
Previous SPTK Post: The Sampling Theorem Next SPTK Post: Resampling in MATLAB
No, not that prisoner’s dilemma. The dilemma of a prisoner that claims, steadfastly, innocence. Even in the face of strong evidence and a fair jury trial.
In this Signal Processing ToolKit cul-de-sac of a post, we’ll look into a signal-processing adventure involving a digital sting recording and a claim of evidence tampering. We’ll be able to use some of our SPTK tools to investigate a real-world data record that might, just might, have been tampered with. (But most probably not!)
More than a decade ago I was connected with a prisoner’s lawyer by a professor I know. The idea was that the lawyer and the prisoner had a hypothesis that the data used to obtain the prisoner’s conviction was tainted, somehow, and that therefore the conviction could, and should, be overturned.
So I went to the meeting with the lawyer, an advocate of the prisoner, and the professor. The lawyer and advocate laid out the charges, details of the conviction and sentencing, and some aspects of the evidence that they were questioning. Weird stuff for a guy that is just trying to understand and use the statistics of communication signals!
Shortly after this, the professor dropped out, convinced of the prisoner’s guilt and understandably reluctant to become associated with a known felon, especially when that association involved possibly freeing said felon.
But I didn’t drop out, wanting to see for myself this evidence, and wanting to understand the puzzle of attempting to prove that it had been tampered with, altered, or otherwise illegally changed. They paid me a bit to do this kind of investigation, as the prisoner was wealthy.
The Evidence
The prisoner was stung. A person carried a concealed recording device and engaged the prisoner in a damning conversation, which was successfully used in the trial. Case closed. Right?
Well, the prisoner says that recording contains things that never were said. So somehow someone somewhere and some time must have altered or replaced that recording. That’s the starting point: Is the recording legitimate?
Now the recording exists as a .wav file. So really, the recording is a sequence of zeros and ones–a discrete-time digital signal. That signal is supposed to faithfully represent an actual audio signal that was present near the recording device at the time of the sting conversation. It’s that audio signal that is the real evidence, but how do we know that the sequence of ones and zeros is faithful to the audio signal during the critical moments of the sting?
If I give you a sequence of zeros and ones and I say ‘these come from an audio recording I made last year,’ or ‘these are the bits that I gathered at the output of my BPSK radio-signal demodulator,’ or ‘these are the bits that correspond to an optical signal I gathered with my telescope,’ how do we really know that is the case? I mean, suppose I flip a bit or two here and there. How could you tell?
For some signals, in some situations, you could tell if a bit were flipped because the sequence of zeros and ones is a coded version of some other source of bits. When you run the decoder, it will tell you which bits are in error, or sometimes just that such-and-such block of bits contains an error. But the problem here is more subtle.
Suppose someone did want to replace a chunk of bits in a .wav file with some other chunk of bits–maybe to make someone’s voice sound funny or cause them to sound like some other person. It could be done by carefully inserting the bits from some other valid recording into a section of the original recording. The result is still a valid .wav file, let’s say. It isn’t in error, it is simply altered from its original state. So here we have that problem–assume the .wav file is valid in format, but has it been altered?
My Investigation
I did three basic signal-processing investigations: blind echo detection, ambient power-system tone analysis, and recording-device integrity.
Echo Detection
Suppose a section of the damning conversation was replaced by something else–something recorded later and with the intention of securing a conviction. How would we know? Well, one could analyze the spectral and temporal characteristics of the involved voices. Is a particular voice consistent throughout the recording? One could look for abrupt non-physical changes in the background sounds (more on that later). Or one might consider that the spliced-in section was recorded inside a small room, whereas the replaced second was recorded outside or in a large room. In such cases, statistics of any voice echos would change due to the splicing-in procedure.
So this suggests that we construct a blind audio-signal echo detector and look for echos in the recording. We know something about where different parts of the conversation took place in terms of indoors or outdoors. Is the echo structure of the recording consistent with that knowledge?
How does one construct a blind echo detector? What is an echo? Let’s assume that an echo is merely a scaled and delayed version of some signal, whether that be a radio-frequency signal (radar) or an audio signal (speech). In other words, an echo is a reflected version of a signal. So if our signal is 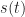

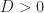
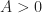
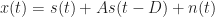
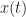
Assuming infinitely long time-series
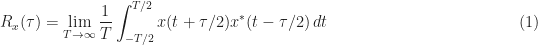
by using our expression for

Knowing that the autocorrelation for any signal has a maximum at 




In this work, then, my blind echo detector is simply the identification of the maximum magnitudes of an autocorrelation estimate over some proscribed range of autocorrelation lags. However, there are complications in the real world that we’ll have to deal with. These are introduced and illustrated with an example.
Example with Synthetic Signals
Our synthetic signal of interest is a simulated amplitude-modulated (AM) signal with a Gaussian-noise message, mimicking speech but without on and off times indicative of a sequence of uttered words and sentences. The real-valued version of this signal is sampled at 11050 Hz, but the processing uses the corresponding complex envelope, which has a sampling rate of half that, or 5525 Hz.
To simulate echos, I add two delayed versions of the simulated audio signal to itself. The delays are 12.7 and 21.7 ms. Are these reasonable? The speed of sound in air is about 340 m/s (it depends on temperature). Let’s say a reflector is 2 meters away from the source and the sensor is colocated with the source, so that the round-trip distance the sound takes to return to the source is about 4 meters. This corresponds to a delay of D = 4/340 = 11.7 ms, so our delay choices are in the neighborhood of echos that might occur in a small room, vehicle, etc.
In addition to adding the echos to the simulated audio signal, I also added a narrowband digital signal and a sine wave. The bandwidth of the narrowband signal is approximately 200 Hz and the sine-wave frequency is 221 Hz. These represent signals seen in some parts of the sting recording, and their presence can complicate the detection of the echos of the audio signal of interest, so it is helpful to include them in the simulated signal to determine whether or not a particular echo detection algorithm can work in their presence.
A significant complication arises when a sine wave is present because a sine wave is its own echo. Recall that the autocorrelation function for a sine wave is just that same sine wave. Therefore to an echo detector it will appear that there are an infinite number of echos. So we’ll have to do something about that prior to looking for echos related to the audio signal.
The simulated audio signal, with and without the complicating sine-wave and narrowband signal components, is shown in terms of its power spectral density in Figure 1.

Much more interesting, and to the point, is the view of these signals in terms of their autocorrelation functions, as shown in Figure 2.

For the two cases of with echos and without echos, and always with the interferers present, I perform the autocorrelation-based echo detection with and without sine-wave excision. The sine-wave excision is simple: null the top 

Case 1: Echos Present and No Sine-Wave Excision
In this case, the audio signal, its echos, the narrowband signal, and the tone are all present. The autocorrelation-based echo detector is applied and the strongest echo is recorded. The history of echo-delay estimates over time is shown in Figure 3.

Perhaps a better way to view the results, as we’ll see as the cases unfold, is through a histogram of the echo-delay estimates. The histogram for the Case 1 results in Figure 3 are shown in Figure 4.

Notice the pattern in Figure 4–there are clusters of echos at each multiple of the sine-wave period. That period is 1/221 = 0.0045 s, so the multiples are 0.0045, 0.009, 0.014, 0.018, 0.023, 0.027, 
Case 2: Echos Present with Sine-Wave Excision
Now let’s apply our simple sine-wave detection and excision algorithm to each data block prior to applying autocorrelation-based echo-delay detection. The time history of the echo-delay estimates is shown in Figure 5.

The histogram of echo-delay estimates corresponding to the estimate history of Figure 5 is shown in Figure 6.

Here we see that the overwhelming majority of the echo-delay estimates correspond to one or the other of the (equal-strength) echos at 12.7 and 21.7 ms. This indicates that sine-wave excision is critical for echo detection in any situation where sine waves may corrupt the captured data. A reasonable detector that attempts to decide between ‘echos present’ and ‘echos absent’ could operate on the histogram, measuring its spread and number of significant modes.
To be sure that this simple estimator works well when there are not actually echos present, we need to look at two more cases: No echos and no sine-wave excision, and no echos with sine-wave excision.
Case 3: No Echos Present and No Sine-Wave Excision
Figure 7 shows the echo-delay history for the case of no audio-signal echos present and no sine-wave excision is applied. This history looks similar in character to Figure 3, where audio-signal echos are present. We should suspect that the echo-delay estimates are dominated by the pseudo-echos arising from the unexcised sine wave.

The histogram of echo-delay estimates from Figure 7 are shown in Figure 8, where indeed we do see the echo delays appearing at multiples of the sine-wave period (0.0045 s).

Case 4: No Echos Present with Sine-Wave Excision
In the final preliminary case that we consider for validation of the overall echo-delay estimation concept, we apply the echo detector to the baseline signal where no audio-signal echos are present but we apply the sine-wave detection and excision process. The time history of the obtained echo-delay estimates is shown in Figure 9 and the corresponding histogram in Figure 10.


Here we see that the clumps of echo-delay estimates at multiples of the sine-wave period 0.0045 seconds are no longer evident. The relatively large number of echo-delay estimates near zero is due to the facts that the method is constrained to produce an estimate for each visited data subblock and that the audio signal and narrowband interferer have autocorrelation functions that are larger near zero than far away from zero (revisit Figure 2). This brings us to a final algorithm-development consideration, which is how to threshold the estimated echo strength (autocorrelation function peak value) so that when no echo is present we return an echo-delay estimate of zero, and when an echo is present, we return the echo delay?
Echo Detection with Echo-Strength Thresholding
We don’t know in advance of processing some time-domain data if there are any echos present, or if there are always echos present, or something inbetween. From Figure 2, we know that for at least some echos, the strength of the autocorrelation for a lag variable 
But how to choose the threshold?
Aside My signal-processing pals and I often say that most of signal processing reduces to peak-picking. And by peak-picking we mean finding the maxima of some noisy function, like the autocorrelation in Figure 2 above. Lots of time is spent in college learning how to optimally peak-pick. That is, learning some mathematical methods for determining the optimal threshold to use when, well, picking the peaks. However, like many things in engineering school, such methods are difficult to apply because they rely on unrealistic assumptions about the function to be peak-picked and/or they require unknowable information. So ... there's an art to picking a threshold, and oftentimes we don't care if we aren't using the optimal one, even if it does exist. We care about doing good enough (also known as meeting the engineering requirements).
Recalling our threshold discussions in the context of the Cycle Detectors, we can start building some intuition about threshold selection by looking at the probability density functions of the involved random variables. Ok, who said anything about random variables? Or random processes?
Random variables and random processes are at least implicit in the echo-detection context. The echo delay and strength can be modeled as random variables, and the discrete-time voltage recording is clearly a sample path of a random process. Whether we can provide accurate models (mathematical descriptions) of these random variables and processes is another question. This brings up a basic dichotomy in signal processing: parametric methods versus non-parametric methods.
In parametric methods, an explicit model is assumed for the data (signal) to be processed, and typically the detection or estimation problem at hand reduces to estimation of a small number of parameters in the model. For example, assume a noisy sine wave, and estimate the amplitude, frequency, and phase. In non-parametric methods, no particular model is assumed, and more generic tools are used to perform the detection and estimation tasks. This is typically the case at the CSP Blog, and explains why we try to use things like the autocorrelation, cyclic autocorrelation, spectral correlation function, cycle frequencies, cyclic cumulants, etc., to do our work.
This is all a long-winded way of saying that I’m not going to assume a particular form for the echo-strength random variable. Instead I’m going to use basic non-parametric tools, such as an estimate of the probability density function, to find a reasonable (read: good but not provably optimal) threshold. Once I have that threshold, I can use it to say if any particular peak in the autocorrelation search range corresponds to an echo or not.
I’ll elaborate on some experiments in another section of this post, but for now consider an experiment where I use a Sony ICD-PX820 personal audio recorder to capture the sounds in my office. I turn the recorder on and clap my hands together every 3-6 seconds or so. Then I analyze the recorded data for echos. The two strongest returned echo strengths (for some reasonable processing parameters such as block length and search window [Figure 2]) are plotted in Figure 11.

We can see that the strength of the autocorrelation peak is consistently larger every few seconds, consistent with the notion that the detector is really finding the echos of my claps. The histogram of these strengths is the current topic, and histograms can be scaled such that they are good probability density estimates, and probability density estimates can be integrated to yield cumulative distribution estimates. These are shown for the Position-1 Office Clapping experiment in Figure 12.

So here is how I calculate a threshold. For some input signal that I want to analyze, I run the autocorrelation-peak echo-detector I’ve described and collect the results. I then subject the obtained echo-strength values to a CDF analysis and find the echo-strength that is closest to a probability of 0.5 (that would be about 0.0005 in Figure 12). That echo strength is then the threshold for the experiment–echos are declared present and reported only when the echo strength is greater than the CDF=0.5 threshold. When I use this threshold on the Position-1 Office Clapping data, I get the time-history of echo-delay estimates shown in Figure 13.

Are these echo-delay estimates reasonable? The office is about 3 m by 4 m by 4 m, and recall that the speed of sound in room-temperature air is about 340 m/s. So a sound wave starting at one wall, bouncing off the far wall, and returning might travel 6-8 m, which corresponds to 0.018-0.024 seconds. Echos related to bounces off office furniture or the ceiling will be shorter. And that range is quite consistent with the thresholded echo-delay estimates in Figure 13. So I think the basic echo-detector is valid.
Echo Detection Experiments
The echos we are most concerned with in the sting recording are voice echos rather than hand-claps, but I did want to do some initial experiments with claps because they are loud and short. I expected that a clapping experiment would be the easiest kind of experiment for the echo detector. In the previous section, I showed results for clapping in my office. I repeated this several times in different locations within the office and got similar results.
I then moved on to a smaller room–a rather small bathroom but with a high ceiling and a skylight. The detected echo delays are shown in Figure 14 and the empirical PDF and CDF are shown in Figure 15.


Compared to the Office Clapping results, we see a wider range of echo delays in the Bathroom Clapping experiment, perhaps due to the high ceiling. Next I clapped inside my small car (a 1996 Toyota Corolla, long since gone to pasture). The echo-delay history is shown in Figure 16 and the probability functions in Figure 17. Here we see, as might be expected, that the estimated echo delays are generally quite a bit smaller than those in the office and bathroom.


We can observe that the threshold corresponding to the CDF value of 0.5 appears to be a good choice in that the PDF mode corresponding to the lack of echos is generally to the left of that threshold, and the various echo-strengths corresponding to actual echos are generally to the right. Reasonable peak-picking?
Let’s move on to speech-induced echos.
Probably the most interesting voice experiment is when I was reading aloud in the aforementioned Corolla. I read for a while, with all the windows up in a reasonably quiet parking lot, then was simply silent in the car for a while. The results are shown in Figures 18 and 19.


I did quite a few more experiments, but it’s working, right? So I’ll spare you more examples.
Echo Detection Applied to the Sting Recording
The results of applying the described echo-detection algorithm to the sting recording are shown in Figure 20. Smoothed histograms of the echo-delay estimates for various subintervals of the recording are shown in Figure 21.
The environment surrounding the sting audio recorder can be reasonably inferred from the recording itself and testimony about the movements of the person carrying the (concealed) recorder–so we know which intervals are supposed to correspond to indoors and which to outdoors. The conclusion is that the presence of echos in the echo-history graph of Figure 20 is indeed consistent with the classification of each interval as indoors or outdoors–no anomalous echos were found with any confidence.

The detected echo-delays in each five-minute period are gathered and used to create histograms, which are then smoothed to be more easily understood. The results are shown in Figure 21.

For perspective, I also provide smoothed histograms for some of my experiments in Figure 22. The crucial part of the sting is minutes 45-57, which took place outdoors, and we see little evidence of echos that might indicate a doctored or altered recording in those minutes.

So that’s the end of the echo-detection adventure. I think the value of writing all this down for you is the illustration of how to put together a signal-processing algorithm by using basic, solid building blocks like the autocorrelation, probability density, and cumulative distribution functions, rather than the final sting-recording results. And to not get hung up on optimality and mathematical modeling when those things are out of reach anyway.
Power-System-Tone and Recording-Device Integrity
The defense team had other suspicions about the integrity of the recording. One of these was that the 60-Hz sine wave originating from devices connected to the US electrical grid (Europe uses 50 Hz) sometimes appeared doubled–two closely space lines instead of one. Might this indicate some kind of overlay of a recording on top of the original, but with the overlay having a slight frequency shift?
The audio recorder can hear the 60-Hz hum, believe it or not. I looked closely at spectrograms of the sting recording, but also did some experiments to orient myself on what to expect. A spectrogram is just a temporal sequence of power spectral density (PSD) estimates, or in some cases a temporal sequence of Fourier transform magnitudes or even complex-valued Fourier transform values. The time dimension is usually the vertical dimension in a spectrogram plot.
It turns out that fluorescent lights hum louder at the second harmonic of the 60-Hz electric network frequency, or 120 Hz. I found evidence of both 60 Hz and 120 Hz in my office and when I took the recorder over to Trader Joe’s. See Figures 23-25.



Turning to the sting, we see that there are no inconsistencies. It appears that the sting conversation took place near a humming fluorescent light or two. See Figures 26-27.


I did some further work on understanding whether or not one could alter a recording while still stored on the recording device, but this came up empty too. It involved modeling and simulating some linear time-invariant systems (filters), and in particular a couple non-ideal high-pass filters.
In the end, every avenue of investigation I took came up with the same result: The recording is legitimate. If the null hypothesis 
Previous SPTK Post: The Sampling Theorem Next SPTK Post: Resampling in MATLAB
You should do more true crime signal processing. I was on the edge of my seat. Fascinating read. Great to see how you approached the problem from scratch and the processing of an audio signal.
Thanks Dylan! Gratifying to hear. I would love to try some more forensic signal processing, but my day job and the CSP Blog have been overwhelming for the past couple years.
That was very interesting, Chad. I’m always surprised with how far one can go armed with a solid grasp of the fundamentals, attention to detail, and quite a bit of hard work. Thanks for taking the time to share it with us!