
Previous SPTK Post: Random Processes Next SPTK Post: Echo Detection
In this Signal Processing ToolKit post we take a close look at the basic sampling theorem used daily by signal-processing engineers. Application of the sampling theorem is a way to choose a sampling rate for converting an analog continuous-time signal to a digital discrete-time signal. The former is ubiquitous in the physical world–for example all the radio-frequency signals whizzing around in the air and through your body right now. The latter is ubiquitous in the computing-device world–for example all those digital-audio files on your Discman Itunes Ipod DVD Smartphone Cloud Neuralink Singularity.
So how are those physical real-world analog signals converted to convenient lists of finite-precision numbers that we can apply arithmetic to? For that’s all [digital or cyclostationary] signal processing is at bottom: arithmetic. You might know the basic rule-of-thumb for choosing a sampling rate: Make sure it is at least twice as big as the largest frequency component in the analog signal undergoing the sampling. But why, exactly, and what does ‘largest frequency component’ mean?
Jump straight to ‘Significance of the Sampling Theorem in CSP’ below.
Preliminaries
In the mathematical development, I’m mostly going to use real-valued signals so that the hand-drawn figures and MATLAB-based plots correspond closely to the equations. But the theorem applies to complex-valued signals too, and of course we’ll eventually apply it to things like the CSP-Blog mascot signal.
Let’s focus on a real-valued signal 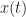
![{\cal{F}}[x(t)] = X(f)](https://s0.wp.com/latex.php?latex=%7B%5Ccal%7BF%7D%7D%5Bx%28t%29%5D+%3D+X%28f%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

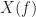

![[-W, W]](https://s0.wp.com/latex.php?latex=%5B-W%2C+W%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)


We want to obtain uniformly spaced samples of the signal 
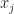



The start of our basic sampling model is illustrated in Figure 2. The signal to be sampled, 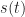
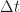

 is small enough relative to the temporal fluctuations in , the areas will be closely approximated by the values at the center of each rectangle:
is small enough relative to the temporal fluctuations in , the areas will be closely approximated by the values at the center of each rectangle:  . [And what is a measure of the rapidity of a signal’s ‘temporal fluctuations?’]
. [And what is a measure of the rapidity of a signal’s ‘temporal fluctuations?’]First we will idealize the sampling model in Figure 2 so that the sampling rectangles become impulses (Dirac delta functions). Then we’ll derive the condition under which the ideal sampling results in a set of numbers that are sufficient to enable recreation of the entire original signal–the sampling theorem. Later we’ll look at non-ideal sampling through the same lens, and discuss some issues surrounding practical uses of sampling.
Ideal Sampling
To idealize the sampling, which creates a sampling scheme or definition that is not physically possible, but is mathematically elegant, we allow the rectangle widths in Figure 2 to approach zero, 

The sampled signal is then the multiplication of

The sampled signal 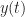

The signal 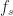
Let’s investigate
First, what is the Fourier transform of
![\displaystyle Y(f) = {\cal{F}} [y(t)] = {\cal{F}}\left[ x(t) \sum_{k=-\infty}^\infty \delta(t - kT_s) \right] \hfill (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Y%28f%29+%3D+%7B%5Ccal%7BF%7D%7D+%5By%28t%29%5D+%3D+%7B%5Ccal%7BF%7D%7D%5Cleft%5B+x%28t%29+%5Csum_%7Bk%3D-%5Cinfty%7D%5E%5Cinfty+%5Cdelta%28t+-+kT_s%29+%5Cright%5D+%5Chfill+%284%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = {\cal{F}} \left[ x(t) s(t) \right] \hfill (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%7B%5Ccal%7BF%7D%7D+%5Cleft%5B+x%28t%29+s%28t%29+%5Cright%5D+%5Chfill+%285%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

where the last equality follows from the convolution theorem. We now recall our work on the periodic impulse train,

which, like any periodic function, is representable by a Fourier series,

where the Fourier coefficients 
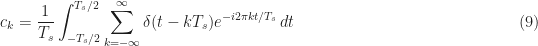


This means we can express the periodic impulse train, which is our sampling function, as the following infinite sum of complex sine waves,

We are now in a position to evaluate the Fourier transform 

![\displaystyle S(f) = {\cal{F}} [s(t)] = {\cal{F}} \left[ \frac{1}{T_s} \sum_{k=-\infty}^\infty e^{i 2 \pi k t/T_s} \right] \hfill (13)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+S%28f%29+%3D+%7B%5Ccal%7BF%7D%7D+%5Bs%28t%29%5D+%3D+%7B%5Ccal%7BF%7D%7D+%5Cleft%5B+%5Cfrac%7B1%7D%7BT_s%7D+%5Csum_%7Bk%3D-%5Cinfty%7D%5E%5Cinfty+e%5E%7Bi+2+%5Cpi+k+t%2FT_s%7D+%5Cright%5D+%5Chfill+%2813%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = \frac{1}{T_s} \sum_{k=-\infty}^\infty {\cal{F}} \left[ e^{i 2 \pi k t /T_s} \right] \hfill (14)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cfrac%7B1%7D%7BT_s%7D+%5Csum_%7Bk%3D-%5Cinfty%7D%5E%5Cinfty+%7B%5Ccal%7BF%7D%7D+%5Cleft%5B+e%5E%7Bi+2+%5Cpi+k+t+%2FT_s%7D+%5Cright%5D+%5Chfill+%2814%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

We can now evaluate the Fourier transform for the sampled signal




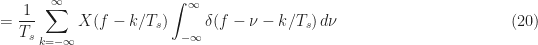
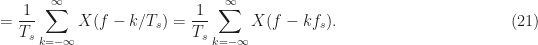
At this point, we can use our cartoonish Fourier transform drawing in Figure (1) to sketch 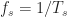
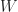
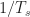

 is greater than .
is greater than .On the other hand, if the sampling rate is smaller than
 is smaller than . Here the aliaes (different ) overlap with their neighbors and so their sum is made up of portions of that are free from contributions from other aliases and portions that are contaminated by other aliases.
is smaller than . Here the aliaes (different ) overlap with their neighbors and so their sum is made up of portions of that are free from contributions from other aliases and portions that are contaminated by other aliases.Finally, if the sampling rate is exactly equal to the number
 equals , the two-sided width of in Figure 1.
equals , the two-sided width of in Figure 1.Now let’s consider using 
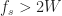
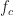

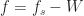

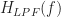 that can be used to select a single alias in the expression (21) for when the sampling rate is large relative to .
that can be used to select a single alias in the expression (21) for when the sampling rate is large relative to .The idea is to pass the ideally sampled signal 
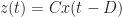

Proceeding in the frequency domain, we have

So right away we see that 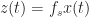

The function of frequency 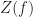

Notice that we can also choose the cutoff frequency of the lowpass filter to be 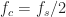

as assumed, and

again, as assumed. So let’s represent the function Z(f) on the interval ![[-f_s/2, f_s/2]](https://s0.wp.com/latex.php?latex=%5B-f_s%2F2%2C+f_s%2F2%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

where the Fourier coefficients are given by



Now the time function


![\displaystyle = \int_{-W}^W \left[ \sum_{k=-\infty}^\infty c_k e^{i2\pi f k/f_s} \right] e^{i 2 \pi f t} \, df \hfill (32)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cint_%7B-W%7D%5EW+%5Cleft%5B+%5Csum_%7Bk%3D-%5Cinfty%7D%5E%5Cinfty+c_k+e%5E%7Bi2%5Cpi+f+k%2Ff_s%7D+%5Cright%5D+e%5E%7Bi+2+%5Cpi+f+t%7D+%5C%2C+df+%5Chfill+%2832%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = \int_{-W}^W \left[ \sum_{k=-\infty}^\infty x(-kT_s) e^{i2\pi f k /f_s} e^{i 2 \pi f t} \right] \, df \hfill (33)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cint_%7B-W%7D%5EW+%5Cleft%5B+%5Csum_%7Bk%3D-%5Cinfty%7D%5E%5Cinfty+x%28-kT_s%29+e%5E%7Bi2%5Cpi+f+k+%2Ff_s%7D+e%5E%7Bi+2+%5Cpi+f+t%7D+%5Cright%5D+%5C%2C+df+%5Chfill+%2833%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

![\displaystyle = \sum_{k=-\infty}^\infty x(-kT_s) \left[ \frac{e^{i2\pi(t-kT_s)W} - e^{-i2\pi(t-kT_s)W}}{i 2 \pi (t-kT_s)} \right] \hfill (35)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Csum_%7Bk%3D-%5Cinfty%7D%5E%5Cinfty+x%28-kT_s%29+%5Cleft%5B+%5Cfrac%7Be%5E%7Bi2%5Cpi%28t-kT_s%29W%7D+-+e%5E%7B-i2%5Cpi%28t-kT_s%29W%7D%7D%7Bi+2+%5Cpi+%28t-kT_s%29%7D+%5Cright%5D+%5Chfill+%2835%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle = \sum_{k=-\infty}^\infty x(-kT_s) \left[ \frac{\sin(2\pi(t-kT_s)W}{\pi (t-kT_s)} \right] \hfill (36)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Csum_%7Bk%3D-%5Cinfty%7D%5E%5Cinfty+x%28-kT_s%29+%5Cleft%5B+%5Cfrac%7B%5Csin%282%5Cpi%28t-kT_s%29W%7D%7B%5Cpi+%28t-kT_s%29%7D+%5Cright%5D+%5Chfill+%2836%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
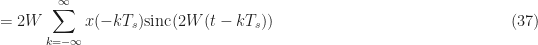

Since
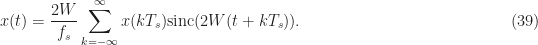
This shows that the signal 
The sampling theorem: A signal whose Fourier transform has support on the intervalseconds.
Undersampling, Critical Sampling, and Oversampling
When the sampling rate is exactly equal to twice the largest frequency component in a signal, 
This figure was created by first generating a highly oversampled signal in MATLAB. Such signals are clearly already discrete-time signals, so we’re cheating a little bit. But we pretend that this original signal is a continuous-time signal to be sampled, and blithely proceed. The 
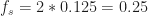
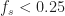


The Case of a Noiseless Sine Wave
When we analyzed the Fourier transform
In the examples illustrated by Figures 1-6, the condition 

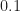 if the sampling rate is strictly greater than twice the largest frequency component, or
if the sampling rate is strictly greater than twice the largest frequency component, or  , or
, or 
Sampling of Random Signals
As we’ve seen in previous posts, random signals are not Fourier transformable. To assess their ‘largest frequency component,’ and thereby enable application of the sampling theorem, we can simply invoke the idea that the power spectrum of the random signal (which should exist for all communication-signal models we have any practical interest in here on the CSP Blog) will allow us to identify the ‘largest frequency component.’ If the signal possesses frequency components outside of the support region of the power spectrum, they will have zero average power, and so even though they might exist in some sense, they cannot substantially contribute to aliases.
So in practice we look at the power spectrum and find the largest frequency component, and then we know how to sample the random signal.
Bandwidth Measures
The rule-of-thumb expression of the sampling theorem is that you must sample with a rate at least as large as twice the largest frequency component in the signal. But what does that last phrase mean? What is ‘the largest frequency component’ in a signal? First, we clarify that the ‘largest’ refers to the frequency of the thing, not its magnitude. (One might sensibly talk about the ‘largest frequency component’ of some transform as the frequency with the largest transform magnitude.)
The remaining issue is to define the largest frequency component so that it makes sense for all kinds of Fourier transformable functions or functions with a well-behaved power spectrum. For the Fourier transform in Figure 1, the largest frequency component is clearly
So here let’s introduce the idea of bandwidth. Like the concept of signal-to-noise ratio (SNR), bandwidth does not have a single definition. The reason is that the basic problem is estimating the width of a function that doesn’t necessarily have edges. Or, in ordinary parlance, what is the width of a lump or bump? The way you might approach defining the width of a lump depends on what you might want to do with that width or with that lump. It might also depend on how much effort you want to put into calculating the lump width.
So here are some common definitions of bandwidth, or lumpwidth. Let the maximum value of the power spectrum be 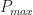
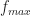
- 3-dB Bandwidth. The frequency interval
such that
is the maximum frequency for which the PSD takes the value
and
is the minimum frequency for which the PSD takes the value
- 10-dB Bandwidth. The frequency interval
and
- 20-dB Bandwidth. The frequency interval
and
- 99% Bandwidth. The frequency interval
% of the power in the signal’s PSD.
- Null-to-Null Bandwidth. The frequency interval
- Occupied Bandwidth. The frequency interval
Some of the bandwidth definitions might not exist for a particular signal’s power spectrum. If the power spectrum never actually goes to zero as the frequency increases without bound, then the definition of occupied bandwidth doesn’t apply (the occupied bandwidth is infinite).
Let’s illustrate these bandwidth measures by looking at some familiar power spectra. These correspond to PSK/QAM signals with rectangular pulses, square-root raised-cosine pulses, and half-cosine pulses. Rectangular pulses are not particularly practical (and this bandwidth analysis reveals why), square-root raised-cosine pulses are widely used practical pulses, and half-cosine pulses figure in common modulations like minimum-shift keying (My Papers [8]).

 .
. .
.

We’re safe in applying the sampling theorem if we always use occupied bandwidth. We’re less safe, but still secure, if we use the 99% bandwidth, because although the aliases will overlap and cause distortion, the amount of distortion is severely limited. On the other hand, if we use the 3-dB bandwidth to determine the ‘largest frequency component,’ we’ll end up in many cases with highly overlapped aliases and no ability to recover the signal using the ideal lowpass filtering described above.
Aliasing
We’ve seen that undersampling, which is always relative to the sampling-theorem rule-of-thumb for the minimum sampling rate value, causes the aliases
When the aliases in (21) overlap, we say we have aliasing in the sampled signal. Returning to the case of the signals in Figure 7, we can employ a sampling rate of 

In some situations, a sampling device is restricted to a smallish set of possible rates. After a rate is selected (for example, on the basis of some possible range of signals that might appear in the data), an appropriate anti-aliasing filter is then selected and routinely applied. This means that the obtained samples will always be a high-quality embodiment of the information at the output of the filter, even if the sampling rate and anti-aliasing filter may not be a good match for all inputs that could be experienced by the system.

Downcoversion to Complex Baseband by Purposeful Undersampling
One of the interesting things about aliasing is that one can use it to one’s advantage instead of always considering it a nuisance. Suppose we apply the sampling theorem to a bandpass signal, rather than to the lowpass signals we’ve been considering so far. By that I mean let’s apply the sampling theorem to a carrier-modulated signal. Such signals have power spectra that are zero or very small near zero frequency, and have their power concentrated near some large carrier frequency, such as 800 MHz (PCS band) or 2.4 GHz (ISM band).
For example, consider the signal with spectrum plotted in red in the upper plot of Figure 14. This modulated signal was formed by mixing the baseband signal, plotted in blue, with a sine wave with frequency 
The largest frequency component of the modulated signal is at about 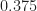
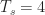

Sampling in MATLAB
The basic tool is resample.m, which has the form Y = resample(X,P,Q). The vector of samples in X is resampled at the rate P/Q. So to double the sampling rate, pick P = 2, Q = 1. To halve the sampling rate, pick P = 1, Q = 2, but if you are going to make the sample rate smaller, take care of anti-aliasing filtering, although there are optional ways to call resample.m so that MATLAB does the anti-aliasing filtering for you. Just watch out.
When trying to convert the sampling rate of some data vector in MATLAB from, say
[n, d] = rat(61.44/50.0)
gives n = 768, d = 625. We can then identify P = n = 768 and Q = d = 625, and we’re ready to call resample.m.
A tool I used to create some of the plots in this post is MATLAB’s upsample.m, which inserts zeros between the samples of its input vector. The call is Y = upsample (X, N). The returned vector Y is X but with N-1 zeros inserted between each pair of adjacent samples in X. If X = [1 2 3 4], and N = 3, then Y looks like
1 0 0 2 0 0 3 0 0 4 0 0
Use of upsample.m allowed easy modeling of the ideally sampled signal, which is an impulse train where the areas of the impulses are modulated by the values of the signal.
Practical Sampling
We can back off our ideal impulse-train sampling set up by just allowing the impulses to be very tall very narrow rectangles. If we do that, we have a sampling function

and our sampled signal is 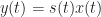
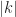
Normalized Frequencies and a Sampling Rate of One
The most common use of ‘sampling frequency’ or ‘sampling rate’ on the CSP Blog is a statement similar to ‘Here we use normalized frequencies, which means the sampling rate is 1.’ The idea is that once you choose a physical sampling rate, hopefully in accordance with the dictates of the sampling theorem, you now have a sequence of complex (usually) numbers to work with internally to your digital signal processing software. The operations you perform on that sequence don’t depend in any meaningful sense on the absolute value of the sampling rate. That is, you can work hard in your software to process the sequence 

With the true physical value of 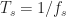
![[-1/2, 1/2]](https://s0.wp.com/latex.php?latex=%5B-1%2F2%2C+1%2F2%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)



The use of normalized frequencies simplifies the coding of digital signal processing algorithms–they can almost always be written as if
Significance of the Sampling Theorem and Sampling Rate in CSP
For the most part, if your data is critically sampled or oversampled, you are in good shape applying second-order CSP, such as various estimators of the spectral correlation function. However, one must be on guard in the time domain. If you want to do direct estimation of the cyclic autocorrelation function, you need to form the lag product 
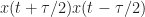

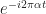
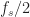
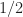
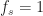
I have encountered engineers over time that casually equate the symbol rate of a digital signal with its bandwidth. This isn’t a problem most of the time. However, if we take it seriously and declare that the significant bandwidth of a digital QAM/PSK signal is equal to its symbol rate, and then use an anti-aliasing filter with bandwidth equal to the symbol rate so we can critically sample at the symbol rate, we will eliminate the non-conjugate cyclic feature(s) of the signal.
To see why this is so, remember that the spectral correlation function measures the temporal correlation between spectrally distinct narrowband components in a time series. For non-conjugate spectral correlation to exist with cycle frequency
So we must preserve whatever bandwidth in excess of the symbol rate that is exhibited by a digital QAM/PSK/CPM signal in order to assess its symbol-rate cyclic features. From this point of view, preserving the occupied bandwidth of the signal throughout the sampling process is a critical system goal for CSP applications.
For higher-order cyclostationary (HOCS) signal processing, the situation is similar to the second-order time-domain situation, but a little worse. We typically want to apply simple homogeneous nonlinearities to our data, in pursuit of temporal moment functions, such as 
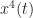
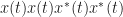
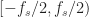
Since this HOCS complication is rather abstract, let’s illustrate with some plots. Consider a BPSK signal with symbol rate 



 is confusing–the cycle frequency pattern is not evident. For example, for fourth order, the cycle frequencies are
is confusing–the cycle frequency pattern is not evident. For example, for fourth order, the cycle frequencies are 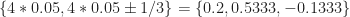 . The cycle frequency
. The cycle frequency  aliases to
aliases to  .
.If we increase the sampling rate by a factor of two, and reprocess, we obtain the results shown in Figure 16. Overall, this result is much more clear, and we can readily imagine processing these functions to find the correct cycle frequency values as well as their correct relative cyclic-moment amplitudes. However, for order six there is still an aliasing problem, as 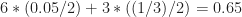

So in the end, if you are doing time-domain HOCS, it is a good idea to oversample your signal prior to the application of the various moment-related nonlinearities. Unfortunately this increases the estimator cost.


For other aspects of and perspectives on sampling in digital signal processing, checkout WaveWalker’s posts on aliasing and spinning objects and on a challenge question regarding the sampling theorem involving sine waves.
Previous SPTK Post: Random Processes Next SPTK Post: Echo Detection
Really nice post Chad, thanks for writing this. I particularly appreciate the description of the different types of bandwidth and the images for the different signals.
Thanks Matt!
Hello!
Thanks for the great tutorial!
I am a bit lost in the steps (9)-(11), is there any issue with equation rendering?
(AFAIK, \int \delta(t)f(t) = f(0), and this justifies the 1/T_s you get at the end, but my math is a bit (too) rusty and so I’m probably missing a step there)
Thanks again!
Rob
Thanks Rob! Yes, there were multiple typos: In (9), (10), and (13), which means there are probably more!
(9): Missing equals sign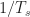
(10): Incorrect upper limit on integral
(13): Missing factor of
Let me know if you still have questions after looking over the corrected equations.
Hello!
Thanks for the quick reply! Indeed, now it makes much more sense 🙂
However, wouldn’t you leave out altogether (10) — which is right now identical to (9) — or rewrite it with the exponential evaluated at t=0 (and thus =1)?
Thanks again and have a nice day!
Rob
Rob: Keep those error detections coming! Made another change. Hopefully it is all good now.
Thanks for the post!
My question is why is the signals being processed always converted to baseband?
The signals are always transmitted at a carrier frequency and received back at that carrier frequency. Why not do the processing at the carrier frequency?
Welcome to the CSP Blog A! Thanks much for the comment.
The main reason I want to process signals at complex baseband (the complex envelope) is that I can process the same number of seconds of data with a much lower sampling rate, thereby reducing computational complexity. That is, obeying the sampling theorem at complex baseband means I can use a sampling rate that is approximately equal to the signal’s bandwidth, which is much much smaller, typically, than the signal’s carrier frequency.
To adequately represent an RF signal with samples, without aliases, you need to sample at approximately twice the carrier frequency (really twice the frequency that is equal to the largest frequency component in the signal, so something like , where
, where  is the occupied bandwidth of the signal at baseband). But this is usually a huge number compared to the critical sampling rate at complex baseband, which is
is the occupied bandwidth of the signal at baseband). But this is usually a huge number compared to the critical sampling rate at complex baseband, which is 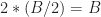 .
.
Buying it?
It as been a while since I commented as I have been busy, but here is my late response. From your response, my understanding is that to sample a signal at a carrier frequency, I would need to sample it at a sampling frequency twice its highest frequency. This gives the equation 2(fc + B/2). From the posts, it is also possible to sample the signal at a lower sampling frequency under certain conditions, called under sampling. However the confusion arises when I read other sources that claim you just need to sample at twice the signals bandwidth regardless if it has a carrier frequency or not. I do not know if I am misreading the sources or they are making these statements under the assumption that the signal is already converted to baseband. If my understanding above is correct then it makes sense to me why signal are converted to IF and baseband frequencies before sampling.
When sampling a RF/bandpass signal with carrier frequency, you have several options:
1) Downconvert the signal to baseband with analog parts (mixers, etc) and then sample it like an ordinary lowpass signal as explained in this post. Note that if the lowpass signal turns out to be a complex, you will need two ADCs to sample the real and imaginary (I/Q) parts.
2) Sample the signal directly at . This will always work (it basically treats the RF signal as a baseband signal with all its energy concentrated around
. This will always work (it basically treats the RF signal as a baseband signal with all its energy concentrated around  ) but is very wasteful as mentioned above by Dr. Spooner.
) but is very wasteful as mentioned above by Dr. Spooner.
3) Sample the signal directly at or more, but be careful since (unlike the baseband case) not all sampling frequencies above
or more, but be careful since (unlike the baseband case) not all sampling frequencies above  are permissible. This restriction stems from the need to ensure there is no spectral mixing between the copies of the bandpass signal at
are permissible. This restriction stems from the need to ensure there is no spectral mixing between the copies of the bandpass signal at  and
and  . Use the figure below to guide you in picking an appropriate sampling rate. Here,
. Use the figure below to guide you in picking an appropriate sampling rate. Here,  , and white regions represent allowed sampling frequencies.
, and white regions represent allowed sampling frequencies.
4) Sample the signal directly at ANY using time-interleaved ADC architecture (the signal is sampled by multiple ADCs separated in time with a small delay). There is no restriction on sampling frequency other than it has to be greater than
using time-interleaved ADC architecture (the signal is sampled by multiple ADCs separated in time with a small delay). There is no restriction on sampling frequency other than it has to be greater than  , but there are restrictions on the timing delay between ADCs if the signal is later to be reconstructed.
, but there are restrictions on the timing delay between ADCs if the signal is later to be reconstructed.
The nomenclature around RF/bandpass sampling can be confusing so I hope this clarifies it for you.
Here is Mansoor’s figure: