Understanding and Using the Statistics of Communication Signals
Computational Costs for Spectral Correlation Estimators
The costs strongly depend on whether you have prior cycle-frequency information or not.
Let’s look at the computational costs for spectral-correlation analysis using the three main estimators I’ve previously described on the CSP Blog: the frequency-smoothing method (FSM), the time-smoothing method (TSM), and the strip spectral correlation analyzer (SSCA).
We’ll see that the FSM and TSM are the low-cost options when estimating the spectral correlation function for a few cycle frequencies and that the SSCA is the low-cost option when estimating the spectral correlation function for many cycle frequencies. That is, the TSM and FSM are good options for directed analysis using prior information (values of cycle frequencies) and the SSCA is a good option for exhaustive blind analysis, for which there is no prior information available.
The Cost of the Frequency-Smoothing Method
Recall that the FSM convolves the cyclic periodogram with a pulse-like smoothing window . The cyclic periodogram is defined by
for a complex-valued power signal with sliding -point Fourier transform for the data segment that is centered at time and having width samples. A complication occurs when the cycle frequency is such that is not equal to an integer number of frequency-bin widths . This complication is discussed in the FSM post, and isn’t important for our cost analysis.
To obtain an estimate of the SCF, we convolve the cyclic periodogram with the smoothing function :
So the cost of the FSM is the sum of the costs for (1) the FFT, (2) computing the cyclic periodogram, and (3) the convolution with . The FFT has approximate cost of complex operations, the cyclic periodogram costs approximately complex operations, and the convolution cost depends on the number of frequency points contained within the width of . In the special case of a rectangular , however, the cost can be reduced to approximately operations.
For example, if samples, then the FFT cost is , the cyclic periodogram cost is , and the smoothing is , indicating that the dominant cost is the FFT.
The Cost of the Time-Smoothing Method
In the TSM, multiple relatively short-duration data blocks are used to estimate multiple cyclic periodograms, which are then phase-shifted and averaged. As in the FSM analysis, let the total number of samples to be processed equal . The sub-block length is , so that individual cyclic periodograms are averaged.
The cost calculations are straightforward. Each -point FFT costs operations, each scaling by the complex-valued scale factor costs operations, and the summing of the scaled cyclic periodograms costs operations. So the cost is about
The Cost of the Strip Spectral Correlation Analyzer
The SSCA employs three major computational steps. The first is a FFT-based channelization step. The size of the FFT is (the number of strips), which is applied to successive -long data blocks obtained by sliding forward in time by samples. As before, the total number of processed data samples is . Typically I used because I do not need to limit the memory requirement for the channelizer output. In this case, there are data blocks of size to process through the channelizer, and since in all cases of practical interest, we’ll approximate this by . So the cost for the channelizer stage is FFTs of length , or .
The second SSCA computation is the multiplication of the original complex-valued data by each of the channelizer outputs, creating new complex-valued sequences of length . This requires operations.
The final step in the estimation of the spectral correlation function using the SSCA is to apply an -point FFT to each of the sequences obtained from the second step. So this cost is approximately
or
The Cost of Computing the Spectral Coherence
Recall that the spectral coherence is the correlation coefficient corresponding to the correlation that is the spectral correlation function:
For each spectral correlation point estimate we have to multiply two PSD values together, take the square root of that product, and then divide the point estimate by the result. Each of those normalization steps costs two multiplications and one square root. We’ll count this as three operations.
Comparisons
First let’s compare the costs for the three algorithms when we use them to perform exhaustive spectral correlation and spectral coherence analysis. Including the coherence is important because it is the function that is used to do the actual cycle-frequency detection. In these comparisons the three algorithms process the same number of samples and are set up with the same frequency resolution, which is about in normalized Hz. Here we take the cost for the FSM and multiply by the number of cycle frequencies that make up the principal domain of the discrete-time/discrete-frequency spectral correlation in the – plane, which we’ll take to be
Figure 1. Theoretical operation counts for the FSM, TSM, and SSCA methods of estimating the spectral correlation function.
To verify these trends, I also ran my C-language versions of the three algorithms and measured the elapsed times:
Figure 2. Measured elapsed times for C implementations of the FSM, TSM, and SSCA methods of estimating spectral correlation. Here the algorithms were used to estimate the spectral correlation function over its entire principal domain.
Now, what about the case where we just want the spectral correlation function or spectral coherence function (or both) for a single cycle frequency? This might happen, for example, in the context of the cycle detectors. For the TSM and FSM, we just have the single-cycle-frequency costs described above. But for the SSCA, we realize that we can’t get at the function as a function of without, in general, combining elements multiple strips. We could create another algorithm that doesn’t perform the final -sample FFTs, but instead computes only the particular DFT coefficients that correspond to for each , or we can just apply the usual SSCA and extract the needed spectral correlation and coherence values. If we do the latter, we have the cost comparison:
Figure 3. Theoretical computational costs for the TSM, FSM, and SSCA methods of estimating the spectral correlation function. Here the algorithms are used to obtain the estimate for a single cycle frequency.
I’ll be referring to the content of this post in my upcoming post on tunneling (also see here). So let me know if you see errors or issues!
Author: Chad Spooner
I'm a signal processing researcher specializing in cyclostationary signal processing (CSP) for communication signals. I hope to use this blog to help others with their cyclo-projects and to learn more about how CSP is being used and extended worldwide.
View all posts by Chad Spooner
2 thoughts on “Computational Costs for Spectral Correlation Estimators”
Is the focused estimator(TSM/FSM) evaluated at the same frequency resolution as the SSCA? As far as I know, the frequency resolution is proportional to and results in larger computation effort.
Hey Philo6! Thanks for the comment. Yes, the three estimators in the post employ the same processing block length and the same effective spectral resolution. The latter is for all three, and the former is varied to produce the plots. I’ve added a statement to the post to make this clear.

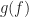
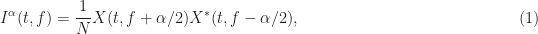
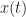







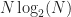

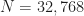


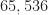



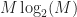


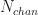

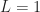

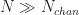



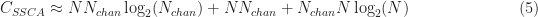

![\displaystyle C_x^\alpha(f) = \frac{S_x^\alpha(f)}{\left[ S_x^0(f+\alpha/2) S_x^0(f-\alpha/2)\right]^{1/2}} \hfill (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+C_x%5E%5Calpha%28f%29+%3D+%5Cfrac%7BS_x%5E%5Calpha%28f%29%7D%7B%5Cleft%5B+S_x%5E0%28f%2B%5Calpha%2F2%29+S_x%5E0%28f-%5Calpha%2F2%29%5Cright%5D%5E%7B1%2F2%7D%7D+%5Chfill+%287%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
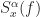
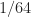





Is the focused estimator(TSM/FSM) evaluated at the same frequency resolution as the SSCA? As far as I know, the frequency resolution is proportional to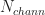 and results in larger computation effort.
and results in larger computation effort.
Hey Philo6! Thanks for the comment. Yes, the three estimators in the post employ the same processing block length and the same effective spectral resolution. The latter is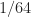 for all three, and the former is varied to produce the plots. I’ve added a statement to the post to make this clear.
for all three, and the former is varied to produce the plots. I’ve added a statement to the post to make this clear.