That is not the definition of the reduced-dimension cyclic temporal cumulant function, and I should know because I coined that term. In general, the 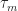
Then we come to the mathematical definition of the cyclic cumulant proffered by the authors in (32)-(33):

Please be aware that these are NOT the correct formulas for cyclic cumulants, reduced-dimension or otherwise. This is what happens when you take the relatively simple formulas that relate the moments of a single random variable to the cumulants for that single random variable and apply them directly to a random process (![s[n]](https://s0.wp.com/latex.php?latex=s%5Bn%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Moreover, these are actually finite-time estimates of … something, because there are finite sums of length 
It is probably worth reproducing the correct formula for a cyclic cumulant in terms of products of lower-order cyclic moments here so we can really appreciate the wrongness of (32)-(33). From the post on cyclic cumulants (Equation (32) there),
![\displaystyle C_x^\alpha (\boldsymbol{\tau}; n,m) = \sum_{P=\{\nu_j\}_{j=1}^p} \left[ (-1)^{p-1}(p-1)! \sum_{\boldsymbol{\beta}^\dagger \boldsymbol{1}=\alpha} \prod_{j=1}^p R_x^{\beta_j} (\boldsymbol{\tau}_j; n_j, m_j) \right]. \hfill [8]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+C_x%5E%5Calpha+%28%5Cboldsymbol%7B%5Ctau%7D%3B+n%2Cm%29+%3D+%5Csum_%7BP%3D%5C%7B%5Cnu_j%5C%7D_%7Bj%3D1%7D%5Ep%7D+%5Cleft%5B+%28-1%29%5E%7Bp-1%7D%28p-1%29%21+%5Csum_%7B%5Cboldsymbol%7B%5Cbeta%7D%5E%5Cdagger+%5Cboldsymbol%7B1%7D%3D%5Calpha%7D+%5Cprod_%7Bj%3D1%7D%5Ep+R_x%5E%7B%5Cbeta_j%7D+%28%5Cboldsymbol%7B%5Ctau%7D_j%3B+n_j%2C+m_j%29+%5Cright%5D.+%5Chfill+%5B8%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The sum is over all the distinct partitions of the index set 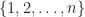

The important thing to notice about [8] is that the cyclic cumulant for cycle frequency
Take for example SRRC BPSK, which has conjugate cycle frequencies (cycle frequencies for 
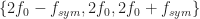
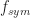


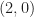

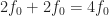



These incorrect formulas are then used, to produce the cyclic-cumulant magnitude plots in Figure 5, although there is no mention of

The lack of symmetry in some of the 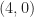
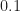

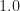

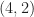

and here for 


How do I know that the values in my plots are correct and the values in the plots of Figure 5 are in error? Because I checked my work. I have an independent piece of software that numerically evaluates the theoretical formula for the cyclic cumulant of a PSK or QAM signal, and I can check those numerical values against the values I obtain in the plots. And they check out. Moreover, I can cross-check those results with known theoretical (math) formulas for these textbook signals. And that checks out.
Section V.F: Kernel-Based Cyclostationary
There isn’t much to say about the authors’ take on kernel-based cyclostationarity, which is more commonly called cyclic correntropy, other than they are quite credulous concerning the material, which I believe is dubious. You can see my evidence here, here, and here.
The DeepSig RML 2018 Dataset
The authors are clearly enamored with the DeepSig RML datasets, focusing on the 2018 dataset I analyzed in a previous post (see also here, here, and here for analyses of other DeepSig datasets on the CSP Blog).
We have:

Have they, really, though? I think every paper I’ve analyzed that used one or more of the DeepSig datasets has failed to either mention or to adequately address the generalization (dataset shift) problem. The papers merely show that you can do an automated optimization process (also known as training a neural network) and that that optimization process does well on the highly constrained training dataset. That’s it. Moreover, we’ve recently developed strong evidence that these automated optimization processes are quite delicate (brittle) and suffer greatly when the input is IQ data and the probability density functions of the involved random variables change even slightly.
Then there’s this:

I don’t have an issue with ‘objective.’ I can’t detect any biases here, but the work is clearly not ‘careful.’
Finally, this:

But the variation in parameters of the 2018 dataset is minimal. This is just more highly constrained dataset processing, showing that optimizers can optimize.
Final Remarks
This is where I usually cry out in anguish about the state of peer review. But not so much this time.
Why do the authors feel this paper is even ready for review, much less ready for publication? Why do the reviewers accept it? Because they don’t cross-check their work. And that is the most valuable mental habit for research engineers: how can I verify this result? How can I see if this result is consistent with other results I already trust?
The dilemma is that checking, cross-checking, re-checking, verifying, and validating are time-consuming and can be tedious. The time consumption aspect is a primary driver in the modern jettisoning of the checking mentality. ‘Just get that paper complete and submitted’–we need to publish right now and over and over again quickly.
The incentive structure of academia seems to tend toward paper weight rather than paper quality. It pays more to have more pages to count than it does to have far fewer pages but those pages contain valid, novel, high-quality results and information.
But I say to the younger readers here: Check your work. It will pay off for you and for everyone that accesses your work in the long run. Don’t quickly believe anything you read in a technical paper. Find ways to cross-check the claims and results. Adopt a skeptical stance.
And now the logical conclusion of my exhortation: check my work here in this post and on the entire CSP Blog.