
Let’s switch things up a bit here at the CSP Blog by presenting an interview on a technical topic. I interview two characters you might recall from the post on the Domain Expertise Trap: Engineers Dan Peritum and Eunice Akamai.

With the splashy entrance of large-language models like ChatGPT into everyday life and into virtually all aspects of science, engineering, and education, we all want to know how our jobs and careers could be affected by widespread use of artificial intelligence constructs like ChatGPT, Dall-E, and Midjourney. In this interview with a couple of my favorite engineers, I get a feel for how non-AI researchers and developers think about the coming changes, and of course how they view the hype, distortions, and fabrications surrounding predictions of those changes. You can find photos of the interviewees and brief biographies at the end of the post.
The interview transcript is carefully contrived lightly edited for believability clarity.
CS: Welcome to the CSP Blog interview Dan and Eunice! I’m thankful you said yes to my invitation to talk with me about the future of signal processing, and whether or not signal processors (the humans not the machines) are needed any longer now that we have ChatGPT and the like.
EA: Thanks for having us Chad! Nice to be with you, even if virtually. I hope we can shed some light on the topic.
DP: Yes, thanks Chad. Great to be here. You know Eunice and I like to talk about engineering, science, and of course signal processing. We’re ready to go!
CS: Well, I want to talk about the future of human signal processors, and in particular about the likelihood of AI constructs taking over our jobs and relegating us to, I don’t know, IT or something. But first I want to see how AI, things like ChatGPT and Dall-E, are being used by you and people in your labs. After all, if it doesn’t help us now, maybe we’re in good shape for some time to come. So, do you use AI in your engineering or engineering management work?
EA: I don’t, not much anyway. I have tried a couple times to use ChatGPT to sort of get me started on some new signal-processing algorithm, but the answers I get back are so simplistic most of the time, and, uh, I guess some of the time they have errors that I have to find and try to correct. So in the end I just walk away from the thing shaking my head. Let me give you an example. I was trying to do some signal-separation work and so I tried to short-cut use of the internet, libraries, pencil-and-paper, white-boarding, etc., so I asked ChatGPT to come up with an algorithm for separating two signals in noise. It went something like this:

EA: ChatGPT came back with this first response:

DP: Wait, Eunice didn’t you tell ChatGPT that the signals were cochannel? Maybe it just doesn’t know that word?
EA: Well that would be surprising and very bad for OpenAI. They boast about the massive training. Also, if ChatGPT doesn’t know a word (like maybe somebody just horribly misspells something) shouldn’t it just say so?
CS: Agreed. But here ChatGPT just seems to ignore key elements of your request–the correlation between most of your words and this response was just too high for it to ignore. I guess. Maybe. Possibly. Who knows?
EA: So, yeah, this kind of response is actually a way to train the humans to become what is now known as a prompt engineer.
CS: I was looking around the web for the accepted requirements for becoming a prompt engineer. I don’t think you need a college degree in engineering, but a BS in computer science, data science, programming, etc. would be helpful. So it appears to be one of those cases where a high-status word is borrowed from one domain to bolster the look in another–in this case ‘engineering.’
DP: Like ‘political science’ I guess. Or the classic ‘sanitation engineer.’
EA: Yeah. But it’s minor.
CS: Sure, minor. And irritating.
EA: So, of course, the weird ChatGPT prompt response prompts in me the desire to provide a refined prompt back to ChatGPT, kind of like talking to a small child. And so I am being trained. I promptly came back with

and ChatGPT cheerfully (as always) replied with

But the independent component analysis (ICA) method of signal separation requires that you have multiple receivers (typically microphones in the common audio-signal processing application). And I recall that I specifically tried to head this off by stating in the original prompt “I have only one data record.” So that’s two things that ChatGPT completely ignored–it is overwhelmed by spurious correlations I guess.
DP: I’m thinking that you next refined the prompt. ChatGPT is sculpting you into a prompt engineer for sure. I’m starting to get worried about you Eunice.
EA: Me too. But, yeah, of course I couldn’t let it go. Here is my next prompt:

and I got this response back:

CS: Well, that’s news to me! I hadn’t come across this non-negative matrix stuff before.
EA: Yes, me either, and for good reason. It doesn’t apply.
DP: It seems like ChatGPT is sort of chasing its tail. This is kind of a new phenomenon: a correlation-seeking treadmill or mobius strip. I’m starting to think that you can refine your prompts forever, Eunice, and not really get any closer to a solution. I mean, why doesn’t ChatGPT just bring up FRESH filtering? Isn’t that what you intended in the first place?
EA: Yes, that is an appropriate solution. I suppose ChatGPT just doesn’t know about it yet, or the correlation between the prompts and what it does know is too low. Not enough FRESH-filtering mentions or descriptions in the training corpus? Anyway, I did continue a little longer:



and so like Dan said, we’re moving in circles. Circling the drain? I dunno.
CS: Thanks Eunice. I’m wondering how common that experience is. I think a lot of such experiences don’t bubble up to the top of someone’s Google feed or get written up, breathlessly, on some technophile’s blog. They just get forgotten. Let’s turn to Dan. What do you think Dan?
DP: Yeah, I have had similar experiences. Just a lot of useless responses that show that the system does not understand the question and has a highly limited–with respect to nominally competent humans–view of what a solution should look like. A lot of times a solution to some posed problem is just a wrapper around a function or process that mysteriously encapsulates the solution. Like, I ask for a solution to the problem of framistaning a thingamajig and I get back some code that sets up, eventually, a call to some function called framistan_the_thingamajig(). Helpful, and right on the money!
But my biggest problem with the LLMs like ChatGPT is that they claim to be able to do things that require separating truth from falsity, but they can’t actually do that. At all. Like debugging. Debugging some signal-processing or mathematical-analysis code. Even super simple stuff seems well beyond the debugging capabilities of the LLMs–I’m not sure why people even mention this as a possible use. For example, I took some of the code available on the CSP Blog … and there’s not much …
CS: Yeah, that’s my approach–the CSP Blog is mostly self-help with an assist from me …
DP: … because I thought that would be an easy example for your readers to follow, and of course relevant to their work, and I just changed a single thing in a working function. Then I asked ChatGPT to debug the code. I’m not talking about a serious CSP or SP bug in a complex software system! Just a very simple function with a very simple error. Simple for expert humans to spot, anyway.
EA: You just wanted to see what the debugging workflow, sort of, of ChatGPT was?
DP: Yeah, that’s a good way to put it Eunice. Workflow. What is the workflow here for debugging signal-processing code and, of course, can the system find the bugs and not also raise a bunch of false-alarms about code that actually is fine … that, I mean, that doesn’t have bugs.
CS: OK, so what happened? What code did you pluck from the CSP Blog?
DP: I took your convolution code from the Signal Processing ToolKit post on convolution and created a simplified version that just does the ‘convolve a unit-height rectangle with itself’ part. It sets up the rectangle, calls conv.m, and plots the result. To introduce a bug, I replaced the second argument in the call to conv.m with a time-reversed version of the rectangle. Actually, this produces the correct result! The time-reversed rectangle is equal to itself. But it should be flagged as a bug. Later I introduced an even more obvious and still-simpler bug. Here is how the ChatGPT session started:

So far, so good. I then provided the code:



The response I got to this very simple debugging task was this:

The final line of the supplied code is a return statement, which does terminate the execution, but there are no further lines after that return statement, so all should be well! Moreover, most of the supplied code is the plotting section, but ChatGPT thinks the entire plotting section is missing. So it fails completely to parse or analyze the provided code. But, OK, I just modified the original submission by multiplying the second argument to conv.m by two:

and resubmitted (reprompted, a new word). Didn’t do nothing about the supposedly missing plotting section and of course I kept the return statement in place. I got this response:

So ChatGPT identifies the call to conv.m as correct, when in fact that is the only line of code that is incorrect! Chad, Eunice, it’s stuff like this that tells me we still need human signal processors and coders, and will for a long time yet.
CS: Right, because ChatGPT isn’t really parsing or analyzing anything here, it is just trying to give you a high-probability response based on a bunch of things it has seen during training.
EA: Well, presumably it has seen MATLAB code during training, we just don’t know. We do know that it is very happy to tell you it can debug your code, but we don’t know how many pairs of {wrong code, right code} it has seen in that training corpus.
DP: Yeah, I mean I’ve heard it described as a giant auto-complete system. It takes our familiar word-level auto-complete function and raises it to a paragraph-level or essay-level auto-complete. But we know that auto-complete is not a proper model for doing things like debugging code! We don’t want to get suggestions on what is similar to what we’ve done, we want to find a flaw or falsehood and replace it with correct code or truth. What is true about an auto-complete? Maybe you like the provided completion, maybe you don’t, but there isn’t any truth value to it.
CS: I have my own example to share. One of the things ChatGPT says it can do is something called ‘code completion.’ I guess if you’re writing some code to do something–in our case a signal-processing something–and you get stuck and don’t finish the job, you can provide the incomplete code and ChatGPT will finish it (‘complete it’) for you, providing code snippets and ‘even entire functions.’ Well, we all get stuck, don’t we?
DP: Yes!
EA: For sure.
CS: Of course I’m suspicious that ChatGPT can only complete simple codes like a quadratic-equation implementation or take-an-FFT-and-plot-the-magnitude kind of thing, but let’s see. A lot of CSP Blog readers have trouble implementing the time-smoothing method of spectral correlation estimation, so let’s see if ChatGPT can complete it if I just leave off the final steps and place good comments there for the nature of the missing functions or code.
EA: But why would we think that ChatGPT is good enough for that level of sophistication in signal-processing coding?
CS: I guess because it boasts about it? Here is something it likes to say:

CS: OK? So let’s see what happens with the TSM. I have a 262-line MATLAB implementation that is generously commented and computes the spectral correlation and the coherence. I removed the final steps and replaced them with comments that just said: “Missing code”:

CS: And just for context, here is the form of the function call, seen at the top of the file that implements the function, which I provided to ChatGPT:

CS: So basically I tell ChatGPT what to do in each comment. Here is what I got back:

EA: It looks like it got the frequency vector right!
DP: Yay! And If S_T is the spectral correlation estimate, then it assigned the output variable scf correctly! And coh = coh! Of course it does!
CS: But that’s where the correctness ends, I’m afraid. P_T is indeed the power spectrum estimate, but the coherence, recall, requires that the spectral correlation is normalized by the geometric mean of the PSD values at 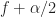

So to summarize our conversation on using ChatGPT in our everyday signal-processing work, we don’t because we can’t because it ain’t any good. The apparent silver lining (for OpenAI) is that the more you try, though, the more ChatGPT trains you, taking you from a knowledgeable mathematically inclined signal-processing engineer to a master questioner (prompt engineer). You’ll get better and better at providing more and more prompts. It is, however, unclear if you’ll ever actually get to a useful result, but for sure you interact with the system for longer and longer periods of time. Kinda like how social media platforms nudge you and guide you to ‘high engagement’ items, steadily prolonging your visits to the apps. Hmmm…
CS: Alright, let’s move to a new topic. In the past few decades we’ve seen several high-profile biologically inspired algorithms for system optimization go through hype-and-trash kind of cycles: evolutionary algorithms, simulated annealing, genetic algorithms, various kinds of neural networks for inference-making, and now large-language models. These are just tools, and we can use them if they fit the job at hand. What kind of job or task in your professional life might be better done, or more easily done, by using a large-language model? We’ve covered a couple cases where ChatGPT didn’t work out in a design or debug setting, but are there other settings that you can at least envision a large-language model helping?
DP: ChatGPT is a language model. It accepts text prompts and provides text responses. So I think there is a possible role for ChatGPT and the like for technical writing. Things like monthly reports, technical reports, presentation outlines, maybe even the simpler emails. Maybe it could, eventually, provide useful starting points for such things in our domain.
EA: But what I struggle with is that all those writing tasks are usually highly specific. You don’t just write a generic report for your client or customer: “Dear Human Source of Funding: We have made substantial technical progress. We have encountered non-serious technical problems and have identified potential solutions. Sincerely, Human Sinks of Funding.” Doesn’t cut it. Engineering work is always detail-oriented.
CS: Well, what does ChatGPT say? I asked it about helping me with ‘engineering reports’ and this is what I got back:

Would it be any faster to try to supply ChatGPT with all those things it asks for rather than just write the report from the start? I mean, are we going to get back on the mobius strip of doom? Do we need a Certified Prompt Engineer ™ to have ChatGPT create a one-page report? Of course, like Eunice, I’m being trained too:




DP: How is that any different than finding a website that quickly explains the elements of a report? Gotta be a million of those around.
CS: Yes, how is ChatGPT’s assistance here better than, say, ProjectManager.com?
EA: In all honesty, Chad, I’m thinking the answer is: AI is modern, Project Managers are not. What do they call the cognitive bias toward the new over the old regardless of the actual quality or benefits involved?
DP: I think the MIT people call it ‘new-technology bias,’ a positive-toward-new-tech bias that comes from being, for example, awe-struck over some new machine or viewing computer-program outputs are wondrous, mysterious, and ineffable.
CS: OK, let’s now move to discussing some ideas of critics and promoters. One way to look at the latest generative AI tools is as the latest in a long line of technologies that yes, disrupt, but also that will simply end up being used by humans and integrated into artistic, scientific, political, and mundane efforts just as they always do. Here’s Michael Woudenberg
Many on the thread totally understood the power that these new tools [Midjourney, ChatGPT, Dall-E] provide to the aspiring artist. Painters were panicked about photography as Mark Palmer so well points out in The Joy of Generative AI Cocreation. In the 1990s photographers then panicked about digital film and then cell phone cameras. Today millions of people can take photos that were limited to only professionals with expensive equipment. Yet there are not fewer photographers or less art. There’s more!
Woudenberg on the Polymathic Being Substack
So the idea is let’s not fear the disruption of this new tool, let’s just figure out how to use it. It won’t take over, any more than cameras, movie cameras, cell phone cameras have taken over. We are still in control; we are still the artists; we still ‘do the work.’ The tools change over time, we do not.
DP: I get the idea. It reminds me of some of the educational technology that appeared over the years in science and engineering. Suddenly all engineering students had powerful programmable calculators swinging from their belt loops in the 80s, then personal computers, routine access to campus mainframes, wikipedia, e-books, online courses, etc. Professors adapted and good solid engineers are still created by the universities of America.
EA: But there is this siren song telling me ‘This time it’s different. This time things are really going to change, and not for the better.” And what seems different is that the amount of effort on the part of the artist, scientist, or engineer seems minimal–all the work happens in the AI software.
DP: But is that an illusion? Probably people felt the exact same way about cameras–too easy relative to painting! Even though at first it wasn’t easy at all, in that developing the film was messy, expensive, and time-consuming.
CS: So we’re kind of converging on the idea that prompt engineers in 2023 are like the first photographers back in the 1800s. Maybe the skill and the training required to be really good at it will start to look like the training and skill required in the 2020s to be really good at photography?
EA: OK, I’ll try to accept that!
CS: Woudenberg goes on to make the case that humans still have reserved powers. In particular, he thinks critical thinking is still solely the domain of humans:
AI computes, humans think. When humans think, they ask questions because they are curious. AI only works with what they have and asks for no more.
This is an important distinction that often goes overlooked. If you ask ChatGPT a question, it will respond and churn out an answer. To get it to ask for more information, you have to tell it to ask for more information which then becomes a separate sequence of activities. It’s not actually asking you for more information but more of a ‘call and response.’ It’s not curious and it’s never confused.
Woudenberg on Polymathic Being
DP: Well it sure does look like the AIs are thinking. When that ChatGPT response comes back, it feels like you’re talking to a thinking being–a human.
EA: But it is an illusion. Keep that metaphor you mentioned–
CS: ‘Autocomplete at the level of an essay’?
EA: –yeah, that autocomplete idea, in your head and you won’t be so caught up in the anthropomorphizing of the Chat bot in front of you.
DP: Which is what the LLM designers want you to feel! They want you wowed, they want that new-tech bias so you keep coming back, you expand your use, and you spread the good news.
CS: But one problem with sort of adopting Woudenberg’s positive stance is that these AI systems make a lot of mistakes and produce a lot of crap, as we’ve seen and shown here on the CSP Blog. I guess it is one thing if we use them for artistic or, say, low-stakes activities like planning a birthday party or goofing with writing:

But when novices [newbies] use it like a search engine or an interactive version of Wikipedia, things are much more serious and we could be doing damage to ourselves.
EA: Right, when I ask ChatGPT about something I know well, I see the errors easily. But if I asked it about something I am ignorant about, in an attempt to become less ignorant (like quantum computing), I may very well end up even more ignorant.
DP: Or worse, misinformed!
EA: Yes, exactly. I can see how ChatGPT can push people backward in their intellectual development if used in many of the touted ways.
CS: Alright, so Woudenberg is pretty optimistic about our ability to do things that all these AIs can’t do AND about our ability to harness them properly–things can only get better for humans, and I think he would agree with us that humans are still needed for things like creative signal-processing algorithm development, problem-solving, debugging, and making new math.
Let’s switch to another favorite critic: Freddie DeBoer. Freddie is more interested in analyzing and complaining about (it that so-entertaining and well-written way he has) The Hype. Which is kinda my thing too.
EA: No duh.
DP: And how.
CS: I think I saw that “Giant Autocomplete” metaphor in Freddie’s work, by the way. In an attempt to explain why he thinks the hype is way over the top, he looks at a classic weakness of natural-language processing systems: The Winograd dilemma. This is the dilemma of determining the antecedent of an ambiguous pronoun.
DP: Huh? Wazzat?
EA: Oh Dan. Come on!
CS: Let’s just give Freddie’s examples and things will be clear to us humans Dan.
The ball broke the table because it was made of concrete.
The ball broke the table because it was made of cardboard.
DP: Ah, so we have to identify what “it” refers to–either the ball or the table, right?
EA: Right.
CS: Right. Do you find it easy?
EA: Sure. In the first sentence, “it” refers to the ball, and in the second “it” refers to the table.
DP: But how is that so easy for us?
CS: Well, Freddie’s answer is just that we know, and have internalized, a lot of real-world facts and notions about all manner of both balls and tables. We know that a concrete table is very hard to break with any ball, so we just quickly “know” that the “it” must be the table.
EA: Similarly, we know that any table made of cardboard is a weak table indeed and could be broken by all kinds of things–generally not a great material for a table.
CS: Freddie explains:
These two sentences are grammatically identical and differ only by the material specified. And yet 99 out of 100 human beings will say that, in the first sentence, “it” refers to the ball, while in the second, “it” refers to the table. Why? Because concrete tables don’t break if you drop balls on them, and balls don’t break tables if they (the balls) are made out of cardboard. In other words, we can coindex these pronouns because we have a theory of the world – we have a sense of how the universe functions that informs our linguistic parsing. And this, fundamentally, is a key difference between human intelligence and a large language model. ChatGPT might get the coindexing right for any given set of sentences, depending on what response its model finds more quantitatively probable. But it won’t do so consistently, and even if it does, it’s not doing so because it has a mechanistic, cause-and-effect model of the world the way that you and I do.
CS: A more difficult example from Freddie is the following:
The committee denied the group a parade permit because they advocated violence.
The committee denied the group a parade permit because they feared violence.
CS: Here we want to know what the word “they” refers to; “they” is the ambiguous pronoun. What is its antecedent?
EA: Yeah, I see that this is tougher because the involved nouns are more abstract that balls and tables. But still, for us puny humans, its easy: In the first sentence, “they” refers to the group and in the second it refers to the committee.
CS: Yes, and it appears ChatGPT gets this one right–it is cannonical and it is highly likely that it appears in the training corpus. Unfamiliar ones cause ChatGPT to fail, like the ball and table one. It isn’t as if ChatGPT is steadily building up a model of the world; it is merely increasing its training corpus by using us (all of its users). It is saying “OK, yeah, I heard that one before… let me autocomplete for ya.”
DP: Well, let’s just program in some knowledge of the world and then ChatGPT will be right there with us on the Winograd dilemma. Right?
EA: But I think, Dan, that’s the long-term problem with AI systems based on a catalog of facts or a massive set of rules: We just can’t cram all the stuff into our programs. That’s why, in fact, supervised-learning-based machine learning has been so ascendant in the twenty-first century: all the previous-era failures of rule- and fact-based systems.
CS: And now the pendulum appears to have swung much too far away from AI systems that have, somehow, built-in knowledge or models of the real physical world. Which brings us, of course, to Gary Marcus.
EA: Ah yes, the current Cassandra of artificial intelligence.
DP: Wet blanket. Party pooper. Naysayer. Prophet of Doom! Which are all the things I like about him!
CS: Gary’s basic problem with the AI and ML community is the huge hype and the heavy disdain for building in world models/facts, but lately, since ChatGPT, he is concerned with bad actors using the rushed-to-market tools for all kinds of nefarious ends.
EA: And he’s probably right to be concerned–we already know there are a large number of people out there that will use any technology they can get their hands on to separate you from your money.
DP: And others that use it to push your beliefs around and to mess with your ability to tell truth from fiction. I definitely worry about my elderly parents!
CS: He signed that original letter of concern about the dangers–
EA: That one-sentence letter?
CS: –no, the longer one in March 2023 [link], not the one-sentence one associated with Hinton that came out later [link]. I like parts of that letter because they echo my own thoughts and words (Why do we want any of this?):
Contemporary AI systems are now becoming human-competitive at general tasks,[3] and we must ask ourselves: Should we let machines flood our information channels with propaganda and untruth? Should we automate away all the jobs, including the fulfilling ones? Should we develop nonhuman minds that might eventually outnumber, outsmart, obsolete and replace us? Should we risk loss of control of our civilization?
https://futureoflife.org/open-letter/pause-giant-ai-experiments/
CS: And then later he put a couple slides from his talks on his substack summarizing the two paths we can take regarding regulating–
DP: or attempting to anyway
CS: –highly capable natural-language processors, large-language models, generative-AI image producers, etc. Here they are:

CS: The question for you two is: do you think we can avoid the Bleak Future? Can we–should we–regulate these powerful AI tools, like we regulate the airwaves, the phone system, pharmaceuticals, common carriers, etc.?
EA: I suppose it is interesting to ponder whether we should regulate AI products or AI research, and what that regulation would look like, but it seems to me the more important question is: Can we regulate AI? Is it even possible? Is the cat fully out of the bag already?
DP: I don’t think we can regulate AI research and development. It can be done with relatively little in the way of capital investments, unlike, say, developing a new antibiotic. Some dude in his basement can create all kinds of AI models and systems with relatively inexpensive hardware and software. So small companies can too. We might be able to regulate the appearance of AI systems in markets or on major websites. Maybe. Kind of like regulating homeopathic products or food supplements–they aren’t allowed on the market until they are checked and found to be benign. But the regulators don’t reach into the food-supplement labs much. They focus on the point of sale.
EA: Yeah, the cat is out of the bag. I think maybe only a social force can work to slow or improve the situation. Going back to those hard questions of that original “temporary halt” letter: Should we be doing this work?
CS: Alright engineers, we’ve arrived at our final topic: fairness.
DP: Are AI or ML systems fair? You mean are they biased? Like in facial recognition systems and the like?
CS: No, I mean do the companies that create and train these massive language models operate fairly in the world.
EA: Is it fair of them to scour the internet for human-created texts and then use them for profit, effectively cutting off the original creators from their audience?
CS: Yeah. That.
EA: Well I did hear that OpenAI is now being sued for copyright infringement.
CS: Yes, by a couple authors. The crux of the matter is whether or not grabbing copyrighted material, en masse, from sources on the internet and then using that material as training inputs for large language models is “fair use,” which is a copyright-law concept. Here is an explanation from the Copyright Alliance:

That fourth item seems key. I recently asked ChatGPT if it knew about the Cyclostationary Signal Processing Blog, and it rather sorrowfully said no, but added that it doesn’t know anything past 2018 (Ouch: CSPB birthdate is 2015). But it will, perhaps, eventually get around to scraping–I mean copying wholesale–my content. And when that happens, and engineers ask ChatGPT about CSP, it might be able to answer using whole intact paragraphs or even some of my essays or equations. Whither the CSP Blog then?
EA: Done for, I presume. Overcome by events. Deprecated.
DP: Snuffed. Annihilated. Toast. Term–
CS: OK, OK. Jeez guys…
EA: And if a Google search for something about CSP ends up showing a bunch of links to AIs like ChatGPT, and then, like, your Blog is the 73rd link, nobody will show up to your Blog anymore. Sorry Chad. RIP CSPB.
CS: Yeah. That’s what I was thinking too. But every one of my posts has a copyright notice! How can they get away with this?
DP: Money talks? Also, the new-technology bias at work in, well, just about everybody? “You’re just mad and crying because you’re being left behind by this glorious new tech, which we really love. Really. Love. It. Get used to it! Happens to all of us.”
CS: I could rush to convert the CSP Blog to a subscription-only website, locking it up, effectively, before the OpenAI scraper-bots get their hands, er, claws, uh, virtual articulated grasping units (VAGUs) on it.
EA: But a lot of the ground we covered earlier in the interview leads me to believe there is still a role for you, your posts, and most especially the back-and-forth commenting sessions you have with your readers. I think ChatGPT is a long, long way from that kind of expertise–it still doesn’t understand how to do the things it says it can do, like debugging, code completion, creative solution-finding, etc., in the context of signal processing anyway.
CS: So, are we agreed then? The world still needs human signal processors?
DP: Yup, agreed. At least for a while yet. Hopefully I’ll be dead before we become obsolete. I don’t mind being both dead and obsolete.
EA: Agreed. We are still needed. But … we might do well to study prompt engineering on the sly.
CS: Well, that’s the end of the interview. Thanks so much for your time and energy. I really appreciate it, and I’ve enjoyed our conversation. Let’s go get a drink!
EA: Me too, Chad, lotta fun. Might I suggest you get the “other side” and interview our colleagues Leo Martello and Mary Brevectus?
CS: I’ll consider it!
Interview Biographies

Dan Peritum is an expert on signal processing for communications, communications standards, and demodulation techniques for a wide variety of terrestrial and satellite modulation types. He holds a PhD in Electrical Engineering from the University of Felpersham, UK.

Eunice Akamai has twenty years of experience with statistical signal processing and algorithm design. Her primary technical interests are compressive sensing, fractional-order transforms, array processing for direction-finding, and the theory of non-stationary random processes. She earned a PhD in Applied Mathematics from Ivy University.
The day I published this post Freddie DeBoer posted another excellent and thought-provoking reflection on AI in contemporary societies. https://substack.com/inbox/post/132367082
* * *
Obviously ChatGPT could not help with any of the signal-processing tasks I laid out for it, but my real disappointment was with Dall-E, which I used for some of the figures. I used about 50 “Dall-E Credits,” which produces 200 images. Compared to what you see in the hype literature/ads, the quality was quite poor. I’m not convinced better prompt engineering would have led to a better set of images… I have another blog (totally unrelated) and I’m planning to try Midjourney for image generation there. We’ll see.