
Reader Gideon pointed out that Antoni had published a paper a year after the paper that I considered in my first Antoni post. This newer paper, The Literature [R172], promises a faster fast spectral correlation estimator, and it delivers on that according to the analysis in the paper. However, I think the faster fast spectral correlation estimator is just as limited as the slower fast spectral correlation estimator when considered in the context of communication-signal processing.
And, to be fair, Antoni doesn’t often consider the context of communication-signal processing. His favored application is fault detection in mechanical systems with rotating parts. But I still don’t think the way he compares his fast and faster estimators to conventional estimators is fair. The reason is that his estimators are both severely limited in the maximum cycle frequency that can be processed, relative to the maximum cycle frequency that is possible.
Let’s take a look.
What the Paper Says
The authors take a closer look at their previous short-time Fourier-transform method of computing the spectral correlation function for small values of the cycle frequency, and replace some of the operations with faster ones.
Antoni starts off describing why this is worth doing: traditional methods of spectral correlation estimation are too slow. The core of the argument is in Figure 1.

Antoni attributes the bulk of the slowness of the time-smoothing method to the multiplication of the input data by complex exponentials with frequencies 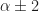

The real problem with those methods is the computation of the cyclic periodogram for each cycle frequency of interest; see the computational costs post for more details.
The authors then go on to discuss the approach to their method, and they explicitly state that the algorithm user must choose a maximum cycle frequency 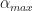

 . Note that has a minimum value of unity, so that the largest possible value for is half the sampling rate.
. Note that has a minimum value of unity, so that the largest possible value for is half the sampling rate.This is strange, because we know that the cycle frequencies in discrete-time CSP range from 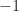
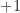
But it isn’t a misreading. Later we see that the authors equate a full spectral correlation analysis to looking at all cycle frequencies up to half the sampling rate, as seen in Figure 3.

After the brief explanation of the new, faster version of the limited-cycle-frequency estimator, Table 3 shows how much faster the new method is relative to the old method, and throws in some computational counts for the “traditional operations.” But I can’t figure out if that means his idea of the ACP (TSM) or the strip spectral correlation analyzer (SSCA), which is also mentioned in the paper.

What is important to note is the fourth column. The computational advantage is largest for the largest considered 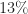
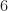
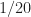
Whether “Complexity traditional Operations” refers to Antoni’s version of the TSM, my version of the TSM, or the SSCA, the comparison is inapt if we take seriously the idea that only very small cycle frequencies are of interest. We’ll discuss that more below.
The Maximum Possible Cycle Frequency is Not Half the Sampling Rate
Whether the data to be processed is real-valued or complex-valued, the maximum value of the cycle frequency is the sampling rate. When we operate in normalized frequencies, as we often do here at the CSP Blog, then the cycle frequency ranges from 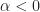
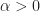
![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
But Antoni et al are interested in real-valued signals, so there is no distinction between the non-conjugate and conjugate spectral correlation functions. They are identical. However, we still need to consider all cycle frequencies on ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Using real-valued signals doesn’t imply that the maximum cycle frequency that can be exhibited by some data is half the sampling rate. Let me give a couple numerical examples to illustrate and validate the idea.
First consider a real-valued BPSK signal with a carrier frequency near half the sampling rate. A PSD estimate for such a simulated signal is shown in Figure 5.
 and carrier frequency
and carrier frequency 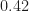 .
.We expect this signal to have cycle frequencies equal to plus-and-minus the bit rate, the doubled-carrier plus-and-minus the bit rate, and the negative doubled-carrier plus-and-minus the bit rate. And zero. Don’t forget about power. And that is what we see when we pass this data through the FFT Accumulation Method (FAM), the SSCA, the TSM-in-a-loop, or the FSM-in-a-loop. Figure 6 shows the spectral correlation surface for blindly estimated cycle frequencies (SSCA) followed by high-fidelity spectral correlation function estimation for just those cycle frequencies (FSM).

We can also see important cycle frequencies in excess of half the sampling rate for signals whose carrier is not pushed near half the sampling rate, such as for the real-valued direct-sequence spread-spectrum QPSK signal with PSD shown in Figure 7.

 .
.Using the same SSCA-based blind-CF estimation step followed by high-fidelity spectral correlation function estimation by the FSM, we obtain the surface shown in Figure 8.

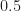 ).
).In the previous post, I also showed an example of a complex-valued communication signal with a single non-zero non-conjugate cycle frequency that was greatly in excess of half the sampling rate: BPSK with square-root raised-cosine pulses that is nearly critically sampled. That example is recreated in Figures 9 and 10 here.


 kHz.
kHz.A Better Comparison
The comparison in Table 3 (Figure 4 here) to “traditional” estimators is not particularly apt. The reason is that if you want to focus exclusively on tiny cycle frequencies (and sometimes I do! Tunneling!), then you can often drastically bandlimit your data, subsample (decimate), and process the new data sequence. The overall number of seconds of processing-block length is the same as you started with, but the number of samples is much smaller, and so is the range of cycle frequencies that can be estimated.
For instance, if we take the signal Antoni bundles with his code seriously, we see that it is oversampled, as in Figure 11 (which is Figure 3 in the original post).

Further, we see that the cycle frequencies are plus-and-minus 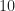

But the same trick doesn’t apply to Antoni’s method–it requires oversampled data. If you apply it to the reduced data as I outlined, then you’ll be stuck with an

Conclusion
So, yes, the new Antoni algorithm is faster than the old Antoni algorithm. They are both still of very limited value in the context of communication-signal processing due to the highly constrained maximum cycle frequency that can be accommodated by the method.
Looking at Table 1 in the previous post, we can say that the new algorithm narrows the gap between the faster ‘SSCA for all cycle frequencies’ and the slower ‘FSC for a small fraction of cycle frequencies.’ But the new paper does not consider that outside of the FSC framework, we can simply refuse to oversample the signal. Then the gap widens, again, between ‘SSCA for all cycle frequencies’ and ‘FSC for a small fraction of cycle frequencies.’
Buying it?
Hi, the traditional method in his paper is the reference from 2017. In his application, he does not need a high a_max – due to the physics of his problem. The question is, if under the conditions described, you think that there is a better method. I have made several comparisons to the ACP and it seems that it performs well….