
This post is just a blog post. Just some guy on the internet thinking out loud. If you have relevant thoughts or arguments you’d like to advance, please leave them in the Comments section at the end of the post.
How did we, as people not machines, learn to do cyclostationary signal processing? We’ve successfully applied it to many real-world problems, such as weak-signal detection, interference-tolerant detection, interference-tolerant time-delay estimation, modulation recognition, joint multiple-cochannel-signal modulation recognition (My Papers [25,26,28,38,43]), synchronization (The Literature [R7]), beamforming (The Literature [R102,R103]), direction-finding (The Literature [R104-R106]), detection of imminent mechanical failures (The Literature [R017-R109]), linear time-invariant system identification (The Literature [R110-R115]), and linear periodically time-variant filtering for cochannel signal separation (FRESH filtering) (My Papers [45], The Literature [R6]).
How did this come about? Is it even interesting to ask the question? Well, it is to me. I ask it because of the current hot topic in signal processing: machine learning. And in particular, machine learning applied to modulation recognition (see here and here and here and here). The machine learners want to capitalize on the success of machine learning as applied to image recognition by directly applying the same sorts of image-recognition techniques to the problem of automatic type-recognition for human-made electromagnetic waves.
One dominant modulation-recognition algorithm construction method is to present the machine with a large number of sampled-data vectors, each with a modulation-type label, and let the machine learn a mathematical operation it needs to get the output label right almost all the time. That’s my understanding of how the image-recognition systems work too: amass a great number of images, all labeled, and present them to the machine along with the labels, and the machine figures out how to adjust its many internal parameters to get most of the labels correct. The human work seems to be pushed into the setting up of the machine’s structure and hyperparameters, and amassing the correctly labeled training images, which is non-trivial work.
Is that how we do it as humans? I think what I described is in fact the long-running analogy. The machines here are artificial neural networks, explicitly modeled after actual neural networks in physical animal brains, and the presentation of a large number of labeled images is like an accelerated version of our biological learning to recognize images with our eye-brain system as we encounter more and more of them over time with external agents (parents!) providing the labels. This process reinforces our network weights and/or thresholds when we’re correct about a label and permits their adjustment when we are wrong.
I’m probably mangling this description, but so far it agrees with what I, as an interested machine-learning bystander novice have seen over the past few decades. So it appears to me that there are strong parallels between how we humans learn to recognize images and how the best machines learn to recognize images.
But what about recognition of electromagnetic wave types? It appears that the direct application of the image-recognition style of machine learning has not yet met with the desired level of success. Something seems different about this kind of classification/recognition problem. Is that true? If so, what is it?
Learning CSP: Adding Infinities to Data Models
Well, how did we learn to apply CSP to modulation recognition? Taking one step back, how did we learn CSP itself? Although we always process a finite-length data record in the practice of CSP, the theoretical functions we are estimating using CSP arise from fictitious models that involve one or more kinds of infinities. In other words, we didn’t learn all of our favorite probabilistic functions such as the cyclic autocorrelation, spectral correlation function, cyclic temporal cumulants, spectral coherence, and cyclic polyspectra by exposing ourselves to a large number of finite-length data records and passing them through random nonlinearities, keeping those that ‘look right’ and discarding the rest. Instead, we adopted one of two mathematical models (The Literature [R67]) for a received (typically human-made) electromagnetic signal.
Model 1: Conventional Persistent Stochastic Processes and the Ensemble Probability
Most of us learn about the autocorrelation, the power spectral density, higher-order statistics, and even cyclostationary signal processing using a mathematical framework involving stochastic processes, which are also called random processes. A random process is the extension of a random variable from a scalar value to a function of time, space, or some other independent variable.
The idea is that the random process is a collection of all possible (where possible is governed by the probability distributions of all involved random variables in the process) sample paths, or instances, of the function of time. This collection, together with the associated probability distributions, is called the ensemble. The ensemble in communication engineering (and statistical signal processing for communication signals and systems) is usually an infinite set of signal instances each of which extends infinitely in time in both directions. A graph of an ensemble is shown here:

The main tool we use with random processes is the expectation, usually denoted by the operator ![E[\cdot]](https://s0.wp.com/latex.php?latex=E%5B%5Ccdot%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle E[X(t)] = \int x P_x (t,\boldsymbol{\theta}) \, dx, \hfill (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX%28t%29%5D+%3D+%5Cint+x+P_x+%28t%2C%5Cboldsymbol%7B%5Ctheta%7D%29+%5C%2C+dx%2C+%5Chfill+%281%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
and the autocorrelation function, which is the average value of a quadratic function of the process,
![\displaystyle E[X(t_1)X^*(t_2)] = \int \int x_1 x_2^* P_{x_1,x_2} (t_1, t_2, \boldsymbol{\theta}) \, dx_1 dx_2. \hfill (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX%28t_1%29X%5E%2A%28t_2%29%5D+%3D+%5Cint+%5Cint+x_1+x_2%5E%2A+P_%7Bx_1%2Cx_2%7D+%28t_1%2C+t_2%2C+%5Cboldsymbol%7B%5Ctheta%7D%29+%5C%2C+dx_1+dx_2.+%5Chfill+%282%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Here 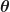

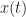
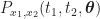
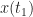
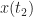
The relevant point for this post is that to get to the autocorrelation function, power spectrum, cyclic cumulants, etc., using random processes, you have to introduce two infinities in your data model: the vertical infinity corresponding to all the different possible combinations of values of the involved random variables, and the horizontal infinity (time), which accounts for the signal having finite non-zero power (persistence). That model is a far cry from, say, modulated-signal data snippets that correspond to 8 symbols.
There is an alternative model, but it still requires one of the infinities.
Model 2: A Single Persistent Power Signal and Fraction-of-Time Probability
The second model is simpler in that there is no ensemble, but the signal is still modeled as having infinite extent in time (or space). Variables such as carrier phase, symbol-clock phase, average power are assumed to be unknown constants rather than random variables. This is consistent with the notion that a receiver for communication signals has to deal with both a single carrier phase over a large amount of time (before it drifts significantly, say), and a rapidly randomly time-varying message. The receiver doesn’t ever have to deal with an ensemble, just with one particular electromagnetic signal. Cumulative probability distributions, probability densities, and the expectation can all be defined using a single persistent signal model and a frequentist-style definition of probability known as fraction-of-time probability (The Literature [R8,R67]).
The notion of an infinite-duration signal is clearly inconsistent with signal-processing practice, but it is appealing from the point of view of signals that persist for much longer than the longest data block that we could hope to process. Also, modeling a signal as infinitely persistent is consistent with those situations in which algorithm performance depends on the length of the data block. We could process some captured data with length 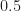


This model also has a fundamental tool: the sine-wave extraction operator ![E^{\alpha}[\cdot]](https://s0.wp.com/latex.php?latex=E%5E%7B%5Calpha%7D%5B%5Ccdot%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Returning to image classification using machine learning, I perceive no fruitful modeling of the images that would involve infinities; the images we want to recognize are inherently finite in extent (length and width). We could represent each pixel by a real number, so that we have an infinity of color values, but when we represent the image in a computer, it will inevitably have a finite number of possible pixel values due to the inherent properties of the digital numbers. There is no “waiting a little longer” to obtain more of the image.

[OK, maybe the CSP Blog is complete. I’ve found a way to include an image of a cat on the site, so the site is now a proper part of the internets.]
I suppose the image-recognition problem is similar to the speech-recognition problem where the recognition is restricted to a single word at a time. Unlike the image problem, though, if we are trying to recognize a particular speaker, then a good model might very well be an infinite sequence of words produced by a random process that models that particular speaker. There would be an advantage in long data blocks in such a case. And in that long-data-block speaker-recognition problem, we might very well want to apply nonlinear operations to the data in an attempt to estimate the basic probability structure. By that I mean moments and/or cumulants, which when taken in their entirety are sufficient to compute any desired probability density function, and are therefore a complete probabilistic description of the process.
Going Beyond the Data … Somehow
Wouldn’t it be useful if a machine could go beyond the finite data records and produce an abstract model that might involve infinities? How could that happen, though? It doesn’t seem to fit at all with the artificial neural network paradigm, in which the adjustable quantities are only the weights applied to the various nodes inside the defined (by the human user) structure.
I used to think some about evolutionary algorithms applied to sophisticated CSP-based signal-analysis systems (including front-end automatic spectral segmentation, spectral-correlation-based parameter estimation and modulation classification, and higher-order cyclic-cumulant-based estimation and classification). You could code all the many thresholds and parameter choices into a genome, and then run an evolutionary algorithm in an attempt to jointly optimize all the variables. And that’s fine, although a lot of work. What stumps me is how to make the algorithm produce something new, like a new functional block. It seems like this is the same sort of problem as the one I’m describing rather poorly in this post. How can we make the machines make a leap past the provided data?
Hi, two questions – do have a reference for using Cyclostationary Processing for timing recovery?(Synchronization) and also do you have a general book or reference you recommend? I have done a basic course which covers WSS processes but that’s all and I feel I am missing things.
Michael:
Your timing is pretty good. I’ve completed the lion’s share of a post on CSP in synchronization. Just haven’t been able to finish it up due to my day job (which is also CSP of course). A good place to start is [R7] in The Literature. I’ll contact you via email with more.
Regarding general references on CSP, first I recommend reading all the posts on the CSP Blog in chronological order. Of course I would!
But Gardner’s Signal Processing Magazine article is a good introduction:
W. A. Gardner. EXPLOITATION OF SPECTRAL REDUNDANCY IN CYCLOSTATIONARY SIGNALS. IEEE Signal Processing Magazine, Vol. 8, No. 2, pp. 14-36, 1991.
A much more detailed and mathematical introduction is contained in Gardner’s textbook [R1] in The Literature.
For advanced topics in CSP, see the work of Antonio Napolitano (for example, [R8] and [R10]).