
ODU doctoral student John Snoap and I have a new paper on the convergence of cyclostationary signal processing, machine learning using trained neural networks, and RF modulation classification: My Papers [55] (arxiv.org link here).
Previously in My Papers [50-52, 54] we have shown that the (multitudinous!) neural networks in the literature that use I/Q data as input and perform modulation recognition (output a modulation-class label) are highly brittle. That is, they minimize the classification error, they converge, but they don’t generalize. A trained neural network generalizes well if it can maintain high classification performance even if some of the probability density functions for the data’s random variables differ from the training inputs (in the lab) relative to the application inputs (in the field). The problem is also called the dataset-shift problem or the domain-adaptation problem. Generalization is my preferred term because it is simpler and has a strong connection to the human equivalent: we can quite easily generalize our observations and conclusions from one dataset to another without massive retraining of our neural noggins. We can find the cat in the image even if it is upside-down and colored like a giraffe.
Since the unfortunate paper The Literature [R138], our research program has taken the following form:
- Are the RML datasets of high quality? Do they span a reasonable subset of digital modulation parameters? (Answers: No. See here, here, here, here and here.)
- Can a typical convolutional neural network outperform my CSP-based carrier-frequency-offset estimator? (Answer: No attempt I’ve seen comes close.)
- Can a typical convolutional neural network outperform a CSP-based modulation recognizer on the CSPB.ML.2018 and CSPB.ML.2022 datasets? (Answer: No CNN has, but capsule networks can.)
- Can a CNN or capsule network match the generalization ability of a CSP-based modulation recognizer using, say, CSPB.ML.2018 and CSPB.ML.2022? (Answer: With IQ inputs, no. With cyclic-cumulant inputs, yes.)
- Can we create a new type of neural network, with new types of layers, that can take IQ inputs and yet deliver the performance and generalization of the cyclic-cumulant-trained capsule networks? (Answer: As of Snoap’s MILCOM ’23 paper My Papers [55], and upcoming journal paper, yes.)
In other words, don’t use RML datasets, don’t use convolutional neural networks borrowed directly from image-processing successes, and don’t forget to include serious generalization tests in your machine-learning modulation-recognition work. And we’re bringing the receipts.
Here are some My Papers [55] teasers.
Here is the all-important Figure 1:

We use CSPB.ML.2018 and CSPB.ML.2022 to assess both classification performance and generalization ability. Recall that CSPB.ML.2022 is nearly identical to CSPB.ML.2018–the main difference is that the signals’ carrier-frequency offset parameters are governed by two different and non-overlapping uniform distributions. This gives rise to the following “trained on X, tested on Y” probability-of-correct-classification plots:

Now, since the submission of My Papers [55], we have made substantial progress on refining the novel-layer capsule networks. I don’t want to excerpt from that nearly complete, but not yet submitted, paper, but I can provide this basic view of the results:
| Inference Method | Trained On | Tested On | Classification Performance | Generalization Performance |
|---|---|---|---|---|
| CSP Blog CSP | 2018 | 2022 | 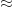 0.8 0.8 | High |
| CSP Blog CSP | 2022 | 2018 | 0.8 | High |
| IP Cap NN w/IQ | 2018 | 2022 | 0.4 | Low |
| IP Cap NN w/IQ | 2022 | 2018 | 0.6 | Med |
| IP Cap NN w/CC | 2018 | 2022 | 0.9 | High |
| IP Cap NN w/CC | 2022 | 2018 | 0.9 | High |
| New Cap NN w/IQ | 2018 | 2022 | 0.9 | High |
| New Cap NN w/IQ | 2022 | 2018 | 0.9 | High |
Why do the networks with the novel nonlinear layers outperform the image-processing networks, which largely feature convolution layers, when IQ data is at the network input? I think it is because the IQ data is not amenable to edge detection, and things like edge detection are the forte of convolutions. In fact, convolutional neural networks were inspired by the eye-brain system, which is well-known for its ability to recognize images quickly and efficiently. See for example The Literature [R191], which tries to explain how the convolutional neural networks came about in an engineering-history sense:

Turning to our IQ data from various radio signals, do we think the eye-brain model is appropriate or useful? Let’s take a look, literally. In Figure 4 I’ve plotted the IQ samples for three different digital QAM signals, each of which has eight points in their constellation: 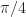

Compare those IQ plots with plots of the higher-order cyclic cumulants for the three signals (8QAM2 is another name for 8APSK), visualized in the style of the recent cyclic-cumulant gallery post, in Figures 5-7.

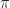 /4-DQPSK with square-root raised-cosine pulses having rolloff of 0.35.
/4-DQPSK with square-root raised-cosine pulses having rolloff of 0.35.

It is pretty easy to see the difference and tell which is which, just from looking at the pattern. So a neural network that is designed to ‘look’ like us will have no trouble either, and that is why we see such good classification performance and good generalization for the cyclic-cumulant-trained image-processing capsule networks.
Now, when Snoap uses his novel-layer IQ-input network, it doesn’t get fed the patterns in Figures 5-7. Instead, we force it to ‘see’ some proxies for those theoretical (and beautiful) patterns in Figures 5-7. In particular, we force it to see the Fourier transforms of the IQ samples raised to the powers of two, four, six, and eight. These contain sine waves related to the cyclic cumulants corresponding to 


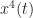 for each of the three eight-constellation-point signals shown in Figures 4-7. Notice that the three signals have three different patterns of generated spectral lines due to the fourth-order nonlinearity. This same kind of thing happens for the other nonlinearity orders as well, and the network ‘sees’ all of those patterns.
for each of the three eight-constellation-point signals shown in Figures 4-7. Notice that the three signals have three different patterns of generated spectral lines due to the fourth-order nonlinearity. This same kind of thing happens for the other nonlinearity orders as well, and the network ‘sees’ all of those patterns.The patterns in Figures 5-7 won’t change if we change the symbol rate or carrier offset, and they don’t change for different bit/symbol sequences, provided that they adhere to the independent and identically distributed assumption. The patterns in Figure 8 will change, somewhat, with changes in symbol rate and carrier offset. The spikes will move around, but their basic shapes–the relationships between the different spikes–will not change.
There is no escape from domain expertise. Maybe neural networks will be the basis for lots of our RF modulation-recognition tasks in the future, maybe not. But we can’t ignore the fundamental nature of the data we wish to classify and expect to do well no matter what approach we take.
Hi Chad,
congratulations on the accepted paper and thank you for keeping us updated about newest research from John and yourself.
Maybe you can answer a question (avoiding spoilers w.r.t. the upcoming journal paper of course) that came up when I’ve been reading the paper:
In the third paragraph of IV. you mention that your “blind band-of-interest (BOI) detector” is used to “…center the I/Q data at zero frequency”. How accurate is that BOI-detector when it comes to eliminating the CFO? Does the preprocessed signal still show a significant (larger than FFT resolution) CFO? In other words: Are the NNs seeing signals with spectral/cyclic features shifted by random CFOs? You point out below that this frequency correction is not solving the dataset-shift problem and show it by comparing with the second classifier (IP-CAP).
Any well-disposed CSP-blog reader is eager to understand whether cyclic (cumulant) features are superior to I/Q samples or whether both are needed at RFmodRec. The papers’ results may provide a further lead to answering that question:
In the sense of your “CSP Blog CSP” classifier, one could assume that cyclic cumulant features would be the meaningful features for modulation classification. Hence, I’d regard the branches 2,4,6,8 of the proposed CAP as important. It would be interesting to see an experiment in which the branches seeing the time-domain signals (1,3,5,7) were omitted and compare it to the full structure.
If the performance drops significantly, it would show that the NN can see something in the time-domain representation which I am not sure of what it is. What do you think?
Your preview of the journal paper let’s me guess that some questions are answered by the contained results. But probably some more are also raised. If so, I guess you won’t have to worry about the rating of it’s “novelty and originality”. 🙂
Cheers,
Andreas
Thank you Andreas.
We measure the BOI-detector-based carrier (center) frequency error in terms of mean absolute error (MAE), and this comes out to about 0.001 Hz (all frequencies here are normalized) for both data sets. We will include this information in the journal-paper submission.
Yes. We process 32,768 samples (that is the length of the signal files in CSPB.ML.2108 and CSPB.ML.2022–for much longer single-signal and two-cochannel-signal files see CSPB.ML.2023), and 1/32768 0.001. The MAE of the center frequency is approximately equal to the largest CFO in CSPB.ML.2018, since the CFOs there are uniform on [-0.001, 0.001]. Therefore, for CSPB.ML.2018, we aren’t doing a good job on removing the CFO. Since the CFOs are larger in CSPB.ML.2022, there is, on average, a shifting of the signal toward zero frequency for that dataset.
0.001. The MAE of the center frequency is approximately equal to the largest CFO in CSPB.ML.2018, since the CFOs there are uniform on [-0.001, 0.001]. Therefore, for CSPB.ML.2018, we aren’t doing a good job on removing the CFO. Since the CFOs are larger in CSPB.ML.2022, there is, on average, a shifting of the signal toward zero frequency for that dataset.
I think the answer is yes. We do not successfully remove the CFO every time. However, I believe the results indicate that the residual CFOs for CSPB.ML.2018 and CSPB.ML.2022 should be about the same in terms of their distribution.
Yes, I would like to see that experiment too. I think branches 2, 4, 6, and 8 are what I try to illustrate in Figure 8 of the post. Although these are plots of the Fourier transform of a nonlinear transformation of the data, they are more closely connected to the time-domain parameters of cyclostationarity than to the frequency-domain parameters (as you note). That is, the complex-valued strengths of the spikes are the cyclic temporal moments (impure sine-wave strengths). And so they are closely related to cyclic temporal cumulant strengths too, for reasons I’ve belabored on the CSP Blog (sorry). That’s why I call them a proxy for the cyclic cumulants in the post. So your question about the utility of the non-FFT branches 1, 3, 5, 7 is a good one. What do they add? What is their connection to my cyclic-cumulant-based modulation recognizer? One answer is that those sine-wave components that are so prominently visible in Figure 8 (and therefore in the FFT vectors in the NN) are also present in the odd-numbered branches, but there they are not visible as massive abrupt changes (spikes) in the vector, but as smoothly varying periodic functions in noise. So maybe that has value too to the neural network in its quest to differentiate between the signal types.
* * *
Overall, I view this paper (and the whole sequence with Snoap as the first author) as sketching a promising alternative approach to the use of neural networks rather than as some kind of definitive last word on the topic. If some researchers and practicing engineers come away thinking ‘hey, maybe I should try some layers that are appropriate for the RF data instead of relying solely on what the image-processors say,’ then the sequence of papers has done a great service to the engineering community. We have to remember that neural networks are just another optimizer in the optimization toolkit, and so like any optimization technique, we have to know how to apply it and under what conditions it will fail. We’re trying to open some eyes up to that point of view–eyes that are clouded by something akin to Thorin Oakenshield’s dragon sickness.
Hello Chad,
Thanks for the amazing work and Congratulation for the paper !
After some reading, I had some questions about the structure of the CNN branch layout:
– X and Y : I believe it corresponds to input dimensions, but I am not sure about this one.
– Activations : What do you mean by activations on layers like convolutions/BatchNorms (e.g : X × (Y · A/C) ) ?
Cheers,
Mehdi
Hi Mehdi,
Thanks for the kind words and the good questions!
The dimensions listed in the Activations column actually refer to the output dimensions (number of activations) from that layer. In many cases, this is the same as the input dimensions (e.g., for the very first “Input” layer, the input dimension is 32,768 x 2 and its output dimension, or number of activations, is also 32,768 x 2), but the number of activations does not always equal the input size; specifically, the Conv layer in Tables II and III, the Max Pool layer in Table II, and the Avg Pool layer in Table III have different output dimensions than they do input dimensions. It is easiest (for me) to show by working through the first ConvMaxPool layer listed in Table I.
The second layer listed in Table I (the first ConvMaxPool layer) lists the # Filters and Filter Size that would fill in variables A, B, and C in Table II. However, the Activations listed for the first ConvMaxPool layer in Table I correspond to the final Activation output dimension at the end of Table II because it is the output size. Working through Table II for this first ConvMaxPool layer, X and Y would come from the previous activation output size, so for the first ConvMaxPool layer, X would be 32,768 and Y would be 2. A would be 16, B would be 23, C would be 2, and you would end up with the following:
Input (16)[23 x 2] 32,768 x 2
Conv (16)[23 x 2] [1 x 1] 32,768 x 16
Batch Norm 32,768 x 16
ReLU 32,768 x 16
Max Pool (1)[1 X 2] [1 x 2] 16,384 x 16
For the second ConvMaxPool layer, you end up with the following:
Input (24)[23 x 16] 16,384 x 16
Conv (24)[23 x 16] [1 x 1] 16,384 x 24
Batch Norm 16,384 x 24
ReLU 16,384 x 24
Max Pool (1)[1 X 2] [1 x 2] 8,192 x 24
Does that make sense?
When I made the NNs in MATLAB, I didn’t have to specify anything for the activations/output sizes. I was able to just specify the initial input size, specify all the filter sizes, strides, etc.; and then MATLAB automatically calculated the downstream input/output sizes. I mainly provided this activation/output size information in the table to help others confirm they build the NN the same way I did (in case that is what they wanted).
If you ignore that “Activiations” column for now, are you still able to build the NN in whatever software suite you are using?
Now that I am thinking about it, I recall the input dimensions I actually used in MATLAB were 4-dimensional. Looking at my software, MATLAB is expecting a set of RGB images, it looks like the first 3 dimensions correspond to R-G-B of the given image, while the 4th-dimension indicates the index of the image in the training sequence.
In the MATLAB code, I combined all the inputs into a 4-dimensionsal variable of size 1 x 32768 x 2 x 112000, so that “Activations” column is quite a simplification of the output size too. In the tables, I drop the 4th index dimension, and I also dropped the first “R” dimension because it is always 1 (I never put any information into the first dimension, yet it had to exist for MATLAB).
Lots of info all at once, hopefully I haven’t confused you more. Let me know if you still have questions and I’ll do my best to get back to you.
Thank you,
John