
Update April 2025: All but the first five batch files have been removed. I needed to make space since WordPress has a hard limit on storage. Use CSPB.ML.2018R2 in any case.
Update September 2023: A randomization flaw has been found and fixed for CSPB.ML.2018, resulting in CSPB.ML.2018R2. Use that one going forward.
Update February 2023: I’ve posted a third challenge dataset here. It is CSPB.ML.2023 and features cochannel signals.
Update April 2022. I’ve also posted a second dataset here. This new dataset is similar to the original ML Challenge dataset except the random variable representing the carrier frequency offset has a slightly different distribution.
If you refer to either of the posted datasets in a published paper, please use the following designators, which I am also using in papers I’m attempting to publish:
Original ML Challenge Dataset: CSPB.ML.2018.
Shifted ML Challenge Dataset: CSPB.ML.2022.
Update September 2020. I made a mistake when I created the signal-parameter “truth” files signal_record.txt and signal_record_first_20000.txt. Like the DeepSig RML datasets that I analyzed on the CSP Blog here and here, the SNR parameter in the truth files did not match the actual SNR of the signals in the data files. I’ve updated the truth files and the links below. You can still use the original files for all other signal parameters, but the SNR parameter was in error.
Update July 2020. I originally posted 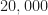
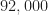
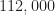
Overview of Dataset
The 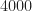
The zip files are each about 1 GB in size.
The modulation-type labels for the signals, such as “BPSK” or “MSK,” are contained in the text file:
Each signal file is stored in a binary format involving interleaved real and imaginary parts, which I call ‘.tim’ files. You can read a .tim file into MATLAB using read_binary.m. Or use the code inside read_binary.m to write your own data-reader; the format is quite simple.
The Label and Parameter File
Let’s look at the format of the truth/label file. The first line of signal_record_first_20000.txt is
1 bpsk 11 -7.4433467080e-04 9.8977795076e-01 10 9 7.8834556169e+00 0.0
which comprises 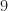
- Signal index. In the case above this is `1′ and that means the file containing the signal is called signal_1.tim. In general, the
th signal is contained in the file signal_n.tim. The Batch 1 zip file contains signal_1.tim through signal_4000.tim.
- Signal type. A string indicating the modulation format of the signal in the file. For this dataset, I’ve only got eight modulation types: BPSK, QPSK, 8PSK,
-DQPSK, 16QAM, 64QAM, 256QAM, and MSK. These are denoted by the strings bpsk, qpsk, 8psk, dqpsk, 16qam, 64qam, 256qam, and msk, respectively.
- Base symbol period. In the example above (line one of the truth file), the base symbol period is
.
- Carrier offset. In this case, it is
.
- Excess bandwidth. The excess bandwidth parameter, or square-root raised-cosine roll-off parameter, applies to all of the signal types except MSK. Here it is
. It can be any real number between
and
.
- Upsample factor. The sixth field is an upsampling parameter U.
- Downsample factor. The seventh field is a downsampling parameter D. The actual symbol rate of the signal in the file is computed from the base symbol period, upsample factor, and downsample factor:
. So the BPSK signal in signal_1.tim has rate
. If the downsample factor is zero in the truth-parameters file, no resampling was done to the signal.
- Inband SNR (dB). The ratio of the signal power to the noise power within the signal’s bandwidth, taking into account the signal type and the excess bandwidth parameter.
- Noise spectral density (dB). It is always
dB. So the various SNRs are generated by varying the signal power.
To ensure that you have correctly downloaded and interpreted my data files, I’m going to provide some PSD plots and a couple of the actual sample values for a couple of the files.
signal_1.tim
The line from the truth file is:
1 bpsk 11 -7.4433467080e-04 9.8977795076e-01 10 9 7.8834556169e+00 0.0
The first ten samples of the file are:
-5.703014e-02 -6.163056e-01
-1.285231e-01 -6.318392e-01
6.664069e-01 -7.007506e-02
7.731103e-01 -1.164615e+00
3.502680e-01 -1.097872e+00
7.825349e-01 -3.721564e-01
1.094809e+00 -3.123962e-01
4.146149e-01 -5.890701e-01
1.444665e+00 7.358724e-01
-2.217039e-01 -1.305001e+00
An FSM-based PSD estimate for signal_1.tim is:

And the blindly estimated cycle frequencies (using the SSCA) are:

The previous plot corresponds to the numerical values:
Non-conjugate 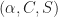
8.181762695e-02 7.480e-01 5.406e+00
Conjugate
8.032470942e-02 7.800e-01 4.978e+00
-1.493096002e-03 8.576e-01 1.098e+01
-8.331298083e-02 7.090e-01 5.039e+00
signal_4000.tim
The line from the truth file is
4000 256qam 9 8.3914849139e-04 7.2367959637e-01 9 8 7.6893849108e+00 0.0
which means the symbol rate is given by 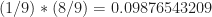



Final Thoughts
Is 
That’s about it. I think that gives you enough information to ensure that you’ve interpreted the data and the labels correctly. What remains is experimentation, machine-learning or otherwise I suppose. Please get back to me and the readers of the CSP Blog with any interesting results using the Comments section of this post or the Challenge post.
For my analysis of a commonly used machine-learning modulation-recognition dataset (RML), see the All BPSK Signals post. I also analyze two other datasets from the RML authors (DeepSig Inc.) here and here.
i need the UFMC modulation signal in time domain. thanks in advance
Well, the data set I’ve posted is unlikely to be augmented with any other signals, such as universal filter multicarrier (assuming that’s what you are asking about). It is by no means a comprehensive data set for modulation recognition. I suppose that’s part of the point: modulation recognition is a hard problem with a wide variety of possible inputs (not even counting propagation-channel effects!), and the input class is growing all the time as new RF communication physical-layer technologies are developed and deployed. We’ll all have trouble keeping up…
D.r. Chad, thank you for the great contribution! My doctoral research is based on the combination of ML&SP(Signal processing). Recently some great ideas occur to me and luckily I find this blog. How to use ML to learn the Fourier transform, this is an interesting topic and my ideas have something in common with it. I think maybe there is no need to totally use ML or expertise in SP either. How about combining them. Like some synthesization signal processing methods. Hoping for the next discussion!
Ym S: Thanks for checking out the CSP Blog!
The next few posts that will appear won’t have to do with Machine Learning. I’m hoping that sometime, somewhere, someone will take up the challenge and post their results. It is likely my non-ML methods will eventually be inferior to some ML method, but so far nobody has shown me their results, even though many have downloaded the data set. We’ll see! At that time, I’ll probably post more on ML and CSP.
Dr. Spooner,
Given the formula for the actual symbol rate given above using base symbol period, upsample factor, and downsample factor, a downsample rate of 0 does not make sense to me, and yet some of the signals have this value in the truth file. Were such signals resampled differently from those with a downsample rate of 1?
JVB: Thanks for visiting the CSP Blog and for paying close attention to my ML-Challenge data set!
I’ve verified your observation. Looking at the data files, when downsample was (inadvertently) set to zero, no resampling took place. So this is equivalent to having the upsample and downsample factors both equal one.
This oversight was also overlooked in my code that computes the error statistics for the CFO estimates, meaning that my errors are slightly better than shown in the figures in the post. Comparing new and old, I don’t think it is worthwhile to replace the figures.
Let me know what else you find!
Hi Chad – great blog!
I have recently downloaded your dataset with 112000 signals (28 batches of 4000 signals each). For each signal (which is a vector of 32768 complex samples) I have extracted the RMS (root-mean-square)-value. (Assuming that my software is bug-free) I have found that for the 1288 signals that have exactly zero CFO (carrier-frequency-offset), the corresponding RMS-values are all in the interval [1.015, 6.38] – while for the remaining 110712 signals the RMS-values lie in the “narrow” interval [0.988, 1.012].
Is there any particular reason for this correlation between CFO and RMS-value?
Hello,
Can you confirm that the SNR values in the files are the corrected/updated ones?
It appears that the example values provided in the blog post may be outdated, as they differ
from the current SNR values (7.883 (file) instead of 5.453 (blog)).
Additionally, could you kindly explain how you determined the noise spectral density in dB
as I have never encountered a NSD in raw dB units ?
I’m also interested in exploring the potential for collaboration.
Would it be possible to get in touch with you to discuss this further?
Thank you
AdaBull:
Thanks for checking out the CSP Blog and the comment! Very helpful.
Yes, I still believe that the inband SNRs in the truth file are correct–they do correspond to the signals in the files. But, yes, the example lines from the truth file that appeared within the body of the post were taken from the original (uncorrected) truth file. I fixed them. So now the SNRs shown in the examples within the body of the post match those found in the truth file.
I am guessing that what you are asking is why don’t I provide the noise spectral density value in Watts/Hz. The reason is that in this situation, for this dataset, and also for most of my signal-processing work, the signals are processed as if the sampling rate is unity,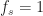 Hz. In such a case, the variance of the noise sequence
Hz. In such a case, the variance of the noise sequence 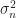 is equal to the spectral density
is equal to the spectral density 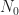 in Watts/Hz.
in Watts/Hz.
Here I set the noise variance to unity, which means the noise spectral density is unity because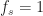 .
.
In many situations in RF signal processing, we have sampled data, and we can write code and equations for processing that data as if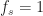 and only at the end, if we want to report a time or frequency, we can scale by the physical value of the sampling rate.
and only at the end, if we want to report a time or frequency, we can scale by the physical value of the sampling rate.
What do you say? Make sense?
I will contact you.
Yes it makes sense, thank you.
I have another question. Have the CFO values been normalized to the sampling rate? They seem very small otherwise, or am I missing something? Thank you!
Adabull: All parameters are normalized in all CSP Blog datasets.
Also, make sure you use the updated versions of the CSPB.ML.2018 and CSPB.ML.2022 datasets:
CSPB.ML.2018R2
CSPB.ML.2022R2