
Update October 2023: RFSA is a Wicked Problem.
So why do I obsess over cyclostationary signals and cyclostationary signal processing? What’s the big deal, in the end? In this post I discuss my view of the ultimate use of cyclostationary signal processing (CSP): Radio-Frequency Scene Analysis (RFSA). Eventually, I hope to create a kind of Star Trek Tricorder for RFSA.
Scene Analysis
The idea of RFSA is to use signal processing techniques to fully understand a particular radio-frequency (RF) scene. But what does “understand a scene” actually mean? I take it to mean the ability to answer all important questions about the scene, such as the number of signals that are present, their parameters, their relationships to each other (if any), the systems (standards) to which the signals may belong, and even things like the location of their transmitters and the propagation-channel effects experienced between the transmitter and the RFSA receiver(s).
The “scene analysis” in RFSA is similar to other kinds of scene analysis. For example, consider crime-scene analysis. The analyst must perform whatever tasks are needed to discover all facts that are relevant to reconstructing the crime; the whole picture must be examined and brought into focus. Crime-scene analysis isn’t just one concept or procedure, such as dusting for fingerprints or suspect identification using DNA. It comprises many tasks that develop multiple lines of evidence, and also the integration of that evidence into a coherent story of what happened and why. But many questions are not answered or even asked because they aren’t important to solving the crime, so again it is the ability to answer all important questions that permits difficult crime-scene analysis procedures to be effective.
Another kind of scene analysis is a little closer to home: auditory scene analysis. In this kind of analysis, the scene is an acoustic scene. Perhaps the scene contains multiple human speakers, ambient noise, machine noise, animal sounds, reflections, etc., and the auditory scene analyst uses one or more microphones and computing machines to automatically determine answers to important questions about the acoustic scene: How many speakers, their genders, the languages being spoken, the positions of the speakers in the room, etc. This kind of scene analysis is sometimes referred to as the cocktail-party problem or the cocktail-party effect. You enter a room filled with partying people, engaged in multiple conversations spread throughout the room, and there could be music and other non-speech sounds as well. Can you focus on a single conversation in spite of all the cochannel interference? Can you then switch your focus to another conversation? Can you just listen to the music? Many people can do these things, but it is a big challenge to automate the processes with machines.
A third kind of scene analysis is dramatic scene analysis (or, perhaps, script analysis). Here a scene from a movie or play is fully studied with the goal of holistic understanding of the scene: what are all the parts and how do they all relate and work together to achieve the writer’s goals?
RFSA: The Cocktail-Party Problem for Radios
The cocktail-party problem for radios involves RF signals instead of sound waves, and instead of human interlocutors, we’ve got multiple radio transmitters and receivers (or transceivers) operating in either the same frequency band or a set of closely spaced bands. We enter the region blindly, armed with one or more RF receivers and a whole lot of signal-processing tools. We collect data and attempt to answer the RF-versions of the original cocktail-party problem:
What are the modulation types of each transmitter?
What are the modulation parameters for each signal?
What are the directions of arrival for all signals?
What are the system types, if any, for each signal?
What are the SINRs for each signal?
What are the temporal parameters (hold times, interarrival times) for each signal?
In some versions of the problem, the information contained in the RF transmissions is also of interest, and so the individual signals must be isolated, demodulated, decoded, decrypted, etc. However, that is not part of the RFSA problem that I am attempting to solve with CSP.
Why it is a Difficult Problem
It is difficult when the scene is complicated. By analogy to the cocktail-party problem for humans, when the party is a good one, there will be many spectrally and temporally overlapping signals–it is difficult to hear anything clearly. A bad party, on the other hand, has few participants, and might consist of just a few signals, perhaps easily separable in either time or frequency. So the RF scene can be arbitrarily complicated, and that is what makes the problem so hard.
Most of the work on RF signal detection and modulation recognition that you can find in the literature (a small subset is in The Literature) focuses on simple RF scenes, such as those containing a single textbook signal in white Gaussian noise. Don’t get me wrong–those are indeed important scenes for building intuition and for attempting the construction of optimal signal-processing algorithms. And maybe there are real-world situations for which they apply quite well. Maybe.
However, when you want to do RFSA over large bandwidths, or for multiple bands scattered throughout the spectrum, you may encounter more difficult scenes, and you may find your textbook-signal-based toolbox becomes inadequate to the task. For example, consider the scene below, which is admittedly a synthetic scene, but one that does contain only captured signals:

The traditional view of this RF scene is summarized by the power spectral density (PSD), which as we know is the non-conjugate spectral correlation function (SCF) evaluated at a cycle frequency of zero. This is shown here as the rear-most slice of the upper SCF plot. I’ve also indicated, using hand-drawn dotted lines, the approximate PSDs for the individual signals. If you had only the PSD estimate, could you determine the number of signals that are present? Estimate their parameters? Probably not.
The remainder of the non-conjugate plane and the entire conjugate plane contain the SCFs for the various signals, which are largely separable because each signal possesses at least a few unique cycle frequencies–unique in the context of this particular RF scene.
So RFSA has a chance if one can analyze the RF data using CSP tools, which allow detection, sorting, and parameter estimation in the cycle-frequency domain. The difficulty is building an automated analyzer for SCF surfaces such as those above. That’s very hard, but I have hope that it can be done.
Coda 2021
The question in the minds of modern researchers is “Can we train a neural network (machine) to do RFSA?” We first have to get past the textbook modulation-recognition task, which is proving to be difficult. Despite breathless claims of vastly superior (to CSP) performance, the best-performing machines I know of do no better, and often worse than, CSP. Perhaps the more difficult challenge for the machine learners is the development of training and testing data sets suitable for RFSA. Will the machines need to see thousands of examples of each possible combination of signals? If so, we’ll be hard-pressed to ever develop a training set anywhere near sufficient. That leaves the possibility of developing neural-network-based algorithms that can accurately generalize from a few cases to many related, but significantly different, cases. Yet it is the generalization ability of the neural-network-based machines that appears to be their biggest weakness.
The dream should be largely achievable for the ‘normal’ signals. I foresee great difficulty when newer modulation techniques using overlapped carriers, and schemes which switch modulations constantly.
Can you provide any links to references on the newer modulation techniques that use overlapped carriers and/or the schemes that switch modulations constantly? Thanks for helping with the dream!
Overlapping carriers come in one of two flavours currently – VSAT, and two paired carriers. Here is Comtechs page on paired carriers (they call their flavour double talk),
http://www.comtechefdata.com/technologies/doubletalk
Similarly there are a couple of flavours of modulation switching. Two general use cases for switching are mixed modulation schemes and adaptive modulation schemes. DVB-S2 uses these in cohesion. The idea is to switch modulations according to the current SNR of the channel (to adapt to rain for example), by switching from a faster, to a more robust scheme. DVB-S2 makes allowance for this, by adding a header to each frame which is always in either BPSK or QPSK. This header carries signaling information, including the current main modulation scheme. So what you end up with is a modulation scheme which always includes a mixture of header and body (with BPSK/QPSK + something else) which can switch the body modulation type as the channel changes. The body modulation will probably not change very often (relatively speaking – can still switch once a second etc.)
You should be able to find more by searching for link adaption and adaptive (modulation) coding.
https://en.wikipedia.org/wiki/Link_adaptation.
Once all the legwork is done, do you have any thoughts on how to get the classification process automated? Some form of machine learning I assume? Trained on noiseless cases?
Good morning, Chad.
Did you use SSCA to generate the plots above? If so, What values did you use for N and N’?
Thanks,
John
Yes and no.
Yes: I apply the SSCA to the confected scene using samples at
samples at 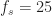 MHz and
MHz and 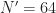 . This provides a blind estimate of all the cycle frequencies exhibited by the data. At this point, I just have a list of cycle frequencies.
. This provides a blind estimate of all the cycle frequencies exhibited by the data. At this point, I just have a list of cycle frequencies.
No: I then use the list of cycle frequencies and the FSM to create estimates of the spectral correlation function using, again, samples and an FSM smoothing with of one percent of the sampling rate, or
samples and an FSM smoothing with of one percent of the sampling rate, or 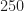 kHz.
kHz.
Finally, I call waterfall.m in MATLAB with all the obtained individual spectral correlation function magnitudes to obtain the plot.
Excellent. I appreciate the feedback. I am implementing SSCA based on your blog article and R3 & R4 from The Literature. We are working along the lines of RF scene analysis/segmentation. I’m going to try recreating your results on the DSSS article first. When I move to collected data I wanted the numbers used for the above result as a data point to calibrate my sense of ‘good’ SSCA parameters.
Very nicce post