
I’m learning, slowly because I’m stubborn and (I know it is hard to believe) optimistic, that there is no bottom. Signal processing and communications theory and practice are being steadily degraded in the world’s best (and worst of course) peer-reviewed journals.
I saw the accepted paper in the post title (The Literature [R177]) and thought this could be better than most of the machine-learning modulation-recognition papers I’ve reviewed. It takes a little more effort to properly understand and generate direct-sequence spread-spectrum (DSSS) signals, and the authors will likely focus on the practical case where the inband SNR is low. Plus there are lots of connections to CSP. But no. Let’s take a look.
The authors start off by providing context for the use of DSSS signals in terms of covert signaling, or ‘concealment,’

This is an encouraging start. When reviewing possible methods of detecting such weak DSSS signals, the authors do mention CSP (barely), but then sort of just leaving it hanging there. They admit that the papers they cite show that the CSP methods can outperform conventional methods (energy detection), but then, that’s it. Tip-toe quietly away…

OK, fine. This literature review is followed by the obligatory claims that neural networks are inherently superior, because of reasons. Check out the logic in Figures 3 and 4. Neural networks can find hidden stuff (what, exactly, hidden stuff? No one knows.) Professionals can find feature stuff. Therefore neural networks can be expected to outperform the features. Uh, why is it not possible for the professionals to find optimal features, whether or not they are hidden? Is math that broken?


Then we start to get technical. We quickly encounter the statement that the autocorrelation function for DSSS signals is periodic–see Figure 5. It is not. Except! Except in the special case in which the information symbols driving the DSSS modulator are periodic. In which case the signal is no longer ‘concealed’ in the noise, since it is periodic and therefore has only impulsive spectral components. And it is no longer a communication signal.

Moving on, in Figure 6 we find a mathematical expression for the DSSS signals considered in the work. These equations describe a rectangular-pulse DSSS BPSK (because 

 is the periodic spreading code sequence, but it is actually a function of the real time variable
is the periodic spreading code sequence, but it is actually a function of the real time variable  . The code sequence is represented by
. The code sequence is represented by 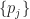 .
.Then things start to degrade. There appears the curious statement “Because the autocorrelation function of the DSSS signal is the product of the autocorrelation function of the signal code and the autocorrelation function of the pseudo-random code, it also has the correlation characteristics of the pseudo-random sequence to a certain extent.” They they go on to focus exclusively on the autocorrelation of the periodic spreading sequence or, more precisely, on the function 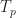
But the statement in italics above is false in at least two ways. The autocorrelation function for a DSSS signal is not the product of the autocorrelation functions of (2) and (3). We know the autocorrelation function for the binary pulse-amplitude-modulated (PAM) signal in (2) is a triangle and we know the autocorrelation function of (3) is a periodic triangular pulse train. So the product would be the product of two different triangles centered at the origin. But that is not the autocorrelation. Instead, it is equal to the effective pulse correlated with itself, since the combined signal (2)-(3) can be interpreted as a binary PAM signal with an unusual pulse made up of one period of (3). We have explicit formulas for the cyclic cumulants and cyclic polyspectra for such signals, which feature the autocorrelation and power spectrum as special cases.
The second way the italicized statement above is incorrect is more fundamental, and therefore more depressing. Recasting the statement into simpler terms: 

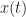

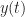
 . It is closer to the autocorrelation function of (3), but as expressed, it isn’t even a function. For example, for
. It is closer to the autocorrelation function of (3), but as expressed, it isn’t even a function. For example, for 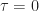 and
and 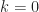 , you get
, you get  . But for
. But for  and
and 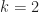 you get
you get  .
.
Interlude: The Real Deal on the Autocorrelation for DSSS Signals
Figures A-C show the estimated autocorrelation functions for noiseless simulated rectangular-pulse and SRRC-pulse DSSS BPSK signals. Of particular importance to the paper is the fact that the autocorrelation functions are negligible (theoretically zero) for values of the lag variable 

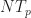
Figures D-F show the corresponding power spectrum estimates.

 .
. . The prominent peak is at
. The prominent peak is at  .
.
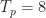 .
.


End of Interlude: Back to the Paper
The authors then present something they characterize as a ‘traditional autocorrelation-based DSSS detector,’ but which is really just a mixed-up detection scheme based on the erroneous idea that the autocorrelation for DSSS is periodic. So we see in Figures 9-10 this idea that you have to look in different


 refers to.
refers to.In Figures 11-12, we see that the authors want to truncate the autocorrelation that is used as a neural-network input so that the complexity of the inference is reduced (and training is easier too). Again we see this idea that the DSSS autocorrelation function has a peak in “the PN code period.” In reality, it has a dominant peak at 



When we get to the simulations, we see that the model (2)-(3), which is rectangular-pulse DSSS BPSK, is not actually used. Instead a more practical square-root raised-cosine DSSS BPSK signal is used (which is good!) and we now know that the value of

In Figure 14 we learn that the network is trained using a single value of the code length (equivalently, a single value for the length of the shift register), and that length is 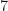
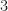

Finally, in Figure 15 we learn of an experiment involving the truncation of the autocorrelation estimate (see Figures 11-12). The authors then try to explain the appearance of the performance curves in their Figure 14, and so this is where we see the final effect of the conflation of the autocorrelations that I described above. The performance ordering is supposed to arise due to the key autocorrelation lag of 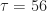
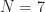
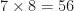

Conclusion and Update to The New Reviewing Scheme
The mathematical errors–both elementary and in probability–are egregious. So what, you may say, same as ever. But this is the IEEE Transactions. The greatest of the holies. This particular Transactions journal is just a rung (maybe two?) below Transactions on Signal Processing. How can this happen?
I don’t put much of the blame on the authors. We all make mistakes, we are all learning and trying to do something important and novel. I blame the editors and reviewers. How could the reviewers miss these key errors, errors that throw all the authors’ conclusions into serious doubt?
The reason both the authors and the reviewers miss the mathematical errors that invalidate the comparison of the methods based on the autocorrelation function, and which cast serious doubt on the signal model, is that the cult(ure) of machine learning has obscured the feedback connection between effect and cause.
I generate or obtain some data. I train my machine. I test my machine. I plot the performance. Q: Why is the performance this way? A: Shrug. That’s what the machine did. Our increasing acceptance of this mental dynamic (by me too) is what leads to the kinds of errors we see in this paper, and in many others, as I continue to document. In the present paper, we get the magical explanation of ’56’ as the reason for some performance graph’s appearance. Is that really the cause of that effect? One way to be sure is to delve into that answer–plot the autocorrelation function of the input DSSS signals. Are they periodic as stated? No. Why not? Maybe the signal model or generation is wrong–better check the literature. No. Is there at least a peak at 56? No. Why bother doing any of those checks, though, if the reviewers don’t care? Either the reviewers are true ML believers and also don’t care about the math, cause, and effect, or they are simply incompetent. Either way, it doesn’t pay the authors to get it right by performing various cross-checks. What pays is lengthy descriptions of the layers of the machine and Tables like Table I–shibboleths. That’s what the reviewers are looking for, not cause and effect, or mathematical fidelity. I think. Would like to know for sure. In any case, graduate students and researchers new to the field suffer. And everyone continues to get the impression that ML is triumphing.
Because I’d like to know for sure what reviewers are paying attention to, I add this rule to the New Rules of Reviewing I proposed in the latest correntropy debacle:
All reviews become public after a paper is published.
Let’s see what’s really going on in reviews of papers like [R177].
Post Script
Maybe I’m wrong about all this–let me know in the Comments.
I think it is important to do these kinds of reviews because obviously the assigned reviewers aren’t doing them. And one of the truly valuable things to learn in graduate school is how to take in (study) and take apart (criticize) a research paper. Really try to figure out if it is internally consistent, consistent with the literature, mathematically sound, novel, important, and comprehensible. So I hope there are graduate students out there that can benefit from seeing this kind of bare-knuckle criticism. Maybe their advisors aren’t showing them how. But if they can learn, they can go on to do their own reviews, and maybe things will get a little better. See? I am optimistic.