
I attended a conference on dynamic spectrum access in 2017 and participated in a session on automatic modulation recognition. The session was connected to a live competition within the conference where participants would attempt to apply their modulation-recognition system to signals transmitted in the conference center by the conference organizers. Like a grand modulation-recognition challenge but confined to the temporal, spectral, and spatial constraints imposed by the short-duration conference.
What I didn’t know going in was the level of frustration on the part of the machine-learner organizers regarding the seeming inability of signal-processing and machine-learning researchers to solve the radio-frequency scene analysis problem once and for all. The basic attitude was ‘if the image-processors can have the AlexNet image-recognition solution, and thereby abandon their decades-long attempt at developing serious mathematics-based image-processing theory and practice, why haven’t we solved the RFSA problem yet?’
The chief organizer went on to provide a potted history of modulation recognition research, name-checking me as having written one of the earliest papers (My Papers [17]) they were able to find. So, still at it, eh Spooner? Looks like we need some fresh ideas here, cuz you’re not getting it done.
I didn’t know it beforehand, but at that moment I realized I had sauntered into the lion’s den.
Now, I’m conflating modulation recognition with RFSA here, a bit, because most of the papers and research work over the years have addressed modulation recognition, whereas the challenge at the conference really was RFSA–multiple time-varying signals were to be transmitted across a bandwidth much wider than the bandwidth of any individual transmitted signal (I still have the data). The vast majority of published papers deal with a subproblem in RFSA called modulation recognition. RFSA is more than modulation recognition.
Half the challenge participants were machine learners and half signal processors. The challenge was poorly thought out and run, and there were so many problems with the transmission of the signals that nobody came out looking good. In fact, at conference close, the organizers did not announce a winner, or describe what happened, or mention the challenge at all. The organizers had vastly underestimated the difficulty of even their toy version of RFSA–which was completely under their control! Which brings us to the topic of the post: Why is RF scene analysis so difficult? Is it a wicked problem?
We know what RF scene analysis is, sort of, but what is a wicked problem? It is an interesting question because if RFSA is recognized as a peculiar problem, or some member of a known difficult-problem class, it would help people like the conference organizers, as well as all those in the machine-learning cult(ure), understand why progress is so slow and painful. And we all might become better researchers and problem-solvers (even us antiquated superannuated signal processors).
So what is a wicked problem? Let’s start where I often start, Wikipedia.
Wicked Problems
A wicked problem isn’t an evil problem–there’s no moral judgement of the problem’s nature. It is more like it is ‘wicked hard’ as they might say in Boston. The origin of the term and idea is in the area of social problems, the big problems of the world, such as poverty, homelessness, climate change, nuclear proliferation, etc., and in attempts at social (group) solutions to such problems. But it applies to other problems too.
The origin of the term is attributed to a pair of researchers Rittel and Webber (The Literature [R185]). The characteristics of the Rittel and Webber wicked problem are, according to Wikipedia, shown here in Figure 1.

Another researcher, J. Conklin, generalized the idea to problems outside of social and policy problems (The Literature [R186]). According to Wikipedia, Conklin’s defining characteristics are as shown in Figure 2.

The Wikipedia authors then go on to attribute further aspects to wicked problems, which are pertinent here at the CSP Blog. These are listed next:
- The solution depends on how the problem is framed and vice versa (i.e., the problem definition depends on the solution)
- Stakeholders have radically different world views and different frames for understanding the problem.
- The constraints that the problem is subject to and the resources needed to solve it change over time.
- The problem is never solved definitively.
These problem attributes are somewhat general and also confusing or subject to widely divergent interpretations. We won’t look at every one in detail. One of the key aspects seems to be the inability to clearly define the problem. Another is that there is no real way to figure out when you’ve solved the problem (no ‘stopping rule’). In the next section, we look at some of these key wicked-problem attributes in the context of the RF scene-analysis problem.
The RFSA Problem
There is no definitive formulation of a wicked problem. The solution depends on how the problem is framed and the problem definition depends on the solution. The problem is not understood until after the formulation of a solution.
Is there a definitive statement of the RFSA problem? Well, there is my formulation, which is ‘the cocktail party problem for radios.’ This formulation says we need to detect, characterize, geolocate, and classify all man-made RF signals in some particular frequency range. But what does characterize mean? What does all mean in all man-made signals? Does that include innocuous transients like garage-door openers? How weak is too weak to care about? 0 dB? -10 dB? -100 dB? What exactly is the frequency range? If we say there is a BPSK signal in the scene, is that enough? What about ‘a BPSK signal with square-root raised-cosine pulse-shaping function?’ Or ‘a BPSK signal with SRRC pulses and symbol rate of 250 kHz?’ Or ‘a BPSK signal with SRRC pulses, symbol rate of 250 kHz, carrier frequency of 790 MHz, symbol-clock phase of 10 
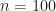
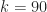
What is the set of all man-made signals? That is actually a moving target since new signals are invented and deployed nearly continuously, and the rate at which that happens has increased since the advent of commodity programmable radios like the Ettus SDRs.
Then there are more recent attempts at moving away from conventional formulations of the modulation-recognition problem and toward the modern problem of generic RF scene analysis such as The Literature [R187], which is rather weird due to the application of image-processing transformations to the RF domain. That is, their conception of RF scenes involves applying typical image-processing transformations to RF-scene spectrograms. The point is that what they think of as an RF scene is markedly different from what I do in my RFSA formulation and RF signal-processing projects.
That the solution modifies the problem is evident as well. ‘I’m going to use CSP.’ So I define my RFSA problem as one involving cyclostationary signals–I don’t care about analog single-sideband or analog FM (stationary signals) because I know my solution won’t work there.
Or ‘I’m going to train a massive convolutional neural network,’ so I define my RFSA problem as involving extremely short captured-data segments so that I can train in a reasonable time. This formulation completely rules out approaches like CSP and also severely limits the minimum SNR for successful processing because there is little averaging gain.
Or my RFSA problem is related to a fixed band of frequencies such as just the HF band 3-30 MHz (a hard problem in its own right).
So I think this aspect of a wicked problem is exhibited by RFSA.
Wicked problems have no stopping rule.
The interpretation of this wicked-problem aspect is that the wicked-problem solution doesn’t know when it has achieved success. For the RFSA problem, this is most clear in terms of minimum achievable SNR. OK, so you can successfully detect, recognize, and characterize signals down to -5 dB inband SNR. Are we done? Well, what about signals at -10 dB? OK, got those. Well, what about -20? Etc. How weak is weak enough? It never stops.
And when do we stop adding signal types to our feature catalogs or to our training datasets? Never. It doesn’t stop because new signals, new variants, and new parameter settings happen continuously as humans attempt to make better and better use of the RF spectrum and also to make heavier and heavier use thereof.
Solutions to wicked problems are not right or wrong, just better or worse.
This definitely fits RFSA and modulation-recognition where we must always deal with randomness, noise, and deviations from signal-model ideality. We are forced to evaluate performance in terms of probabilities, such as the probability of detection, probability of false alarm, and probability of correct classification. Moreover, the signal-parameter estimates are almost never ‘right’ (or ‘wrong’, really), they are simply more accurate (better) or less accurate (worse).
The constraints that the problem is subject to and the resources needed to solve it change over time.
There are many constraints on the RFSA problem. Some come from the poser, who demands, say, that any answer be produced not more than 
The world puts time-varying constraints on the problem by constantly introducing new signal types, by crowding frequency bands creating adjacent-channel interference, by shrinking reuse distances creating cochannel interference, but introducing new propagation channels due to new modes of transportation or new kinds of urban areas.
And the constraints imposed by available computing machinery change over time too-often rapidly. By the time you’ve got a solution based on multiple CPUs, signal-processing-ready GPUs are available that enable previously discarded computationally costly approaches tenable. Random-access memory that was expensive becomes cheap. Adequate radio receivers that used to cost a fortune become mass-produced commodities.
Every wicked problem is essentially novel and unique.
This aspect is not as easy to analyze for the RFSA problem. A lot of misdirected effort has been expended due to the widespread notion that the object-recognition problem in image processing is highly analogous to the modulation-recognition problem in signal processing. It is hard for me to put my finger on exactly why the analogy isn’t strong, but it has to do, I believe, with how the label is represented in the data.
Consider the image in Figure 3. The image-recognition problem is: What objects are in this image? Or perhaps: Is there a guitar in this image and if so draw a tight box around it. The image can be decomposed into an image with just the guitar pixels having non-zero values and an image with just the non-guitar pixels having non-zero values. The Blue Guitar image is then the sum of these images, which is the sum of a backgroundless guitar image with a background having a guitar-shaped hole in it. So in this sense the object to be recognized is an additive component of the data to be processed.

Our modulation-recognition problem is more like: Here is a vector of complex numbers. What is the modulation type of the signal in the vector? Every element of the vector contributes to the modulation type–there is no subpart of the vector that is the BPSK signal (I always circle back to BPSK on the CSP Blog). In terms of the analogy with the Blue Guitar, the modulation-recognition question is more like: What style of art is represented by this image? Or perhaps: Who painted this image? (Cubism. Picasso.)
Turning to Still Life by Picasso in Figure 4, we see four objects: a pitcher, a candlestick, a pot, and a tabletop. An image-recognition question would be: what objects are in this image? Draw boxes around them and produce their labels. Or: Is there a pot in this image?
The analogous RFSA problem is: What is this scene? And a good answer might be: Kitchen at night. Every pixel contributes to the answer, and object-recognition can play a role in helping answer the scene question, but object recognition alone doesn’t answer the holistic question.

So I think the RFSA problem is unique, although perhaps there is some other scene-based problem that is similar. In other writing, I’ve analogized RFSA to alternative kinds of scene analyses, such as acoustic, dramatic, and crime.
I think this lack of a strong analogy between MR/RFSA on one hand and image-recognition on the other is why convolutional neural networks are having a hard time definitively solving the MR/RFSA problem. We need different networks (and I’m actively working on that).
Stakeholders have radically different frames for understanding the problem.
My typical frame is that of the Star Trek tricorder (Spock’s, not Bones’). “Tell me everything you can about all radio-frequency signals using a single antenna and radio receiver.” So this is a generic kind of application and the focus is really on technology–how do we supply the answer?
Consumers of modulation recognition and RFSA, however, are often not focussed on the technology, but the utility of the answers. Even within the consumer set of stakeholders, there are wide differences in the frames. Cognitive-radio developers are looking for true spectrum holes and want badly to know about a relative few kinds of signals: Primaries primarily and Secondaries secondarily. Military types want to know about adversarial signals much more than they want to know about neutral or friendly signals, and their interest might dictate a different tradeoff between speed of answer and quality of answer relative to the cognitive-radio types. Other consumer stakeholders just want to know when something weird happens in the radio environment–so you have to rapidly understand the nominal RF scene, and then figure out if some subtle change happens after that, perhaps involving many GHz of bandwidth to search over and monitor closely.
I don’t know if these different frames for the RFSA problem qualify as radical, but they definitely differ and this causes a further splintering of the problem formulation and solution approach.
The problem is never solved definitively.
This aspect is somewhat redundant with some of the other aspects of a wicked problem. A completed modulation-recognition or RFSA system becomes obsolete quickly because new signals are deployed continuously and new, faster computational platforms are endlessly spun forth from the semiconductor industry. Additionally, if the deployed system can deal with signals down to, say, -10 dB SNR, well then what about those signals at -11 dB? The solution is never definitive because the signals are always evolving, the resources that can be brought to bear are always improving, there are always radio users that want to evade the latest system, and there are always edge cases that one wishes to do better at.
My answer to the titular question is yes. Fully general RF scene analysis is indeed a wicked problem. At the very least it has a lot of wickedness to it. Let me know if you disagree in the Comments.
Fantastic Post, I really enjoyed reading it !
If the model is large enough, I think
What do you mean by “model?” I only use that word once in the post, as in “deviations from model ideality,” meaning deviations from signal-model ideality. I know that machine learners often use the word model to mean their trained neural network. Can you elaborate?
Sorry, I accidentally pressed the Enter key. I mean “model” the weight of the nerual network(NN). If the model is large enough, maybe we could expect better result. Recent large model such as GPT and stable-diffusion shed some light on certain task like translating and painting. For the sub-problem of spectral segmentation in RFSA, I think NN is a potential method since object detection is well-developed in computer vision. (Sorry for the broken English). As an example, I polished the reply with chatGPT and the result is “I apologize for the accidental submission. What I meant to say was that we could potentially improve the results of our neural network by increasing its weight or size. Recent developments in large models, such as GPT and stable-diffusion, have demonstrated success in tasks such as translation and painting. I believe that neural networks could be a promising method for the sub-problem of spectral segmentation in RFSA, as object detection is a well-developed area in computer vision. Please excuse any mistakes in my English.” I think chatGPT show a better reply, sadly.
The downside of increasing the number of adjustable parameters in an artificial neural network is overfitting, which gives low error but leads to poor generalization.
I’m not dazzled by Chat GPT, which seems pretty crappy in terms of truth value but also it appears to me to be an example of “technology we shouldn’t want and don’t need.”
I’m not sure what increasing the neural-network model size has to do with whether RFSA is a wicked problem or how it is relevant to RFSA’s ‘degree of wickedness.’
See here for an analysis of a published attempt. I think the fundamental problem in spectral segmentation is that there is no single ‘image’ to use in an object-recognition system, ML or otherwise. One must use a family of spectral estimates indexed by resolution to solve the general problem. Maybe this could be done using a neural network, but you still have to perform the required signal processing to spoon-feed to the network, so why not just process it yourself? Moreover, I believe the particular family of spectral estimates needed to find accurate frequency-band estimates is data-dependent. That’s why my algorithm (My Papers [32]) is a recursive multi-resolution data-adaptive spectral segmenter.
I think most of the methods are still just a tool, and the complete signal analysis still relies on human experts to interpret it, just like deciphering a code.
Since multi-resolution spectral segmentation is such a big part of your approach to positive SNR signal detection and classification, how do you deal with positive SNR, but deeply faded signals?
For example, a simple BPSK signal has a true bandwidth of 10e6 hz, but you estimate 9.5e6. If you decide to channelize out a 9.5e6 segment and do a blind cyclic freq analysis (a la SSCA) you won’t find the true baudrate parameter that corresponds to the (critical) bandwidth of the signal.
At the same time, you might decide to assume that your BW estimate is noisy, so you decide to take a 9.5e6 + 10% slop on either side, which would get you the full signal bandwidth, but increase the probability of including pieces of nearby signals as well.
Welcome to the CSP Blog Michael! I appreciate the thoughtful comment, which is also a penetrating question.
The short answer is “not very well.” But I don’t think the main problem is the one you’ve outlined. The main problem isn’t detection of cycle frequencies, it is how to correctly identify the faded signal.
It might be worth looking at your numbers a bit more closely. I define several kinds of bandwidth in the sampling-theorem post, including occupied bandwidth, which is the bandwidth over which the theoretical signal possesses non-zero energy. I believe you are using “true bandwidth” here to mean occupied bandwidth. Let’s get more specific and assume your BPSK signal is of the square-root raised-cosine variety (practical), with filter rolloff of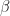 . Then the occupied bandwidth (your true bandwidth) is equal to
. Then the occupied bandwidth (your true bandwidth) is equal to  MHz, where
MHz, where  is the bit rate.
is the bit rate.
For a rolloff of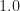 ,
,  MHz. For a rolloff of
MHz. For a rolloff of 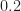 ,
,  MHz. And few signals use smaller
MHz. And few signals use smaller 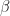 . So in almost all cases, if the detected band-of-interest (BOI) width is
. So in almost all cases, if the detected band-of-interest (BOI) width is 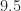 MHz, the BOI will have a width greatly in excess of what is needed to find the bit rate through CSP. And this is important to point out because practically speaking, channel filters typically do not “blank out” great swathes of frequencies, rendering the resulting signal stationary. What typically happens is that the signal is distorted, bearing an effective pulse that is
MHz, the BOI will have a width greatly in excess of what is needed to find the bit rate through CSP. And this is important to point out because practically speaking, channel filters typically do not “blank out” great swathes of frequencies, rendering the resulting signal stationary. What typically happens is that the signal is distorted, bearing an effective pulse that is 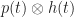 , where
, where  is the transmit pulse and
is the transmit pulse and 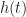 is the channel impulse response. The cyclic cumulants (and spectral correlation function) are affected in known ways by
is the channel impulse response. The cyclic cumulants (and spectral correlation function) are affected in known ways by 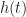 here, and the ideal cyclic-cumulant features used for classification can no longer match the estimated ones due to the randomness of
here, and the ideal cyclic-cumulant features used for classification can no longer match the estimated ones due to the randomness of 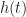 . But I’m actively working on a signal-processing algorithm that will jointly equalize and classify signals, even when there are multiple cochannel distorted signals at the input. Machine learners, on the other hand, recognize this problem and try to include appropriate
. But I’m actively working on a signal-processing algorithm that will jointly equalize and classify signals, even when there are multiple cochannel distorted signals at the input. Machine learners, on the other hand, recognize this problem and try to include appropriate 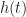 in their training sets (which I have praised in the past).
in their training sets (which I have praised in the past).
I call this “BOI Unshrinking” and I have a provision for it in my implementation of my automatic spectral segmentation algorithm. But I’m not sure your statement about increasing the probability of including nearby signals is correct–at least not if you are using a reasonable segmenter. For example, consider the modified signal scene from this comment:
The signals are, from negative frequency to positive, BPSK (250 kHz), QPSK (300 kHz), GMSK (187.5 kHz), 16QAM (272.7 kHz), and MSK (166.7 kHz). Here is the output of my segmenter for samples at the input:
samples at the input:
You can see this is relatively easy for the segmenter. If you wish to unshrink a BOI, you can examine the detected-BOI frequency intervals to see if unshrinking will include a nearby (strong) signal. For example, for the MSK signal, there is nothing detected to its positive-frequency side. The BPSK signal has a bit more room to unshrink than the others. Etc.
Of course, there could always be a signal lurking underneath the noise floor, but there could be a signal underneath the signal to be unshrunk just as well, and the presence of very weak signals can be determined by CSP only by using long input data records, whereas these strong signals can be successfully processed using much shorter signals. So it looks like there is a way around your conundrum.
Additionally, including pieces of adjacent signals might not harm your ability to detect the cycle frequencies of the signal at the center of the BOI, since those pieces are likely to be much smaller than the smallest (non-conjugate) cycle frequencies exhibited by those signals, unless they are special types like DSSS.
Buying what I’m selling?
Thank you for the detailed answer Chad.
This is an excellent point. I was incorrectly thinking about an hypothetical signal with perfect spectral efficiency, such that B = R. This almost never happens in practice though, so our spectral envelope would give us a bandwidth higher than the cyclic frequency of interest, alpha=R.
I didn’t consider this approach. Since we estimate the occupied-bois, we also know the empty-bois, so we don’t have to indiscriminately approximate excess bandwidth during unshrinking. Nice!
(hopefully my comment formatting is correct)
More from Conklin (The Literature [R186]):
[Now that you’ve pointed it out, its obvious.]
[Guilty]
[Sounds Familiar]
No, not my coherence! More later…