
Let’s talk more about The Cult. No, I don’t mean She Sells Sanctuary, for which I do have considerable nostalgic fondness. I mean the Cult(ure) of Machine Learning in RF communications and signal processing. Or perhaps it is more of an epistemic bubble where there are The Things That Must Be Said and The Unmentionables in every paper and a style of research that is strictly adhered to but that, sadly, produces mostly error and promotes mostly hype. So we have shibboleths, taboos, and norms to deal with inside the bubble.
Time to get on my high horse. She’s a good horse named Ravager and she needs some exercise. So I’m going to strap on my claymore, mount Ravager, and go for a ride. Or am I merely tilting at windmills?

Let’s take a close look at another paper on machine learning for modulation recognition. It uses, uncritically, the DeepSig RML 2016 datasets. And the world and the world, the world drags me down…
The paper in question is “Modulation Recognition Using Signal Enhancement and Multi-Stage Attention Mechanism,” The Literature [R180], and the copy I have is stamped with the words:
This article has been accepted for publication in IEEE Transactions on Wireless Communications.
The Literature [R180]
So this paper passed peer review as is, but may undergo some changes (one can hope) prior to actual publication.
The paper considers three datasets: RML 2016.10a, RML 2016.10b, and their own recreation of RML 2016.10a without noise.
Shorter Version of [R180]
“Signal Enhancement” == Filtering
“Attention Mechanism” == Hand-Crafted Neural-Network Structure
Main Result == “We filtered the RML data to remove out-of-band noise and the modulation-classification results are a bit better than in the other papers.”
Review of CSP-Blog Analysis of RML 2016.10a, 2016.10b Datasets
First let’s review some CSP-Blog-generated facts about the RML datasets. All signal records in the datasets are associated with a signal-type label string, such as ‘BPSK,’ and an SNR parameter that is an even integer. The range of this integer is typically ![[-20, +18]](https://s0.wp.com/latex.php?latex=%5B-20%2C+%2B18%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
SNR and the RML-Dataset SNR Parameter
The total SNR for a sampled-data signal in noise is the ratio of the total power of the signal component to the total power of the noise component. The inband SNR is the ratio of the total power of the signal component to the power of the noise that falls within the signal’s bandwidth, for some agreed-upon definition of bandwidth. And, yeah, definitions, confusions, and sleight-of-hands regarding bandwidths are legion too.
While keeping in mind these ideas about SNR definitions, let’s review one of my videos of the PSDs for the RML 2016a dataset. Shown in Video 1 are a bunch of PSD estimates for the 16QAM signal in that dataset. When you play the video, you can see from the caption which RML SNR parameter corresponds to the plotted traces.
Let’s focus on the case of the SNR parameter of zero. Figure 1 shows the frame extracted from Video 1. What is the SNR of these signals, and how does it relate to the SNR parameter embedded in the dataset?

Let’s ignore the traces that appear to be anomalies–they show a flat PSD at about 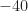
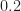
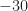

Without going through the total and inband SNR calculations, we can already see that this is not a weak signal. The noise power and the signal power are several orders of magnitude different. For any sensible SNR definition, a reported SNR value of zero should mean that the signal and noise power levels are roughly equivalent (why?), which they are clearly not. But let’s compute the values anyway, since we’re here.
To calculate the signal power, we’ll approximate the signal’s PSD as a rectangle with width

The total noise power is simply 

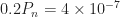

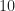

So to report the DeepSig SNR parameter as the actual SNR parameter here is highly misleading to your readers. Claiming you are doing great modulation recognition at an SNR of 
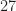
In Figure 2 I show the frame from Video 1 that corresponds to RML 2016a SNR parameter of 10, which you would naturally expect to mean that the signal is about ten times stronger than the noise. But that is very far from the truth. The average of the noise floor has changed from about 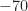
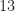


I went through this in some detail for the RML 2016b dataset in a previous post. I’ll duplicate the table of results from that post here in Table 1.
| Signal Name | Inband SNR (dB) | Total SNR (dB) |
| BPSK | 15 | 7 |
| PAM4 | 20 | 12 |
| QAM16 | 24 | 16 |
| QAM64 | 29 | 21 |
So, my people, if you report that you are killing it with the RML datasets at an SNR of
The solution to this kind of problem is, of course, analyzing your neural-network input data for yourself using your knowledge of signal processing and spectrum analysis. If you have that, that is. Do these authors’ have it? We’ll find out, but first there is one more analysis result that is important for anyone using the RML datasets.
The Case of the Missing SSB
Which is my favorite Encyclopedia Brown mystery. I’ll try to be as smart as Leroy, but don’t get your hopes up too high.
Video 2 shows 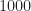
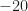

This is powerful evidence that the AM-SSB signal is absent from the dataset, and that all data records labeled AM-SSB are simply noise. But it isn’t a proof of that claim. There is at least one other possibility.
It is possible that the AM-SSB signal is present in the dataset data records, but that it has a perfectly flat spectrum, just like white noise. Since most SSB signals convey voice data, and voice data is not spectrally flat, this would mean that the SSB signal is severely undersampled, so that we see only a small fraction of the true message bandwidth in Video 2. However, the value of the plotted spectra in Video 2 never change with increasing SNR parameter. So for this ‘severely undersampled SSB’ hypothesis to be consistent with the observed data, and consistent with the same kind of verified interpretation of the SNR parameter that we have for the other signals, the power level of the SSB signal and the power level of the noise would have to be adjusted for each SNR parameter so that the total observed spectrum always has the same average level for each SNR parameter.
For this logical possibility to be true, the creators of the AM-SSB signals would have to have departed from the strategy they used for all the other signals, which is to attempt to enforce increasing SNR with increasing SNR parameter by keeping the signal power constant and decreasing the noise power (see Video 1 and the original analysis posts here and here).
So I reject this possibility on the basis of improbability. I conclude that the data records labeled AM-SSB in the RML 2016a dataset are all just noise–there is no signal component.
This means that if you train your neural network to produce the label ‘AM-SSB’ when it encounters data records like those labeled ‘AM-SSB’ in the 2016a RML dataset, you are training your network to recognize noise and label it as SSB. This is surely not a desired outcome. But it could be detected without the analysis I’ve offered on the CSP Blog by subjecting your trained neural network to independent testing datasets. That is, by always attempting generalization.
Now, the authors of [R180] apparently could have done that, to some degree, by doing a generalization experiment involving both RML 2016a and RML 2016b, which are both already considered in the paper. That is, ‘train on 2016a’ then ‘test on 2016b.’
But it turns out that such a strategy would fail in the case of SSB due to one final issue with the datasets. And that is that although the DeepSig website annotates RML 2016b with ‘including AM-SSB,’ no label containing the string ‘SSB’ is found when one unpacks the pickle file. So you’d have to create your own independent dataset with AM-SSB to attempt verification through generalization.
Signal Enhancement (AKA Filtering)
The authors claim that signal classification (SC) and signal enhancement (SE) are often used in tandem in modulation-recognition systems. I suppose this is so, although it is usually stated a bit more straightforwardly than that. I would say that before you attempt signal classification in some general setting, you often attempt to extract the signal from data that is typically wider in bandwidth than the signal. We could call that signal extraction and still have the ‘SE’ moniker.
And that’s what they mean here, really, signal enhancement is just filtering out-of-band noise from the oversampled signal prior to applying the signal classifier. Sensible! Prudent! Effective! But not particularly novel when you just call it plain old filtering. So let’s call it enhancement, fine. Hey, I’m a huge fan of filtering away out-of-band noise prior to all kinds of signal processing–that’s why I have the multi-resolution band-of-interest detector, and other people want to do that too of course. And you can enhance further! You can find the interval of time over which a signal persists and extract the signal just for that interval, which removes out-of-interval noise from the subsequent processing.
Here is how the authors try to illustrate their filtering. They look at spectrograms for several signals before and after filtering. First they just want to show the spectrograms for the SNR parameter of singing this song writing this post?
 .
. Clearly the AM-SSB signal is not like the others, and we went over exactly why in the discussion above. The most probable explanation–which also has high probability–is that all the AM-SSB signals in the 2016a dataset are simply noise. So filtering away the out-of-band noise will just give colored noise. And that brings up the question of what the [R180] authors thought the signal band was for the AM-SSB signal. You can tell the approximate signal band in the other spectrograms or in my various PSDs, but the AM-SSB PSD is always flat. So how to enhance?
But more importantly, just looking at the provided example spectrograms for the parameter of

![[-30, -15]](https://s0.wp.com/latex.php?latex=%5B-30%2C+-15%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) dB whereas the unoccupied band has values in the range
dB whereas the unoccupied band has values in the range ![[-90, -50]](https://s0.wp.com/latex.php?latex=%5B-90%2C+-50%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . This is consistent with the PSDs shown in Video 1 for the SNR parameter of .
. This is consistent with the PSDs shown in Video 1 for the SNR parameter of .This is a very very strong signal! The occupied band has spectrogram values that are typically many orders of magnitude larger than the unoccupied band. For any reasonable interpretation of the dataset SNR parameter of 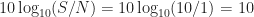
I also note that the authors’ Figure 3 (also my Figure 3 here) comes with this phrase attached: “corresponding spectrograms at 10 dB SNR.” So they really believe it, in spite of their own figure.
Things This Paper Says
Let’s look at the Introduction and find the shibboleth. Has to be something like ‘hand-crafted,’ ‘tediously manually constructed,’ or ‘careful manual feature engineering.’ Ah, yes, here it is: ‘carefully hand-crafting specialized feature extractors,’ see Figure 5. I actually see a lot of decision-theory and feature-based modulation recognition mathematics as ‘careful mathematical development of general feature extractors,’ but hey, po-TAY-toe, pah-TAH-toe I guess.

Then again in Section II.A on Related Work, we learn that feature-based recognition methods have performance that depends on the nature of the features, see Figure 6.

Also in that section on Related Work, we are directed to the authors’ reference [15] for classifiers based on ‘cyclostationary characteristics.’ The title of their [15] is “Classification of BPSK and QPSK Signals in Fading Environment using the ICA Technique,” which is The Literature [R182]. I took the liberty of accessing that paper to save you the trouble, dear reader, and rest assured it has zero to do with cyclostationarity. No mention of cyclostationary, cyclostationarity, spectral correlation, cycle frequency, or cyclic* appears in that paper. The ICA is used to estimate the short-time amplitude of some signal in noise (either BPSK or QPSK), then that amplitude parameter estimate is inserted into a traditional log-likelihood ratio test to make the decision between the two competing hypotheses of ‘BPSK Present’ and ‘QPSK Present.’
Now that the shibboleth has been uttered, and Prior Work has been erroneously described and quickly dismissed, it is time to turn to Only That Which is Worth Doing: Hand-crafting an artificial neural network. So then there is the usual obligatory Listing of the Layers, Archiving the Activations, etc.
The shibboleth of denigrating all previous mathematical modeling, decision theory, and feature defintions as sweaty icky hand-crafting of formulas is starting to make more sense as I continue my quixotic quest to document the decaying engineering literature: These people don’t like and don’t understand mathematics. Even basic mathematics. So it is to be regarded as suspicious. To wit, I show a sequence of formulas from the paper in Figures 7-10.

 for the input signal
for the input signal  and
and  for the MA-filtered version of the input.
for the MA-filtered version of the input.
 , but here is not the signal, it is some index on par with the previously used index
, but here is not the signal, it is some index on par with the previously used index  . And off we go. In (6) the authors are convolving a function of with a function of (the index , not the signal ).
. And off we go. In (6) the authors are convolving a function of with a function of (the index , not the signal ). . The function’s dummy variable is , but then we see that is defined as the radius of the filter, whatever that means. This is contradictory. In (7), is a dummy variable (could just as well have used or
. The function’s dummy variable is , but then we see that is defined as the radius of the filter, whatever that means. This is contradictory. In (7), is a dummy variable (could just as well have used or 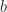 or whatever), but then the text defines as a parameter. We’ve got for the data, for the filter dummy variable, and for the Gaussian radius. Three cheers for !
or whatever), but then the text defines as a parameter. We’ve got for the data, for the filter dummy variable, and for the Gaussian radius. Three cheers for ! is now defined as the number
is now defined as the number 
Taken together, the mathematics in Figures 7-10 is American middle-school level, with American middle-school types of errors. Where, exactly, should I cram the number ‘7’ into my signal enhancer if I wanted to replicate the authors’ results?
How is it that the overloading of
What This Paper Actually Means
The key modulation-classification results obtained by the authors are shown in Figures 11 and 12.
I’m somewhat amused by Table VI in Figure 11. Which neural network (lovingly hand-crafted, each and every one, I am sure) is superior seems … random. I wonder why that is? Also amusing is the great performance across the board at classifying the AM-SSB signals (which are noise) as AM-SSB. It is actually kind of reassuring because the networks should have an easy time distinguishing the AM-SSB input from all the others–there is no signal component for any SNR parameter. But it won’t help one iota in a real application.

Figure 12 shows the authors’ Figure 12, which summarizes the performance of their proposed method along with several other neural-network approaches (the same ones as in Figure 11 [Table VI], which are those considered by the authors as state of the art).
Let’s look at the curves for RML 2016.10b in Figure 12. What this says to me is that a bunch of trained neural networks give similar average performance once the inband SNR is in excess of 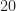
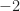

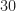
So a bunch of neural networks give some impenetrable results in Table VI for an inband SNR of something like 

Overall, the signal enhancement (filtering) provides a little boost in performance, as we might expect.
 . It is actually not quite that simple, because the relation of the DeepSig SNR parameter to the actual SNR depends on the signal-type label in the dataset (see Table 1 above).
. It is actually not quite that simple, because the relation of the DeepSig SNR parameter to the actual SNR depends on the signal-type label in the dataset (see Table 1 above).Broken Peer-Review, Pretentious Best-Paper Awards, and the Mouldering Professoriate
Here is what I’ve been leading up to. One of the authors of this paper is a professor and has been on editorial boards for IEEE Transactions journals.

I’m confident there were professors involved in the review process for this paper. The managing editor was likely a professor. Professors control the review process for nearly all journals, professors write papers with their students and put their names on the papers, professors staff the boards that control the quality and overall policies for the journals. Professors are in charge of our literature.
So professors are to blame.
If I have any (remaining!) professors in my readership, I have to ask: What are you going to do about this? What are you going to do about Professor Jang? Clancy? Zhao? Luan? Hamdaoui? Yucek? And don’t forget, that list of professors includes publishers of terrible non-machine-learning papers too. I’ve given cyclic correntropy people and CSP people rough reviews just as I have the machine learners.
I come across many more of the kinds of papers I publicly review here on the CSP Blog than I can cover. This didn’t happen nearly as much twenty years ago, and even less before that. I would have been shocked to see such sloppiness, error, and willful ignorance (“gold rush mentality”) in a Transactions paper in the 80s and 90s–and I looked at a lot of papers in those decades. So I believe the problem is worsening.
If professors can’t figure out how to author a paper that is free from basic high-school mathematics errors, and shows even minimal familiarity with the relevant literature and terminology for the chosen topic, if they can’t detect basic mathematical errors in papers they review, how can they possibly correctly choose a Best Paper Award? If they can’t reject the awful, how can they identify the excellent? So all the Best Paper puffery and mutual admiration on sites like LinkedIn is hollowed out. Just a show. Just another casualty of the fatal publish-or-perish mentality that partly drives the current ML gold rush and cult(ure).
***
Some people apparently believe that there is nothing to be done. Everything will average out in the end, and the poor-quality papers will eventually simply not be referenced and so will fade into rightful obscurity. But this ignores the substantial and ongoing harm caused by this avalanche of error. What about the current students of electrical engineering and computer science? Why consign them to wading through the dreck? They become enervated and the global progress of science and engineering slows.
If there were nothing to be done, well, then that would be that and we would have to wait until the averaging process works its magic to have the good culled from the mess. But there is something to be done right now. Stop publishing crap by putting actual effort into reviews. Consider reforming the peer-review process. Most of the good peer review is now public and happens after the publication fact has occurred, because the professors and the people they choose to review papers have failed to do their job.
I’ll leave you with some relevant words from Sabine Hossenfelder, a PhD physicist, science communicator, and public reviewer:
The most important aspect of peer review is that it assures that a published paper has been read at least by the reviewers, which otherwise wouldn’t be the case. Public peer review will never work for all papers simply because most papers would never get read. It works just fine though for papers that receive much attention, and in these cases anonymous reviewers aren’t any better than volunteer reviewers with similar scientific credentials. Consequently, public peer review, when it takes place, should be taken as least as seriously as anonymous review.
Don’t get me wrong, I don’t think that all scientific discourse should be conducted in public. Scientists need private space to develop their ideas. I even think that most of us go out with ideas way too early, because we are under too much pressure to appear productive. I would never publicly comment on a draft that was sent to me privately, or publicize opinions voiced in closed meetings. You can’t hurry thought.
However, the moment you make your paper publicly available you have to accept that it can be publicly commented on. It isn’t uncommon for researchers, even senior ones, to have stage fright upon arxiv submission for this reason. Now you’ve thrown your baby into the water and have to see whether it swims or sinks.
Sabine Hossenfelder
Don’t worry too much, almost all babies swim. That’s because most of my colleagues in theoretical physics entirely ignore papers that they think are wrong. They are convinced that in the end only truth will prevail and thus practice live-and-let-live. I used to do this too. But look at the evidence: it doesn’t work. The arxiv now is full with paid research so thin a sneeze could wipe it out. We seem to have forgotten that criticism is an integral part of science, it is essential for progress, and for cohesion. Physics leaves me wanting more every year. It is over-specialized into incredibly narrow niches, getting worse by the day.
I’m sure in her I’ll find … sanctuary.
you reviewed my paper and rejected it. and i am proud of it. you gave me very postive reviews and it helped me a lot. thank you so much.
Welcome to the CSP Blog Abdul! I appreciate your comment.
Can you check your email for a question I asked in response?
I hope your work is progressing well.