
Update: See Part 2 of this post at this link. If you want to leave on comment, leave it on Part 2. Comments closed on this Part 1 post.
Or any transform for that matter. Or the power spectrum? Autocorrelation function? Cyclic moment? Cyclic cumulant?
I ask because the Machine Learners want to do away with what they call Expert Features in multiple areas involving classification, such as modulation recognition, image classification, facial recognition, etc. The idea is to train the machine (and by machine they seem to almost always mean an artificial neural network, or just neural network for short) by applying labeled data (supervised learning) where the data is the raw data involved in the classification application area. For us, here at the CSP Blog, that means complex-valued data samples obtained through standard RF signal reception techniques. In other words, the samples that we start with in all of our CSP algorithms, such as the frequency-smoothing method, the time-smoothing method, the strip spectral correlation analyzer, the cycle detectors, the time-delay estimators, automatic spectral segmentation, etc.
This is an interesting and potentially valuable line of inquiry, even if it does lead to the superfluousness of my work and the CSP Blog itself. Oh well, gotta face reality.
So can we start with complex samples (commonly called “I-Q samples”, which is short for “inphase and quadrature samples”) corresponding to labeled examples of the involved classes (BPSK, QPSK, AM, FM, etc.) and end up with a classifier with performance that exceeds that of the best Expert Feature classifier (see my challenge to the Machine Learners on that here)? From my point of view, that means that the machine has to learn cyclic cumulants or something even better. I have a hard time imagining something better (that is just a statement about my mental limitations, not about what might exist in the world), so I shift to asking Can a Machine Learn the Cyclic Cumulant?
Let’s recall our formula for the cyclic temporal cumulant function (“cyclic cumulant”):
![\displaystyle C_x^\alpha (\boldsymbol{\tau}; n,m) = \sum_{P} \left[ (-1)^{p-1}(p-1)! \sum_{\boldsymbol{\beta}^\dagger \boldsymbol{1}=\alpha} \prod_{j=1}^p R_x^{\beta_j} (\boldsymbol{\tau}_j; n_j, m_j) \right]. \hfill (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+C_x%5E%5Calpha+%28%5Cboldsymbol%7B%5Ctau%7D%3B+n%2Cm%29+%3D+%5Csum_%7BP%7D+%5Cleft%5B+%28-1%29%5E%7Bp-1%7D%28p-1%29%21+%5Csum_%7B%5Cboldsymbol%7B%5Cbeta%7D%5E%5Cdagger+%5Cboldsymbol%7B1%7D%3D%5Calpha%7D+%5Cprod_%7Bj%3D1%7D%5Ep+R_x%5E%7B%5Cbeta_j%7D+%28%5Cboldsymbol%7B%5Ctau%7D_j%3B+n_j%2C+m_j%29+%5Cright%5D.+%5Chfill+%281%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Each of the functions 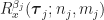

In (2), recall that 
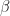
![\boldsymbol{\tau} = [\tau_1\ \ \tau_2 \ \ \ldots \tau_n]](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7B%5Ctau%7D+%3D+%5B%5Ctau_1%5C+%5C+%5Ctau_2+%5C+%5C+%5Cldots+%5Ctau_n%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

The cyclic cumulant (1) is fiendishly complex, especially for higher orders (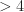


So can a Machine Learn the Cyclic Cumulant (1) as a means of classifying arbitrary QAM and PSK signals? That strikes me as a premature question, so I’m going to back off a bit more and wonder whether a machine could learn components of the cyclic cumulant. Like the cyclic moment. Even that might be too involved at this stage—it would require something like (A) creating the (nonlinear) delay product, complete with appropriate conjugated factors, (B) Fourier transformation, and (C) peak-picking with good thresholding to find the cyclic moments at the correct (useful) cycle frequencies.
OK, so how about just the Fourier transform? Can a machine learn that in an supervised learning context? That’s where all my wondering ended up. Maybe if we could train a machine to perform the Fourier transform, we could build up to having it learn the cyclic cumulants just from labeled sets of I-Q data records.
Looking around the Web for information on learning the Fourier transform, I see that the Fourier transform is used in Machine Learning, but I can’t find any work that describes trying to force (or coax? cajole? beg?) a machine to cough up the Fourier transform. So, to be clear, I want a machine that uses I-Q labeled inputs in a supervised learning setting to adjust its internal settings such that the effective function that it represents is the (discrete) Fourier transform.
We know from theoretical work that neural networks can represent many interesting and useful functions. But can we make the networks learn them?
Attempting to Learn the 64-Point Discrete Fourier Transform
I’m using the Neural Network and Machine Learning toolboxes in MATLAB (version R2017A). The basic idea is to create a rather large set of 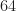
The neural network tools don’t like complex numbers, so I actually convert the input and output sequences into 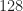
I realize a big issue in applying neural-network-based machine-learning algorithms is the selection of good hyperparameters. These entities define the structure of the machine, whose internal weights are then optimized through the training process. I accepted most of the default hyperparameters in MATLAB’s neural-network function-fitting tool (nftool), but I did vary the number of nodes in the hidden layer, and of course the output layer has to have
For hidden-layer sizes of 
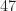
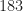
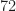


The training inputs consisted of various sine waves, rectangles, pulse trains, binary sequences, and good old-fashioned white Gaussian noise. The testing inputs had some of these as well as a few other kinds of sequences, such as ramps and sinc functions.
Here is the MSE plot for the training and the testing data sets:

And here is the corresponding normalized MSE result (each MSE is divided by the power of the associated input):

Generally speaking, the learned function has a difficult time producing low normalized MSE for both low-power and high-power signals. I believe there is an option in the training tools to use normalized MSE as the performance metric for function fitting, but I’ve not yet done that. But notice that although the normalized MSE is typically larger for the low-power inputs, it can also be large for the highest-power inputs (look at the results for Sine Waves in the Testing data). So did I manage to make a neural network learn the
The code to create the training and testing data sets and the code that MATLAB produced that supposedly corresponds to what the fitting tool did are in this zip file.
Can You do Better?
You probably can! Let me know how. Of particular interest is the generalization property of the learning. We say we have learned the Fourier transform when we know the formula for arbitrary number of samples 
For a machine to learn the Fourier transform, I think it should exhibit a high degree of generalization. If it performs well on a training set, no matter how big, and then fails for signals outside the training set, then it cannot be said to have learned. Moreover, of what use is it if the generalization is low?
The emphasis here on a high degree of generalization in a trained machine is not due to a desire to harp on a known weakness. We need generalization. In a lot of cases of professional interest to me, I use CSP to analyze data for which the contents are not known. We don’t know how many signals are present, or their types, or their parameters, or their cochannel combination properties. In some cases we find a signal with cyclostationarity properties that we’ve simply never encountered before. We are able to do this because we have highly general tools (that gets us to the never-before-seen patterns) and we have experience with lots of known signal types (that gets us to the conclusion that the obtained pattern is new).
It would be great to train a machine to do that. Primarily because one could then automate the process of analyzing new data sets which would likely speed up the process by orders of magnitude.
Hi, very interesting topic!
I have recently come across a very interesting paper which also deals with this kind of problems (https://arxiv.org/abs/1702.00832). The authors claim to achieve good classification performance using *deep* neural networks with convolutional layers.
It’s still an interesting question whether the Fourier transform alone can be learnt by a network with a single hidden layer. I will give a look at your code anyway.
Hi again,
I could achieve very good results with a few modifications of your code in training_code_for_hl_128_mse.m!
1) line 18: use ‘trainscg’ instead of ‘trainlm’. The latter uses several GBytes of RAM and it is probably the reason why your training took so long!
2) Add a line net.trainParam.epochs=10000; to allow for more training iterations, as trainscg is slower than trainlm.
3) lines 26-27: remove ‘mapminmax’. Otherwise, each sample sequence will be normalized between -1 and 1, so that the correct scaling of the Fourier transform is lost!
4) Most important, add the line net.layers{1}.transferFcn=’purelin’; before starting the training. As the Fourier transform is a linear operation, using the default nonlinear sigmoid activation function is not a good idea 😉
With those settings, I could train a network in a matter of minutes on a single i7 core. In the best case, I got a training MSE in the order of 1e-11 after about 8000 iterations. If you get much worse results, you should try relaunching the training a couple of times. I think that increasing the value of net.trainParam.max_fail might also be helpful to avoid too early stopping.
You can see an error plot on your test set here: http://imgur.com/a/rXheo.
And finally… try
figure; imagesc(net.LW{2,1}*net.IW{1})
You should get the DFT basis functions as shown here: http://imgur.com/a/hCYXa
Vito:
First, thanks very much for visiting the CSP Blog. And, I appreciate the quick and helpful feedback! This is awesome. I suspected that my ignorance of the hyperparameter choices would be an issue, and it was. I’ll try to recreate what you did according to the list above, then I’ll look for inputs that don’t work, then I’ll move on to trying to get machines to learn other components of the cyclic cumulant.
You are welcome! I am also a beginner in machine learning and I was just trying to get familiar with the Matlab toolbox in the last days, so this was an interesting exercise with the right timing.
By the way, I have just realized that you had already extensively commented in a previous post on the paper which I mentioned in the first comment.
Chad, thanks for a great article. As we see panning out here, fourier transform being a completely linear transform, is hurt a lot by the nonlinearity present within the layers. That compresses the dynamic range and leads to non-generalization as you saw. As an example, I can train an N weights LMS to give me one output of the fourier transform, perfectly. We know that from linear adaptive filter theory. So essentially, for a neural network, I would have N different LMSs each being trained through simple stoachastic gradient to converge to the NxN fourier matrix.
The following question is : then what are these nonlinear activations doing in the neural net and can they serve useful functions in machine learning a more nonlinear metric like the hypothesized higher order cyclostationary ones ? We do understand that nonlinear functions exist to create a composite class for points that are not colocated on the feature map. (the XOR gate example). In other words, they create basis functions for arbitrary partitions of input space, so that points residing in any union of input subspace can be combined to create a composite class. Will these nonlinear activations serve us in the cyclostationary case ? I have a feeling, they potentially could. We do know that cyclostationary metric has a lot of nonlinearity baked into it. But that nonlinearity also has a lot of structure coming into it, based on which time indices etc are selected. All this potentially means a very sparse casual linkage to input time samples. Will a network be able to whittle away at the links until it has this sparse nonlinear transform of the input…. is a very interesting question 🙂 . I am keeping my fingers crossed excitedly here for your findings Chad. Thanks again.
Thanks for the great comment Umer. As I progress from the Fourier transform all the way to the cyclic cumulant, it looks like the machine will have to learn the equivalent of nonlinear operations followed by Fourier transforms, and possibly multiple stages of these.
However, one step at a time for this Machine-Learning neophyte. Next up: Can a Machine Learn a PSD Estimate? Our main estimators employ a Fourier transform followed by a nonlinearity followed by a linear operation such as convolution!
Has there been progress on this? I’ve been wondering about this myself. The Fourier transform and cyclic transforms are operators. Does the Universal Approximation Theorem apply? If a NN can learn a transform, I’m curious as to whether the performance would degrade gracefully if you train on a smaller number of nodes, or would it completely fall apart below some threshold? If it’s a slow degradation, you might be able to come up with a good-enough FFT approximation that has computational performance better than an FFT and yet adequate for classification. You might even merge the FFT network and classification network for further computational reductions.
No progress on this lately; I’ve been distracted by my day job. I do believe the UAT applies.
The “learned” FFT is accurate for the signals I input to it, and provided they have amplitudes that are within the amplitude range used in training. I was planning to move next to the PSD or spectrogram, but haven’t attempted it yet.
Hi Chad, very interesting post!
I’m wondering if the same network architecture can be used to learn the 2D Fourier transform, in the sense that we can try to use a fully-connected layer made of 64 nodes to learn the 2D DFT of 2D arrays of size 8 by 8.
Have you considered this case? what do you think would be its implications on the generation of the training set? How about the network architecture? Would a CNN be more relevant?
Hey Mido, thanks for the intriguing comment. At first, I thought, sure that should work no problem. But then as I was thinking about how I’d convert each 8×8 input to a 64-element vector, I was wondering if the problem was still linear. Fortunately, I can easily try this out with the code I developed for the original post. Just gotta find the time! To answer you directly, no, I hadn’t considered this case. But I should have, because it seems more in line with image processing, which is where much of the machine learning stuff has and is happening. (Right?)
Is this what you’re trying to do? DFT outputs are just linear combinations of the inputs, so you only need a single layer with no activation function: https://gist.github.com/endolith/98863221204541bf017b6cae71cb0a89
Thanks for your interest! Did you read Part 2 of that post? The link is in the first sentence of the post. Here it is for convenience: http://cyclostationary.blog/2018/02/27/can-a-machine-learn-the-fourier-transform-redux-plus-relevant-comments-on-a-machine-learning-paper-by-m-kulin-et-al. I’ve closed comments on the post, so if you want to continue to comment, just go to Part 2.