Understanding and Using the Statistics of Communication Signals
A Challenge for the Machine Learners
The machine-learning modulation-recognition community consistently claims vastly superior performance to anything that has come before. Let’s test that.
Update September 2023: A randomization flaw has been found and fixed for CSPB.ML.2018, resulting in CSPB.ML.2018R2. Use that one going forward.
Update February 2023: A third dataset has been posted here. This new dataset, CSPB.ML.2023, features cochannel signals.
Update April 2022: I’ve also posted a second dataset here. This new dataset is similar to the original ML Challenge dataset except the random variable representing the carrier frequency offset has a slightly different distribution.
If you refer to any of the posted datasets in a published paper, please use the following designators, which I am also using in papers I’m attempting to publish:
I’ve decided to post the data set I discuss here to the CSP Blog for all interested parties to use. See the new post on the Data Set. If you do use it, please let me and the CSP Blog readers know how you fared with your experiments in the Comments section of either post. Thanks!
A while back I was working with some machine-learning researchers on the problem of carrier-frequency-offset (CFO) estimation. The CFO is the residual carrier frequency exhibited by an imperfectly downconverted radio-frequency signal. I’ll describe it in more detail below. The idea behind the collaboration was to find the SNR, SINR, block-length, etc., ranges for which machine-learning algorithms outperform more traditional approaches, such as those involving exploitation of cyclostationarity. If we’re going to get rid of the feature-based approaches used by experts, then we’d better make sure that the machines can do at least as well as those approaches for the problems typically considered by the experts.
Well, the collaboration fizzled out after I produced my current best-effort results using CSP. I still don’t know how well my erstwhile collaborators can do on the CFO problem. (This has now happened with a different researcher as well.) But I’ve got a Blog with decent reach and readership, so maybe somebody else will pick up the challenge.
Problem Definition
Given a complex-valued data sequence , , that contains a single digitally modulated signal taken from a finite set of modulation types , find the modulation type, symbol/bit rate, and carrier-frequency offset. That is, the data to be processed is given by
where is white Gaussian noise that is independent of , which is a digital signal drawn from the modulation-type set . The signal consists of the complex-valued baseband signal (having zero carrier-frequency offset) multiplied by a complex sine wave that represents the offset:
For example, for the eight signals below except -DQPSK and MSK, the complex-baseband signal is a complex-valued pulse-amplitude-modulated signal:
where the random variables represent the transmitted symbols (taken from the modulation’s constellation set), is the symbol rate, is the square-root raised-cosine pulse with roll-off parameter , is the symbol-clock phase, and controls the overall power level of the signal. The constellation-set values are chosen so that the expected value of is unity.
The modulation types determine the basic way that message bits are combined with pulse trains and frequency shifters to create a signal suitable for transmission over a propagation medium. To be more specific, let’s use and the following set of modulation types:
The definitions of the constellations I use here can be found in my post on the cyclostationarity of digital QAM/PSK. The MSK signal is equivalent to staggered QPSK with half-period-cosine pulses. The -DQPSK (also called pi/4-QPSK) signal is a QPSK signal that changes its constellation each symbol interval, alternating between one four-point constellation and a version of that constellation shifted by radians.
Let’s agree to use normalized frequencies and times here, so the sampling rate is unity. To reflect a realistic situation, we’ll also assume that the carrier-frequency offset is small compared to the signal bandwidth, which is itself roughly equal to the symbol rate; the occupied signal bandwidth varies for a fixed symbol rate due to variable pulse-function roll-offs.
How well can any given algorithm or machine estimate these parameters and make modulation-type decisions? To answer that, I created a very large number of instances of the signals. The symbol rate, carrier-offset frequency, power level, message bits, and roll-off parameter are varied as the signals are generated and stored. This is similar to the publicly available RML data sets, one of which I analyze in detail in this post.
My data set is described in a little more detail next.
Symbol Rates
The symbol interval varies from about (two samples per symbol) to about . The values for are not constrained to the integers in that range. Through the use of resampling techniques I can create any I wish to. But do realize that in this experiment, and in all the work on the CSP Blog, there is never any requirement on the relationship between the sampling rate and the symbol rate.
Carrier-Frequency Offsets
The carrier-frequency offsets are applied to the complex-baseband signals by multiplying by a complex sine wave, as in (2) above. The value of the offset lies in the range , so even for the smallest bandwidth of about , the largest offset is still a small fraction of the bandwidth. The offset is generated as a random number with a uniform distribution on , so no particular offset is favored.
Excess Bandwidths
I allow the roll-off parameter in the square-root raised-cosine pulse to be any number in the interval . Real-world signals typically use something in the range . This is important because my method of recognizing the modulation type depends on the roll-off (which controls the excess bandwidth of the observed signal). Although I’m allowing a huge number of possible roll-offs in the generation of the signal set, the recognizer only contains classification features for roll-offs equal to and also . So, strictly speaking, there are a great many signals that are not perfectly recognizable by my CSP approach (more on that below).
Message Sequences
Each signal is generated using a randomly chosen message sequence that uses symbols that are identically distributed and independent.
Power Levels
The power level of the signal is randomly varied over the generated signal set. The effect is that the inband SNR varies from about dB to about dB, with the bulk of the inband SNR values near dB.
Signal Length
Each signal has a length of samples. I consider block lengths of for when I apply my modulation recognition algorithm.
Number of Trials
I’ve generated over realizations of each of the eight signal types, but in the results presented in this post, I analyze only per type.
Propagation Channel
There are no channel effects applied to the generated signals except the presence of additive white Gaussian noise .
The Multiple-Signal Scene Analyzer
I analyze each data file in a blind fashion using an algorithm I call the multiple-signal scene analyzer (MSSA). The core of this approach to modulation classification is described mathematically in My Papers [25,26,28]. The modulation classification part is generally accomplished using cyclic-cumulant matching, and parameters such as symbol rate and carrier-frequency offset are estimated using the spectral correlation function and cyclic cumulants (cyclic temporal cumulant functions). Simpler estimators of the symbol rate and carrier-frequency offset parameters involve a nonlinearity (squarer or quadrupler) followed by Fourier analysis (The Literature [R100]). The MSSA’s estimators are similar in nature, but since they can take advantage of multiple th-order cycle frequencies that are related to the symbol rate and/or carrier-frequency offset, there is also an averaging gain to be had. So I’m asserting that the MSSA is a good example of an approach that uses “expertly crafted features” or “hand-crafted features” in the parlance of some of the Machine Learners.
I used the MSSA to do blind modulation classification in the DySPAN 2017 paper (My Papers [44]), but in that case I also used a blind constellation analyzer to boost performance for the hardest cases (for example, 64QAM vs 256QAM). In this post, I do not employ any constellation-analysis to boost performance.
The MSSA employs a default catalog of known signal types that is quite a bit larger than the set of eight modulation types listed above. (For example, it contains multiple amplitude-and-phase-shift-keyed signals, GMSK, a variety of continuous phase modulation types, AM, FM, DSSS, other non-square QAM, etc.) The catalog for this post is restricted to the eight types above. However, the MSSA is also allowed to output the FM, DSSS BPSK, DSSS QAM, and UNKNOWN decision types.
Key MSSA parameters for this experiment are the maximum cyclic-cumulant parameter and the use of an automatic spectral segmentation algorithm (blind band-of-interest detector) to preprocess the data. The maximum order of means that the classification feature is a set of cyclic temporal cumulant magnitudes for orders (My Papers [25,26,28]). The use of the blind spectral segmentation algorithm allows the cyclic-cumulant process to operate on data that has out-of-band noise removed.
MSSA Results
Since the main goal here is to compare “expert” carrier-frequency offset estimators with Machine-Learning estimators, let’s start with the offset results. The following graph shows the mean absolute error (MAE) in the offset estimate as a function of modulation type and block length :
Figure 1. Performance of the carrier frequency offset estimator embedded in the modulation-classification system used at the CSP Blog. These results are for the posted Challenge data set.
The graph shows the MAE for each input signal type regardless of whether or not the signal is correctly classified. For each block length I also plot the value of the reciprocal of the processing block length () as a reference. This is because a basic FFT-based approach to sine-wave frequency estimation will have a resolution that is approximately .
Once the block length exceeds a threshold, here about , the carrier-frequency offset MAE is better than except for 8PSK. For the other seven signals, the MSSA uses either second-order statistics (spectral correlation), fourth-order statistics (cyclic cumulants) or both to determine the offset. Continuing with that notion, 8PSK requires a minimum of an eighth-order nonlinearity prior to Fourier analysis to determine a high-resolution (that is, error near ) estimate of the offset, and the MSSA doesn’t do that automatically. So the offset estimate for 8PSK is limited to the offset arising from spectral analysis and multi-resolution band-of-interest estimation, which is quite a coarse estimate relative to the cycle-frequency-based methods used for the other signals.
So the figure above is what the MSSA can do, today, against the data set I described. Remember that those curves subsume a large variety of symbol rates, carrier offsets, pulse roll-off factors, and SNRs!
Let’s look at the modulation-recognition performance for this data set. I want to show this so that any challengers know what to exceed, but also because the many roll-off factors used in the data set provides a way to see how the MSSA performance depends not only on the roll-off but on the combination of the signal type and the roll-off, something that we don’t usually attempt to quantify in the literature. That was a long-winded way of saying: Here is a slightly new look at the problem.
First, let’s look at the confusion matrices for the experiment as a whole. I’ll show one confusion matrix for each block length , starting with the smallest and ending with the largest:
Figure 2. Confusion matrix for all eight input signal types in the Challenge data set. Here the number of processed samples from each data file is restricted to 2048.Figure 3. Confusion matrix for all eight input signal types in the Challenge data set. Here the number of processed samples from each data file is restricted to 4096.Figure 4. Confusion matrix for all eight input signal types in the Challenge data set. Here the number of processed samples from each data file is restricted to 8192.Figure 5. Confusion matrix for all eight input signal types in the Challenge data set. Here the number of processed samples from each data file is restricted to 16384.Figure 6. Confusion matrix for all eight input signal types in the Challenge data set. Here the number of processed samples from each data file is the full data-file length of 32768.
We see that for the smaller values of , the MSSA simply doesn’t produce good features–the blind processing fails, and the most common decision is UNKNOWN. As the block length increases, the confusion between the signal types decreases. When we reach our (arbitrary) maximum of samples, there is little confusion about BPSK, QPSK, 8PSK, -DQPSK, and 16QAM. However, 64QAM and 256QAM are routinely confused for each other. This confusion is separate from the ability of the algorithm to accurately estimate the symbol rate and carrier-frequency offset–see the first figure in this post.
Note that a correct decision for the confusion matrices above does not require that the square-root raised-cosine pulse roll-off (excess bandwidth) parameter be accurately estimated. All that is required is that the basic modulation type of the decision matches that of the input. Also recall that the number of roll-off parameters represented in the inputs is much larger than the number represented in the MSSA’s catalog of known signal types. So these confusion matrices reveal that the MSSA is quite tolerant to mismatches in the roll-off parameter between reality and catalog.
But now let’s take a look at how well the MSSA does do at estimating the roll-off. In the following confusion matrices, I look at a single input type, say, BPSK or QPSK. I then separate the inputs into eleven classes, one for each of the roll-off parameters represented in the MSSA catalog. The input type label for each trial is determined by the minimum distance between the actual roll-off parameter used and the eleven roll-off parameters represented in the MSSA catalog.
First, let’s look at BPSK:
Figure 7. Confusion matrix for BPSK inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only BPSK signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 2048.Figure 8. Confusion matrix for BPSK inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only BPSK signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 4096.Figure 9. Confusion matrix for BPSK inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only BPSK signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 8192.Figure 10. Confusion matrix for BPSK inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only BPSK signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 16384.Figure 11. Confusion matrix for BPSK inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only BPSK signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is the full file length of 32768.
As we might expect, for the larger values of , the confusions between the different BPSK signals are between those with roll-off parameters that are adjacent in the list . This indicates that the influence of the roll-off on the cyclic-cumulant features is fairly strong (at least for BPSK), and that no matter which roll-off is used, the extracted cyclic-cumulant features are strong relative to their estimation noise.
Now let’s look at QPSK:
Figure 12. Confusion matrix for QPSK inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only QPSK signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 2048.Figure 13. Confusion matrix for QPSK inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only QPSK signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 4096.Figure 14. Confusion matrix for QPSK inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only QPSK signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 8192.Figure 15. Confusion matrix for QPSK inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only QPSK signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 16384.Figure 16. Confusion matrix for QPSK inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only QPSK signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is the full file length of 32768.
For QPSK we see a little more confusion, especially for the smallest and largest values of the roll-off parameter.
Finally, let’s look at 256QAM, which has the weakest cyclic-cumulant features (weak in the sense that the cyclic-cumulant magnitudes are smallest when all eight signals are constrained to exhibit unit power):
Figure 17. Confusion matrix for 256QAM inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only 256QAM signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 2048.Figure 18. Confusion matrix for 256QAM inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only 256QAM signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 4096.Figure 19. Confusion matrix for 256QAM inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only 256QAM signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 8192.Figure 20. Confusion matrix for 256QAM inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only 256QAM signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 16384.Figure 21. Confusion matrix for 256QAM inputs only. The inputs are sorted into bins containing similar square-root raised-cosine roll-off parameters. The catalog of known signal types contains only 256QAM signals with roll-off parameters equal to for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is the full data-file length of 32768.
Performance improves with increasing , but confusion is common between any two values of roll-off for 256QAM for all the values of considered. I interpret this to mean that the cyclic-cumulant features are weak in general, and the influence of the roll-off parameter on the features is swamped by estimation variance due to the additive noise and self noise. Eventually, with large enough , the performance would improve to near perfection, as is the case with the other modulations. It is just that the required value of for 256QAM will be larger than the required for the other modulations.
Obtaining the Data Set
I’ve not uploaded any data to the CSP Blog yet. Let me know in the Comments if you’re interested in obtaining the data for your own Machine Learning modulation recognition (signal classification) experiments. Once that happens, I’ll update this section of the post with instructions on how to obtain the data. See the Update at the top of the post for a link to the data set.
As always, I appreciate your patience and diligence in getting to the end of a post, and I would also appreciate any comments, corrections, or suggestions that you might want to place in the Comments section below.
Author: Chad Spooner
I'm a signal processing researcher specializing in cyclostationary signal processing (CSP) for communication signals. I hope to use this blog to help others with their cyclo-projects and to learn more about how CSP is being used and extended worldwide.
View all posts by Chad Spooner
18 thoughts on “A Challenge for the Machine Learners”
I am interested in obtaining the data set to evaluate an existing cyclostationary classifier and a Machine Learning adaption of that tool.
yeah, I’m interested in symbol error rate calculation at different SNR values using machine learning can u please provide the necessary steps in the data generation.
The data set that I’ve posted for the Machine Learning Challenge is not going to be useful for symbol-error or bit-error rate calculations because I didn’t save the symbol sequence for each of the thousands of signals I created. I only retained the basic parameters for each one, such as symbol rate, carrier offset, power, and of course the sampled data itself.
You could try to create your own set of PSK or QAM signals and retain the symbol sequences. I suppose then you could try to train your machine using the sampled data as input vectors and the true symbols as the labeled output. Kind of cool. Good luck!
The idea is to find the most likely number of clusters in the constellation plot. It isn’t completely unsupervised, because I hypothesize a sequence of cluster numbers that are powers of two. This is because all the ideal constellations will have a dyadic number of clusters–I don’t need to worry about finding the best set of clusters for, say, a cluster number of 13 because there isn’t any signal I’m interested in that has that many points in its constellation diagram.
The algorithm moves the different data elements from one cluster to another until a cluster quality metric, or cost, doesn’t change much. Then, the cluster number is estimated by looking at the cluster arrangement with minimum cost. Once I have that number, I can restrict the cyclic-cumulant classification catalog to include only signals with the estimated number of cluster points in their constellation.
Hello Chad,
I really agree with the need for good data sets. When I was preparing a paper with a coworker I found a very bad data set, where basically all the data where exactly the same, i.e. the same symbols, and only the SNR noise was different. ML was then learning the symbols…
I looked at your data set, and found the way very easily to read it in python, and to apply my neural network architecture to it without hyperparameters tunning 🙂 I am getting good results on 2048 samples long signals, and I am sending the learning process on longer. Tell me how you want us to share our performances.
I think basically two things are missing to really make this a machine learning (ML)-challenge :
– more data: 20,000 realizations are not enough, Would that be possible to get around 1M ? At least 100k ?
since these are simulations, they are free (more free than real data).
– you should split the data sets into four parts: training (70%), validation (10%), testing (10%), secret testing (10%).
where you would make the first three available and we could bentchmark performances on the testing one.
The last one would only be available to you and you could thus be able to see if the perfs someone claims are true using his code.
This would allow the community to move from basically only using RML-2016 or 2018 to your dataset.
Another aspect is that your confusion matrix has classes not present in the data set: “DSSS-BPSK”, “DSS-QAM”, “FM” and “UNKNOWN”. This is not really possible in ML, because a neural network needs to see some examples in order to be able to predict if it belongs to it or not. Similarly you can not ask a child if an animal is a horse or a zebra if it has never seen one or the other before.
For “unknown”, is that defined using an estimated confidence and setting a threshold with respect to a required true positive rate and a false positive rate ?
Thanks for checking out the CSP Blog and the ML Challenge Iondumas! Great to hear your suggestions and enthusiasm.
Tell me how you want us to share our performances.
I will contact you via email. In the end, it is up to you how/where to show your results, since I have released the data set into the wild. But I will try to influence you.
more data: 20,000 realizations are not enough, Would that be possible to get around 1M ? At least 100k ?
All these things are possible. I originally created 112000 realizations, and posted just the first 20000 to see if there would be any interest. The simulator is automated, so I can make as many more as I can justify storing.
you should split the data sets into four parts: training (70%), validation (10%), testing (10%), secret testing (10%).
where you would make the first three available and we could bentchmark performances on the testing one.
The last one would only be available to you and you could thus be able to see if the perfs someone claims are true using his code.
I purposely left the division of the data up to the ML researcher, but definitely intend to generate some private data for my own testing purposes. Can you elaborate on why I should mandate the particular division you suggest?
Another aspect is that your confusion matrix has classes not present in the data set: “DSSS-BPSK”, “DSS-QAM”, “FM” and “UNKNOWN”. This is not really possible in ML, because a neural network needs to see some examples in order to be able to predict if it belongs to it or not.
Agreed. We need to think about this, or at least I do. In some settings, a modulation recognition algorithm that did not have a “None of the Above” or “Unknown” decision might be OK. In most settings, I assert, it is not OK. You do not want to allow the system to output a signal-type label if the input is nothing like the signal with that label.
For “unknown”, is that defined using an estimated confidence and setting a threshold with respect to a required true positive rate and a false positive rate ?
Something like that, yes. When the confidence is low, “UNKNOWN” is output. But the way the confidence can be low varies due to errors that can occur at various points in the processing.
One of the main motivations for the ML Challenge was the problem of carrier-offset estimation. Are you also pursuing that?
> Can you elaborate on why I should mandate the particular division you suggest?
I think it is nice when the division is done by the organizer of the contest, this allows different ML devs to compare apples to apples and to train on the same data and the same amount of data. But it is up to you. A simple thing that could be done would be to add a last column in your ascii giving either “train”, “valid” and “test”. With something like a 70%, 15% and 15% split. This would allow to have a consistent leaderboard across devs.
> In most settings, I assert, it is not OK.
I agree with you coming from the realm of physics where a value without error bars are useless. But this statement for any algorithm to say “I am not sure” should be done on a true positive rate versus false positive rate, i.e. a receiver operating characteristic (ROC) curve or on a user defined required rate for both TPR and FPR.
Are the above mentioned methods enable CFO estimation which is much larger than the signal BW? I’ve been able to recover such CFOs through SCF computation, but only for BPSK modulation. For higher order PSK modulations I was not successful, as no significant peaks were observed. I have a hunch that this is because BPSK is a real valued constellation and is symmetric in its frequency response.
Hey Alex! Thanks for stopping by and leaving a comment.
Are the above mentioned methods enable CFO estimation which is much larger than the signal BW?
Yes, the CSP methods of CFO estimation do not require that the CFO is small compared to the signal bandwidth. The requirement is that the signal is appropriately sampled. There is no training involved in typical CSP-based CFO estimation, so we just need to be able to get at the appropriate cycle frequency.
For higher order PSK modulations I was not successful, as no significant peaks were observed. I have a hunch that this is because BPSK is a real valued constellation and is symmetric in its frequency response.
Could you please provide any insight on that?
Yes, the PSK and QAM signals with larger symmetric constellations do not exhibit conjugate cyclostationarity, which is the kind of cyclostationarity that is associated with the carrier offset. So we cannot use second-order cyclostationarity to obtain a high-precision estimate of a cycle frequency that is a simple function of the carrier. Symmetric “frequency response” is not required. We can still find the CFO for a BPSK, OOK, MSK, GMSK, or AM signal even if the signal is heavily distorted by a propagation channel, rendering its power spectrum (probably what you mean by “frequency response“) arbitrarily asymmetric.
Finally, you’ll notice that the CFO estimation performance I show for 8PSK is much worse than that for the other seven signal types. This is because 8PSK does not exhibit appropriate fourth-order or sixth-order cyclostationarity associated with the carrier. The first order for which a moment or cumulant exhibits periodicity associated with the CFO is eight, and so I usually don’t try to use eighth-order statistics to estimate the CFO. You can try, and if the SNR is high enough, and you have enough samples to process, you can do it. But mostly it is a poor estimator.

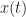
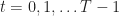

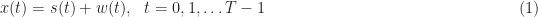
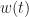
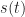


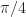


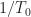
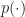
![\beta \in [0.1, 1.0]](https://s0.wp.com/latex.php?latex=%5Cbeta+%5Cin+%5B0.1%2C+1.0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
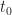

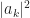
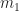
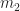




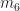

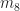
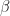
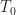
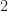

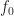
![[-0.001, 0.001]](https://s0.wp.com/latex.php?latex=%5B-0.001%2C+0.001%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
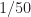
![[0.1, 1.0]](https://s0.wp.com/latex.php?latex=%5B0.1%2C+1.0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![[0.2, 0.5]](https://s0.wp.com/latex.php?latex=%5B0.2%2C+0.5%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
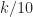


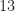
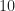


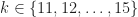

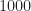

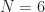
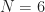



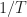
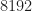





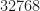

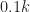 for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 2048.
for $k=1, 2, \ldots, 10$. Here the number of processed samples per file is restricted to 2048.



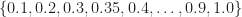










I am interested in obtaining the data set to evaluate an existing cyclostationary classifier and a Machine Learning adaption of that tool.
I am also interested in this dataset. Can you please provide me the links. Thanks in advance.
Hi,
I will appreciate that if you share the dataset.
Best regards,
Mohamed
yeah, I’m interested in symbol error rate calculation at different SNR values using machine learning can u please provide the necessary steps in the data generation.
Thanks for stopping by at the CSP Blog Draksham!
The data set that I’ve posted for the Machine Learning Challenge is not going to be useful for symbol-error or bit-error rate calculations because I didn’t save the symbol sequence for each of the thousands of signals I created. I only retained the basic parameters for each one, such as symbol rate, carrier offset, power, and of course the sampled data itself.
You could try to create your own set of PSK or QAM signals and retain the symbol sequences. I suppose then you could try to train your machine using the sampled data as input vectors and the true symbols as the labeled output. Kind of cool. Good luck!
Hi Chad,
Can you describe the blind constellation analyzer that you used to improve the results?
MS
The idea is to find the most likely number of clusters in the constellation plot. It isn’t completely unsupervised, because I hypothesize a sequence of cluster numbers that are powers of two. This is because all the ideal constellations will have a dyadic number of clusters–I don’t need to worry about finding the best set of clusters for, say, a cluster number of 13 because there isn’t any signal I’m interested in that has that many points in its constellation diagram.
The algorithm moves the different data elements from one cluster to another until a cluster quality metric, or cost, doesn’t change much. Then, the cluster number is estimated by looking at the cluster arrangement with minimum cost. Once I have that number, I can restrict the cyclic-cumulant classification catalog to include only signals with the estimated number of cluster points in their constellation.
All of that hinges on a sequence of estimates leading up to sampling at the correct instants. That includes carrier-offset estimation, symbol-rate estimation, symbol-clock-phase estimation, and pulse roll-off factor (EBW) estimation.
Hello Chad — thanks for this blog. Is your blind constellation analyzer based on a Dirichlet process?
Thanks for reading the Blog and commenting Kyle! I appreciate it.
But, no, it is not. I am not that smart.
Hello Chad,
I really agree with the need for good data sets. When I was preparing a paper with a coworker I found a very bad data set, where basically all the data where exactly the same, i.e. the same symbols, and only the SNR noise was different. ML was then learning the symbols…
I looked at your data set, and found the way very easily to read it in python, and to apply my neural network architecture to it without hyperparameters tunning 🙂 I am getting good results on 2048 samples long signals, and I am sending the learning process on longer. Tell me how you want us to share our performances.
I think basically two things are missing to really make this a machine learning (ML)-challenge :
– more data: 20,000 realizations are not enough, Would that be possible to get around 1M ? At least 100k ?
since these are simulations, they are free (more free than real data).
– you should split the data sets into four parts: training (70%), validation (10%), testing (10%), secret testing (10%).
where you would make the first three available and we could bentchmark performances on the testing one.
The last one would only be available to you and you could thus be able to see if the perfs someone claims are true using his code.
This would allow the community to move from basically only using RML-2016 or 2018 to your dataset.
Thanks for the work,
Another aspect is that your confusion matrix has classes not present in the data set: “DSSS-BPSK”, “DSS-QAM”, “FM” and “UNKNOWN”. This is not really possible in ML, because a neural network needs to see some examples in order to be able to predict if it belongs to it or not. Similarly you can not ask a child if an animal is a horse or a zebra if it has never seen one or the other before.
For “unknown”, is that defined using an estimated confidence and setting a threshold with respect to a required true positive rate and a false positive rate ?
Thanks for checking out the CSP Blog and the ML Challenge Iondumas! Great to hear your suggestions and enthusiasm.
I will contact you via email. In the end, it is up to you how/where to show your results, since I have released the data set into the wild. But I will try to influence you.
All these things are possible. I originally created 112000 realizations, and posted just the first 20000 to see if there would be any interest. The simulator is automated, so I can make as many more as I can justify storing.
I purposely left the division of the data up to the ML researcher, but definitely intend to generate some private data for my own testing purposes. Can you elaborate on why I should mandate the particular division you suggest?
Agreed. We need to think about this, or at least I do. In some settings, a modulation recognition algorithm that did not have a “None of the Above” or “Unknown” decision might be OK. In most settings, I assert, it is not OK. You do not want to allow the system to output a signal-type label if the input is nothing like the signal with that label.
Something like that, yes. When the confidence is low, “UNKNOWN” is output. But the way the confidence can be low varies due to errors that can occur at various points in the processing.
One of the main motivations for the ML Challenge was the problem of carrier-offset estimation. Are you also pursuing that?
Hello Chad,
> Can you elaborate on why I should mandate the particular division you suggest?
I think it is nice when the division is done by the organizer of the contest, this allows different ML devs to compare apples to apples and to train on the same data and the same amount of data. But it is up to you. A simple thing that could be done would be to add a last column in your ascii giving either “train”, “valid” and “test”. With something like a 70%, 15% and 15% split. This would allow to have a consistent leaderboard across devs.
> In most settings, I assert, it is not OK.
I agree with you coming from the realm of physics where a value without error bars are useless. But this statement for any algorithm to say “I am not sure” should be done on a true positive rate versus false positive rate, i.e. a receiver operating characteristic (ROC) curve or on a user defined required rate for both TPR and FPR.
Any comment on the issue of carrier-offset estimation?
See MP
Sorry for the acronym, I mean see my email
Dear Chad,
Are the above mentioned methods enable CFO estimation which is much larger than the signal BW? I’ve been able to recover such CFOs through SCF computation, but only for BPSK modulation. For higher order PSK modulations I was not successful, as no significant peaks were observed. I have a hunch that this is because BPSK is a real valued constellation and is symmetric in its frequency response.
Could you please provide any insight on that?
Thanks and Best Regards,
Alex
Hey Alex! Thanks for stopping by and leaving a comment.
Yes, the CSP methods of CFO estimation do not require that the CFO is small compared to the signal bandwidth. The requirement is that the signal is appropriately sampled. There is no training involved in typical CSP-based CFO estimation, so we just need to be able to get at the appropriate cycle frequency.
Yes, the PSK and QAM signals with larger symmetric constellations do not exhibit conjugate cyclostationarity, which is the kind of cyclostationarity that is associated with the carrier offset. So we cannot use second-order cyclostationarity to obtain a high-precision estimate of a cycle frequency that is a simple function of the carrier. Symmetric “frequency response” is not required. We can still find the CFO for a BPSK, OOK, MSK, GMSK, or AM signal even if the signal is heavily distorted by a propagation channel, rendering its power spectrum (probably what you mean by “frequency response“) arbitrarily asymmetric.
I discuss the CFO estimation issue for QPSK and the larger-alphabet PSK/QAM signals in the post on synchronization. Also relevant is the basic higher-order statistical structure of PSK and QAM, and how to estimate higher-order moments and cumulants.
Finally, you’ll notice that the CFO estimation performance I show for 8PSK is much worse than that for the other seven signal types. This is because 8PSK does not exhibit appropriate fourth-order or sixth-order cyclostationarity associated with the carrier. The first order for which a moment or cumulant exhibits periodicity associated with the CFO is eight, and so I usually don’t try to use eighth-order statistics to estimate the CFO. You can try, and if the SNR is high enough, and you have enough samples to process, you can do it. But mostly it is a poor estimator.
Hope this helps!