
During my poking around on arxiv.org the other day (Grrrrr…), I came across some postings by O’Shea et al I’d not seen before, including The Literature [R176]: “Wideband Signal Localization and Spectral Segmentation.”
Huh, I thought, they are probably trying to train a neural network to do automatic spectral segmentation that is superior to my published algorithm (My Papers [32]). Yeah, no. I mean yes to a machine, no to nods to me. Let’s take a look.
The problem as described is straightforward: find the time and frequency edges of a modulated RF signal. This problem is analogous to image segmentation, and when a spectrogram is used to develop a solution, the analogy can be very strong indeed–image processing is directly relevant. When we are using a relatively short data sequence to perform the task, the appeal of a spectrogram is lessened, but the analogy to image segmentation is still strong. For this reason I describe my algorithm as an automatic spectral segmentation algorithm, although it also performs the dual operation of temporal segmentation.
Often the obtained segments in frequency, which are just frequency intervals, are called bands of interest (BOIs), and the obtained segments in time, which are just time intervals, are called intervals of interest (IOIs). But terminology varies.
My paper on BOI estimation was published in 2007 and the corresponding CSP Blog post in 2017. Neither are mentioned in The Literature [R176], although the algorithm is directly relevant. When I developed the algorithm, I had looked quite hard for related work–what did others do about the general problem of RF-signal localization in time and frequency? I found several relevant papers and these are cited in My Papers [32]. But they didn’t do what I wanted, so I invented an alternate approach that provided the kind of BOI and IOI estimation that was maximally useful in the context of CSP. Most notably, typical BOI-estimation approaches use a fixed spectral resolution (including [R176]), but this is highly problematic when doing general-purpose RF scene analysis because you might have a wideband scene that contains, simultaneously, multiple closely spaced narrowband signals and several spectrally isolated wideband signals. A large spectral resolution forces a low-variance high-bias spectrum estimate, which favors the isolated wideband signals, but lumps the closely spaced narrowband signals together. What is needed is a data-adaptive multi-resolution approach, and that is what is in My Papers [32] and the CSP Blog post.
When West et al started thinking about spectral segmentation, I wonder if they looked around for algorithms that might either do the job or that would be fair to compare theirs with. How hard is it to find my paper and my CSP Blog post? Not hard at all.
Google Searches for Key Words Are Easy and Effective
Since the term ‘spectral segmentation’ appears in the title of [R176], it is natural for the authors to perform literature searches using that term (and also other terms of course). When one uses Google to search for “spectral segmentation,” the first ten or so returned links all relate to image processing (image segmentation). The first non-image-processing link is the CSP Blog post on spectral segmentation, as shown in Figure 1. The reference to the published paper My Papers [32] is easily found in that post, as well as a mathematical description of the algorithm from [32] and lots of performance examples.

If one searches for “automatic spectral segmentation,” the first result is the CSP Blog post.
In the cognitive radio literature, the idea of segmenting a spectral band into subbands that are occupied (‘black spaces’) and those that are not occupied (‘white spaces’) is central to research and practice. The goal is reliable white-space detection, because if you find a truly unoccupied subband, your cognitive radio can transmit in that band. Finding white spaces is the complementary problem to finding black spaces, and finding black spaces is spectral segmentation as defined by West et al. So searching the cognitive radio literature for spectrum-sensing and white-space detection algorithms, implementations, and performance analyses is a necessary element of finding relevant related work.
A Google search for “white space detection” brings up My Papers [32] as the second link, as shown in Figure 2.

Yes, it is the Same Problem
Just to make sure that you realize the problem under study by West et al is the same as the problem in My Papers [32] and the automatic spectral segmentation post, here are some excerpts from the paper describing the problem.


West et al appear happy to make the assumptions about the nature of signal localization (spectral/temporal segmentation) that I explicitly reject in My Papers [32]: Fixed spectral and temporal resolution (see Figure 5).

The problems with fixed spectral resolution are that (1) the spectral edges of a signal are difficult to estimate with accuracy better than approximately the chosen spectral resolution 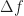

Moreover, the algorithm is easily extended to handle the very common situation in which the RF scene data is obtained from a radio receiver with significant filter-rolloff shoulders on either side of the spectrum, as illustrated with a captured FM-broadcast scene in Figure 7.

Phantom Dataset
The paper The Literature [R176] mentions the possibility of a publicly available dataset related to the authors’ work on spectral segmentation. See Figure 8. However, I have tried to access this address multiple times over weeks, and it does not exist. See Figures 9 and 10.



Weirdness I Can’t Let Go Without Comment
While reading through [R176], I came across a figure intended to situate various signal-processing and machine-learning approaches to ‘spectrum sensing.’ I reproduce it here as Figure 11.

While staring at Figure 11, I figured I knew what “Cyclostationary” was (even though ‘cyclostationary’ is just an adjective), and that I knew what “Match Filtering” was (matched filtering), and I’m pretty sure I know “Energy Detector.” Data-derived ML sensing methods are the focus of the current gold rush in signal processing, but what are “Waveform-based Sensing” and “Radio Identification?”
So I did a Google search to search for related work. What I found, quickly, was a paper I’d skimmed in the past by Yucek and Arslan (The Literature [R178]). Figure 4 from that paper, which is referenced in [R176], but not in the context of Figure 1 from [R176], is reproduced here in Figure 12.

Figure 1 in [R176] is accompanied by the text “Figure 1 shows a trade space of these approaches with our perception of accuracy and complexity.” (Emphasis added.)
Helpfully, Yucek and Arslan define what they mean by the terms in the ovals ([R176] does not.)
Waveform-based Sensing is matched filtering, where the filter is matched to a segment of a transmitted radio signal that is knowable, such as a preamble or midamble in a framed signal (e.g., GSM), or a periodically repeated synchronization sequence (e.g., ATSC-DTV). Match filtering is matched filtering, where it looks like the authors enforce the idea that the entire waveform is known (remarkably unrealistic and inapplicable except in radar, where it is called pulse compression). Matched filtering is impossible to apply when one does not have a repeated known segment of the waveform to work with, and is highly vulnerable to synchronization problems such as a residual carrier offset frequency (as the authors in [R178] allude to) as well as to interference. But, clearly, Waveform-based Sensing and Match Filtering should have overlapping, if not identical, ovals in the figure.
Radio Identification is feature-based processing of various ad hoc sorts (not a criticism). The authors spend most of their time talking about energy detection and CSP in the Radio Identification context, so it clearly cannot have an oval that does not substantially overlap those for Energy Detector and Cyclostationary.
These kinds of figures are very difficult to construct. One of the reasons is that one wishes to use simple labels, but simple labels such as Cyclostationary encompass a wide range of algorithms with a huge variation in computational cost and applicability, not to mention accuracy. That is, the problem of spectrum sensing (or modulation classification, modulation recognition, automatic signal classification, RF scene analysis, etc.) is a highly multidimensional problem. Reducing it to two dimensions risks extremely misleading characterizations. And that is what we see in [R178], which makes its way into [R176] unchanged except with an addition that claims ML methods blow everything else out of the water. We know that isn’t true, but it is taking researchers from outside the gold rush to document it.
Nevertheless, I’ll persist and offer a diagram of my own in Figure 13. I’m ignoring Radio Identification and Waveform-based Sensing, because those things, apparently, are pretty much special cases of some of the other, more general, bubbles.
Where is machine-learning in Figure 13? Hard to say, because the cost and performance for a Data-Derived ML Sensing Model depends on the nature of the training dataset as well as the neural-network structure and parameters. The Multiple-Signal Cyclic Cumulant Analyzer is applicable to any problem involving any combination of cyclostationary signals in any noise. It may be very hard to construct it so that it actually works for literally any such combination of signals, but that is its inherent nature. The nature of a trained neural network depends heavily on the training dataset–there is no general technique. If your training set consists of examples of two cochannel signals, then there is a chance the network can recognize inputs consisting of two cochannel signals. But it will fail when there is a single signal present, because there is no correct label to choose from. Etc.

There are three basic lessons from Figure 13. First, CSP is generally expensive. Second, blind algorithms are usually more expensive than non-blind algorithms. This is because the blind methods incorporate one or more searches. Third, there aren’t many options when you need to deal with cochannel signals. I’m sure there are contradictions or errors in the arrangement of the bubbles in Figure 13–like I said, drawing these figures is hard.
There are other bad statements in [R178], but one thing that stands out is Figure 3, reproduced here as Figure 14.

The definitions of the probability of detection, 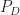
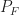
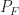

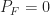
In my post on the cycle detectors, I show both histograms of detection statistics and receiver operating characteristics. Some of the former are reproduced here in Figure 15. Of particular relevance to Yucek [R178] are the optimal energy detector (OED) histograms shown in red. The corresponding receiver operating characteristics are shown in Figure 16 (along with some other detectors). These are typical shapes of receiver operating characteristics. They start at the origin 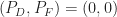
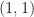
The Yucek characteristics don’t conform to these basic probability results.

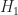 means the signal is present,
means the signal is present,  means the signal is absent). The energy detector corresponds to the red curves. Note that the distribution of the detection statistic on is to the right of that for . This is the case for all energy detectors, and all other detectors I know of. It is logically possible to have a good detector for which the statistic is reliably smaller on than on , but it doesn’t happen in practice.
means the signal is absent). The energy detector corresponds to the red curves. Note that the distribution of the detection statistic on is to the right of that for . This is the case for all energy detectors, and all other detectors I know of. It is logically possible to have a good detector for which the statistic is reliably smaller on than on , but it doesn’t happen in practice.
Comments and corrections are welcome below.
Looks like for [R176] “Wideband Signal Localization with Spectral Segmentation” at there is a comment stating “arXiv admin note: substantial text overlap with arXiv:2110.00518”. The title to the similar arXiv entry is “A Wideband Signal Recognition Dataset” which seems to have been submitted/accepted to 2021 IEEE 22nd International Workshop on Signal Processing Advances in Wireless Communications (SPAWC)
https://ieeexplore.ieee.org/document/9593265.
Anyways, in the SPAWC version of this paper, they first claim their dataset is located here:
https://opendata.deepsig.io/datasets/SPAWC.2021/spawc21_wideband_dataset.zip
This link for their dataset also does not appear to work. However, later in the same paper, they state the dataset is located here:
https://eval.ai/web/challenges/challenge-page/1057/overview
This link does appear to be valid, but ultimately points to reader to this link:
https://github.com/gnuradio/sigmf
(which also seems to be valid).
I have not yet tried to figure out how to most appropriately download the dataset (or if the signal dataset indeed exists in the github repository). If someone beats me to it, feel free to report if you got anywhere.
Cheers!
Thank you John! Your comment will probably help more people, and help them more thoroughly, than my entire post.
Well, I wouldn’t have thought to look for this without your post, Chad, so thank you for the post!
But alas, it turns out the sigmf link https://github.com/gnuradio/sigmf simply provides the details for how they formatted the dataset (which is nice) but does not actually contain the dataset. The second link in their paper https://eval.ai/web/challenges/challenge-page/1057/overview ultimately has a circular link back to the first link in their paper https://opendata.deepsig.io/datasets/SPAWC.2021/spawc21_wideband_dataset.zip which doesn’t work.
¯\_(ツ)_/¯
If anyone is able to obtain the dataset, feel free to let us know.
Hi there,
I recently read the paper by West et al., and while looking into cyclostationary methods ended up here at your blog, so this is a very nice little coincidence for me 🙂
What do you think of the reference in the West’s paper by Mathys that was presented at GrCon? I had the chance to check the complementary python notebook implementation too and it seemed like a simple and smart approach to me.
Thanks for the great blog btw, already read bunch of other posts!
Thanks for reading the CSP Blog, Temir, and the compliment! I appreciate it.
I hadn’t seen that GrCon paper by Mathys before. It is now in The Literature at item [R179] (where there is a URL to the paper).
I was also on a team that participated in DARPA’s Spectrum Collaboration Challenge a few years back. I remember the first hurdle that forms the topic of [R179]. We also passed that hurdle.
I think Mathys’ paper reads like someone who is comfortable with the mechanics of digital signal processing, and has some signals knowledge, but who has scrupulously avoided learning statistical signal processing as applied to RF signals and systems.
Overall, I would say that Mathys’ paper does not address in any meaningful way the general problem of spectral segmentation (AKA band-of-interest estimation). It is a set of tools and a procedure for handling quite a specific and not particularly difficult scenario.
All of the signals considered in the paper are second-order cyclostationary signals except the analog FM signal, which typically has no significant non-zero non-conjugate cycle frequencies, no significant conjugate cycle frequencies, and has a constant modulus. MSK and GMSK also have constant moduli, but they are (contrary to what you might conclude from the paper) strongly cyclostationary of order two.
Some paths to successful processing are foreclosed by the odd use of time-domain squaring as the ‘conventional method’ of symbol-rate estimation. Yes, squaring a signal (or magnitude-squaring) can produce spectral lines, and the frequencies of those lines are the cycle frequencies. But professors were teaching that before the 80s. A lot of stuff has been published in the intervening decades. In particular the spectral correlation and coherence functions are extremely useful for symbol-rate and carrier-estimation for many signals, including BPSK, GMSK, and MSK.
It is quite easy to match the parameters of the paper and pass 30,000 samples of a six-signal composite scene with approximately 10-dB SNR for each signal through an estimator like the SSCA or FAM. In doing so, a very small number of cycle frequency estimates appear at the output, and all are simply related to the modulation parameters that Mathys seeks. Here is an example:
Here the blindly estimated CFs are used in the FSM to compute the full SCF over frequency f. The signals are, from negative frequency to positive, BPSK (250 kHz), QPSK (300 kHz), GMSK (187.5 kHz), 16QAM (272.7 kHz), MSK (166.7 kHz), and FM.
A typical pair of outputs for the non-conjugate and conjugate SCF and coherence functions are:
Non-Conjugate:

Conjugate:

Those are frequency, cycle frequency, spectral correlation, and spectral coherence values. They are all that remains after all the processing is applied to the SCF and coherence surfaces.
These estimates and plots are formed by applying the CSP stuff directly to the entire band–no spectral segmentation is used!
However, in general, spectral segmentation is quite useful because when you begin applying the time-domain cyclic cumulants to the blindly discovered second-order cycle frequencies in order to perform multiple-signal modulation classification, it is desirable to work with as few samples as possible, so operating on each extracted subband at its Nyquist rate generally reduces computational cost.
Notice that you can find the symbol rates for the constant-envelope (constant-modulus) MSK and GMSK signals by examining the cycle frequencies for the pairs of strong conjugate features produced by these two signals. Also note that the MSK signal has a detected non-conjugate feature. These facts are NOT at odds with Mathys claim that constant-envelope signals can’t produce a symbol-rate feature by squaring. This is the difference between ‘understanding and using the statistics of communication signals’ and ‘applying some tricks I heard about.’ See this post for hints.
Hi Chad,
First of all thanks for the very detailed reply. I will need some time to digest your answer and the link you shared but it is very much appreciated.
I share your feeling regarding “tricks”. I am an electrical engineer by training who did post-graduate work on nonlinear filtering (particle filters etc.) and have a fairly decent understanding of signal processing. I have recently started working on an SDR related project. I am trying to catch up with digital communications and SDR work but what I noticed is that there are so many tricks and trade secrets! Hopefully your blog will complete some of the gaps in my knowledge.
I am mainly working on time-delay estimation right now and was looking into what to do when there are multiple emitters. (both for the case when there are spectrally separate sources as well as multiple emitters sharing the same spectrum and modulation scheme) I was considering some combo of energy/pulse detection and channelization to separate sources and that is how I ended up reading the paper by West and Mathys and also discovered your blog. I read your post titled “CSP-Based Time-Difference-of-Arrival Estimation”. If you can point me towards some definitive reference for such multiple emitter time-delay scenarios I would be very grateful.
Best regards,
Temir
I see that you had some work published with Gardner back in the 90s, should probably check them out!